
무려 한달도 안된 논문이다..!
제목이 내 연구를 없애려고 해서 위협느끼고 읽게된 논문이다!
내가 하고 있는 주제랑 너무 유사해서 못내게될까봐 무서워하며 읽기 시작해본다.(?)
해당 논문을 TCSVT 2024 Preprocessing Enhanced Image Compression for Machine Vision에 올라와있다🫠
Abstract
해당 논문에서는 Machine Vision Task를 위한 전처리 강화 이미지 압축 방법을 제안한다.
end-to-end 방법 대신 전통적인 non-differential codecs를 기반으로 구축하였으며, 대신에 성능 최적화를 위해 proxy network를 도입하였다.
encoder이전에 유용한 정보를 유지하고 bit rate 절약을 위해 관련 없는 정보를 억제하는 신경망 전처리 모듈을 제안한다.
결과적으로 해당 방법이 약 20%의 bit rate를 절약하면서 coding bitrate와 downstream machine vision tasks의 성능 간의 더 나은 균형을 이룬다고 한다.
I. INTRODUCTION
몇년간 이미지들이 카메라와 같은 전방 장치에서 캡처되어 클라우드 서버와 같은 후방 장치로 전송되어 기계 분석을 수행하고 있다.
이에 Downstream machine vision task의 성능을 유지하면서 전송 bitrate를 줄이는 방법이 이미지 압축 분야에서 도전 과제로 남아있다.
그러나 학습된 이미지 코덱의 계산 복잡도는 보통 높고 표준화가 되지 않았다.
이에 해당 논문에서는 전통적인 codec앞에 신경망 전처리 (NPP) 모듈을 제안하여 입력 이미지를 인코딩 전에 필터링하고 Vision task를 수행한다.
제안된 전처리 모듈은 의미 있는 정보를 유지하고, machine vision task에 불필요한 정보를 줄이도록 최적화한다.
end-to-end 최적화를 가능하게 하기위해 비미분 이미지 codec을 위한 proxy network를 훈련 단계에 도입하며, 여기서 proxy network의 gradient가 신경망 전처리 모듈로 전파된다.
게다가 제안된 신경망 전처리 모듈은 양자화 적응형이며, 다양한 압축 비율의 전통적인 codec에 통합될 수 있다.

해당 논문의 기여에 대한 요약을 아래와 같이 제시하였다.
- 전통적인 codec을 기반으로, 필터링된 이미지를 생성하기 위한 신경망 전처리 모듈을 제안
- 학습된 proxy network를 도입하여 훈련 단계에서 전통적인 codec을 근사화하고 gradient 전파를 수행
- 특정 시나리오에 최적화된 NPP 모델이 다른 codec, downstream backbone, 또는 다른 작업에서도 사용 가능
II. RELATED WORKS
A. Image Compression
학습 기반 이미지 압축 방법이 인기를 끌고 있다.
이 방법들이 더 나은 압축 성능을 달성했음에도 불구하고, 통합된 코딩 표준이 없어 대규모 실용 응용 프로그램의 배포가 더 어렵다.
B. Image Compression for Machine Vision
대부분의 기존 이미지 압축 방법은 인간 시각 시스템의 관점에서 재구성 왜곡을 줄이는 것을 목표로 하며, PSNR과 같은 pixel 기반 metrics를 기준으로 최적화한다.
또한 여러 연구들이 압축된 특성을 직접적으로 vision task를 지원하는데 사용하는 것에 중점을 두기도 했다.
예를 들어 학습 기반 이미지 codec이 생성한 압축된 표현을 활용하여 vision task를 수행하는 방법이 있다.
이들 대부분의 작업들은 end-to-end 최적화를 가능하게 하기 위해 학습 기반 codec에 의존해야 하며, 이는 전통적인 codec을 사용하는 현실에서는 실제 응용에서 실행되지 못할 수도 있다.
이에 해당 논문에서는 전통적인 codec을 기반으로 하며 proxy network를 통해 end-to-end 최적화를 가능하게 한다.
C. Preprocessing
여러 연구에서 이미지 및 비디오 압축 알고리즘의 성능을 개선하기 위해 전처리 기술을 사용하는 여러 방법이 제안되었다.
여기서도 여러 학습 기반 전처리 방법도 제안되었다.
예를 들어 학습 기반 codec의 bit rate estimator를 차용하여 JPEG과 같은 전통적인 Codec의 지각 품질을 향상시키는 방법도 있다.
이에 해당 논문에서는 인간 시각 시스템 대신 Machine vision에서 압축 성능을 향상시키기 위해 신경망 기반 전처리 방법을 사용할 것을 제안한다.
III. PROPOSED METHOD
A. Overview
전체 시스템은 coding bit rate와 machine analysis task의 성능 간의 더 나은 균형을 달성하는 것을 목표로 한다.
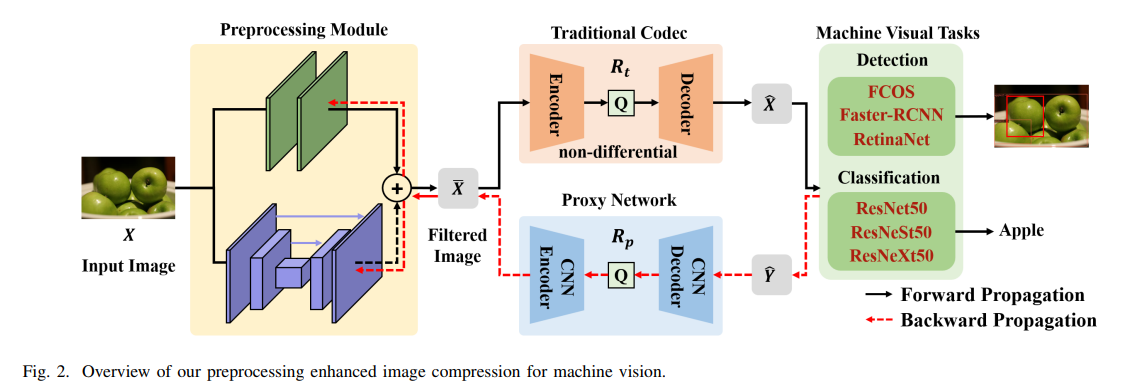
전체 로직은 아래의 이미지와 같다.
-
입력 이미지 X를 신경망 전처리 모듈(NPP)에 입력하여 비선형 변환을 수행하고, 중요한 의미 정보를 유지하는 필터링된 이미지 X¯를 생성한다.
-
X¯를 BPG와 같은 전통적인 코덱으로 인코딩하고 재구성한다.
-
디코딩된 X¯를 Machine vision task 네트워크에 입력하여 결과를 출력한다.
이때 전통적인 코덱이 미분가능하지 않을 수 있기 때문에 end-to-end 최적화를 할 수 없을 수 있다.
이에 해당 논문에서는 학습된 image compression network를 전통적인 codec의 proxy network로 도입하고, proxy network의 기울기를 전처리 모듈로 전파한다.
여기서 사용되는 손실 함수는 아래와 같다.
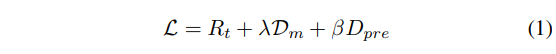
변수들이 의미하는 바는 아래와 같다.
- Rt: 재구성된 이미지 X¯를 기반으로 한 coding bit rate
- Dm: 재구성된 이미지 X¯를 기반으로 한 Vision task에서의 손실
- λ: trade-off를 조절하는 데 사용되는 하이퍼 파라미터
- Dpre: 입력 이미지 X와 재구성된 이미지 X¯사이의 왜곡
- β: 상수 가중치 파라미터
B. Neural Preprocessing Network
아래는 해당 논문에서 제시하고 있는 신경망 전처리 모듈의 아키텍처이다.
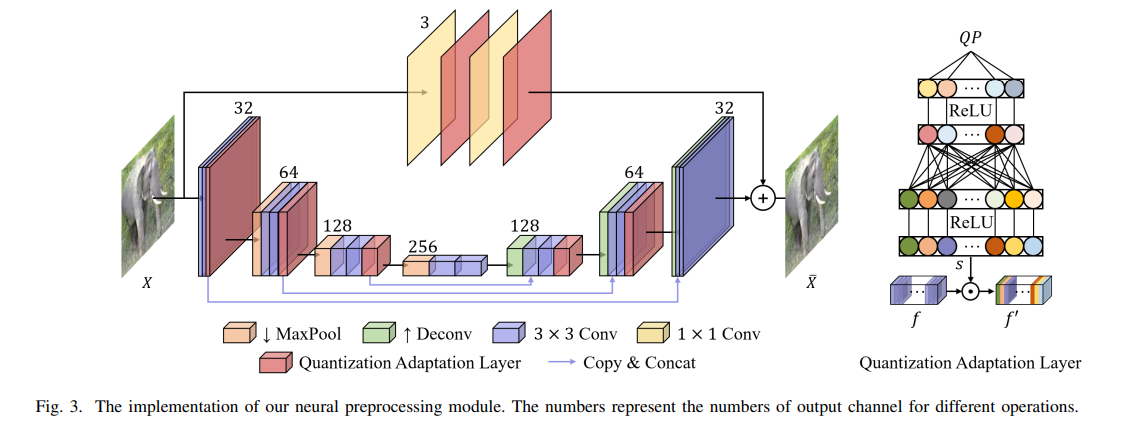
구체적으로 원본 이미지 X는 2개의 병렬 Branch로 입력된다.
첫 번째 branch에서는 1x1 Conv를 사용하여 이미지 픽셀을 비선형으로 변환하여, 이미지를 정밀하게 조절한다.
두 번째 branch에서는 U-net 스타일의 네트워크를 통해 이미지의 의미적 정보를 추출한다.
architecture내의 Quantization Adaptive Layer에 대해 조금 더 살펴보자.
이는 codec의 양자화 매개변수에 기반한 적응형 전처리를 가능하게 한다.
구체적으로 주어진 양자화 매개변수 QP를 기반으로, 2층 MLP 네트워크를 사용하여 스케일 벡터 s를 생성한 후에, 이를 입력 특성 f와 채널별 곱셈을 수행하여 f'을 생성한다.
이러한 전략을 기반으로 해당 모듈은 주어진 QP에 대해 BPG 코덱에서 최적의 필터링된 이미지 X¯를 생성하고 더 나은 rate-accuracy 균형을 맞출 수 있다.
아래는 해당 모듈을 적용해본 결과이다.
집중적으로 살펴봐야할 부분은 (c)인데,
전처리 모듈에 의해 버려진 정보가 주로 배경 영역에 분포되어 있음을 보여준다.

이를 통해 전처리 모듈이 후속 작업을 위해 더 중요한 의미 정보를 보존하고 bit rate 절감을 위해 불필요한 정보를 줄일 수 있음을 입증하였다.
C. Proxy Network
해당 프레임워크에서는 전체 시스템의 end-to-end 최적화를 위해, 학습된 이미지 압축 네트워크를 proxy network로 도입하여 역전파 단계에서 전통적인 codec을 대체한다.
학습된 이미지 압축 접근 방식은 Rate-Distortion 손실 R+λpD 기반으로 최적화된다.
여기서는 사전 학습된 이미지 압축 모델이 BPG와 비슷한 성능을 가지도록 하기 위해 λp파라미터로 최적화되어있다.
해당 네트워크는 학습 시에만 사용되며, 역전파 과정을 수행하는 동안 아래와 같은 여러 하이퍼 파라미터들에 대한 최적의 값을 찾아내는 과정을 수행한다.
- Pre-processing modules의 파라미터:
θpre- 모든 가중치, bias 파라미터
- 손실 함수의 하이퍼 파라미터:
λ,βL = Rt + λ * Dm + β * Dpre
- MLP 네트워크 파라미터(양자화 적응 레이어)
- R-D 손실 하이퍼 파라미터: λ_p
- Proxy network가 BPG의 성능을 얼마나 잘 모방할지 결정
- BPG와 유사하게 만드는 것이 목표
- Machine Vision Task 모델의 파라미터
이러한 일련의 과정을 알고리즘으로 보이면 아래와 같다.

IV. EXPERIMENTS
A. Experimental Setup
Datasets, Backbone Models and Evaluation Metrics
- Proxy Network
- 학습 데이터셋: Flicker
- random crop 256x256
- 800k images
- Object Detection
- 학습: COCO 2017
- 검증: COCO 2017 5000개
- 비교 모델
- FCOS
- Faster-RCNN
- RetinaNet
- 평가 지표: mAP
- Image Classification
- 학습: ImageNet 1280000개
- 검증: ImageNet 50000개
- 비교 모델
- ResNet
- Swin Transformer
- Vision Transformer
- 평가 지표: Top-1
여러 Task에 대한 일반화 능력 평가를 위해 Semantic segmentation과 Pose estimation으로도 평가
다양한 코덱에 대한 일반화 능력 평가를 위해 JPEG과 VVC에서도 적용
BPP는 압축 과정과 관련된 코딩 비용을 정량화하는 표준 메트릭
kodak 데이터셋과 LPIPS와 같은 지각적 메트릭 사용하여 인간 시각 시스템에 대한 압축 성능 평가
Implementation Details
- Pytorch에서 구현
- RTX 3090 GPU
- QP = {28, 31, 34, 37, 41}
- λ 값은 {0.5, 1, 2, 4, 8}
- 비율-정확도 균형 매개변수 β: 0.5
B. Main Results
Object Detection
Rate-Accuracy 그래프가 다음과 같다.
FCOS를 사용했을 때를 기준으로는 무려 동일한 mAP값에서 각각 20.3%, 19.5%의 Bit rate 절감을 제공한다.
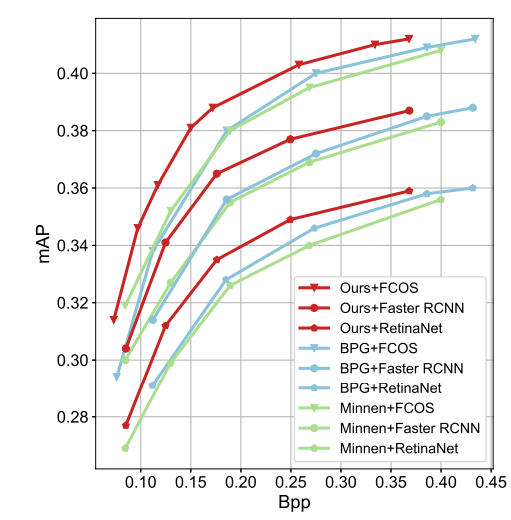
Image Classification
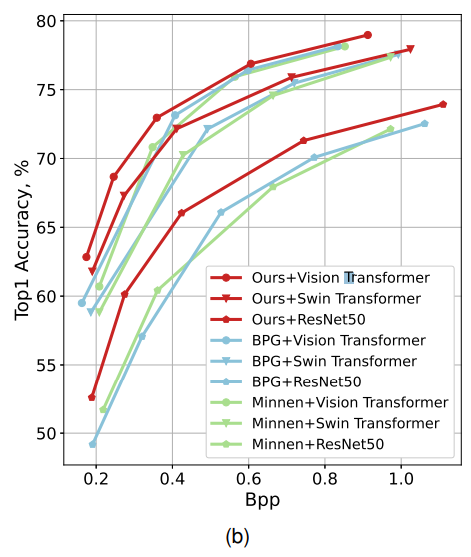
이미지 분류 작업에서는 Rate-Accuracy(Top-1) 그래프를 보여준다.
ResNet50을 사용했을 때를 기준으로 전통적인 코덱 BPG과 비교하여 약 22.5%의 Bitrate를 절약한다.
C. Generalization Ability
Different Backbones Networks
Object Detection을 위해 FCOS외에도 RestinaNet 등 다양한 백본 네트워크에 적용하여 실험을 확장했다.
FasterRCNN, RestinaNet 모델에 대해 각각 19.8%, 18.8%의 bit rate를 절감할 수 있었다.
(해당 결과에 대한 표는 위에서 확인했던 표와 같다.)
Different Tasks
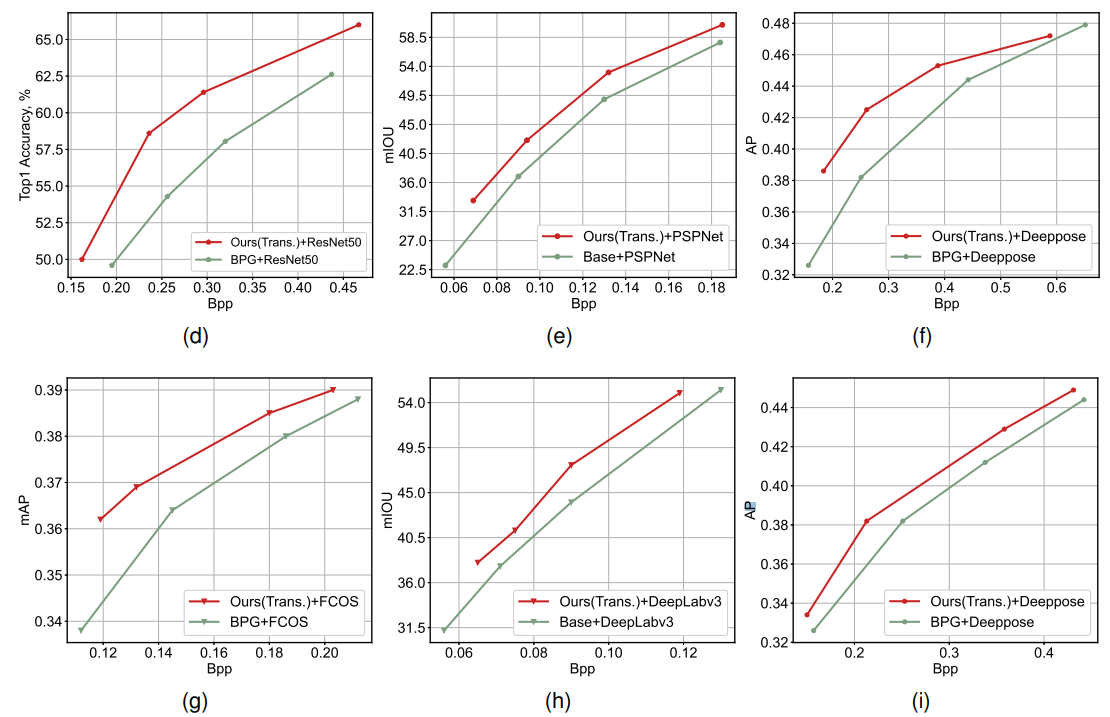
아래의 표 중에서 (d)~(i)에 집중해서 보자.
사전 훈련된 Neural Processing Pipeline(NPP) 모듈을 추가적인 3가지 vision task에 맞게 조정하였다.
(f)만 보면,
object detection에 최적화된 NPP 모듈을 Pose estimation에 적용한 결과, 24.6%의 bitrate 절감을 달성했다.
Different Codecs
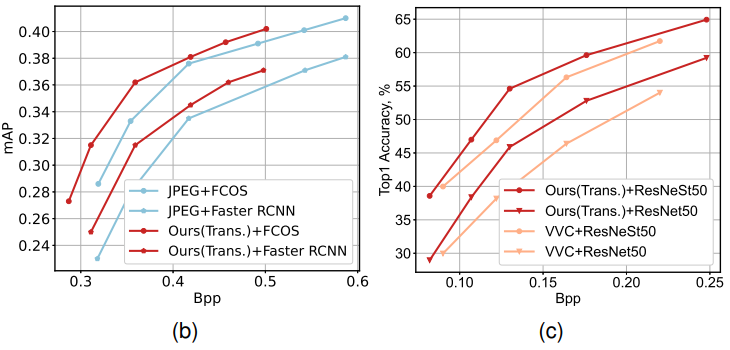
제안된 방식이 다양한 codec에 걸쳐 일반화될 수 있는지 확인하기 위해 BPG 코덱을 위해 최적화된 NPP모듈을 JPEG과 VVC 코덱에 맞게 Fine-tuning없이 배포했다.
위의 Fig 7의 (b)에서는 향상된 JPEG Preprocessing이 기존 JPEG 코덱에 비해 각각 FCOS, Faster RCNN백본 네트워크 상에서 8.5%, 10% 이상의 Bitrate 절감을 달성한다는 것을 보여준다.
(c)에서는 향상된 VVC Preprocessing이 기존 VVC 코덱에 비해 ResNet과 ResNetSt 백본 네트워크 상에서 각각 15.6%, 12.9% 이상의 Bitrate 절감을 달성함을 보여준다.
D. Ablation Study and Model Analysis
Analysis of the Generalization Ability
이 문단에서는 NPP모듈이 다양한 Vision task에서 효과적이고 일반화가 가능함으로 보여준다.
객체 감지와 분류의 경우 이미지 내에서 유사한 관심 영역에 집중한다.
NPP 모듈은 중요한 영역의 정보를 향상시키고 보존하도록 설계하였다. 이를 통해 주요한 시각적 단서를 유지하고 downstream task에 필요한 요소를 확보한다.
아래는 Faster-RCNN과 ResNet을 통해 도출된 focus area이다.
Faster-RCNN은 Object Detection하는 모델이고, ResNet은 Classification 모델임에도 불구하고, 이미지 내에서 focus하고 있는 영역이 크게 겹침을 보여준다.

이를 통해 NPP 모듈이 특정 task에 최적화되어 있긴 하지만, 주목하는 영역이 겹친다는 점은 NPP 모듈의 일반화 능력을 보인다.
Analysis of End-to-end Optimization
위 본문에서 설명했듯이 제안된 방법은 forward 단계에서 BPG가 복원된 이미지를 생성하는 데 사용되고, backward 단계에서는 proxy 네트워크의 기울기를 이용하여 preprocessing 모듈의 파라미터를 업데이트한다.
NPP+Minnen 방식은 학습시에 forward, backward 모두에서 proxy 네트워크만을 사용한다.
즉 BPG 코덱없이 Proxy 네트워크만으로 학습한다.
그러나 추론할 때 압축 및 복원 과정에서는 BPG 코덱을 사용한다.
이와 같이 Proxy network는 이미지 전처리의 fine-tuning과 최적화에 도움이 된다. NPP+Minnen 방법은 이 네트워크를 사용하여 이미지의 중요한 특징을 더 잘 유지하면서 압축을 진행할 수 있다. 또한 이러한 방식의 가장 큰 장점은 다양한 QP 값에서 잘 일반화되며 학습 중에 BPG의 압축 알고리즘을 직접 사용하지 않기 때문에 더 넓은 범위의 이미지에 대해 효과적으로 작동할 수 있다. 즉 일반화 성능이 좋다는 뜻
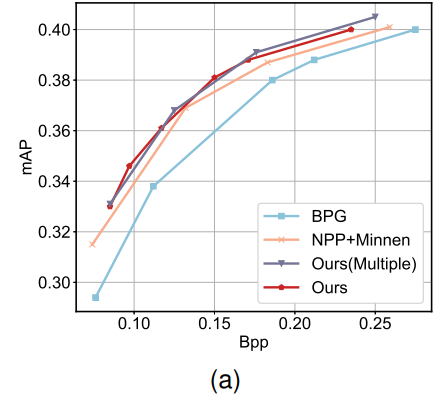
Analysis of Quantization Adaption Strategy
Quantization adaptive layer를 생략하고, BPG 내에서 다양한 QP에 대해 별도의 NPP 모듈을 개발하는 방법인 Ours(Multiple)을 제안하였다.
이는 아래와 같이 높은 bitrate에서는 더 좋은 성능을 보이지만, 전체 성능은 Quantization Adaptive 구현과 거의 동일하다.
또한 이 방법은 여러 NPP 모델의 훈련 및 유지 관리를 필요로 하여 Encoder 측의 저장 요구 사항을 증가시킨다.
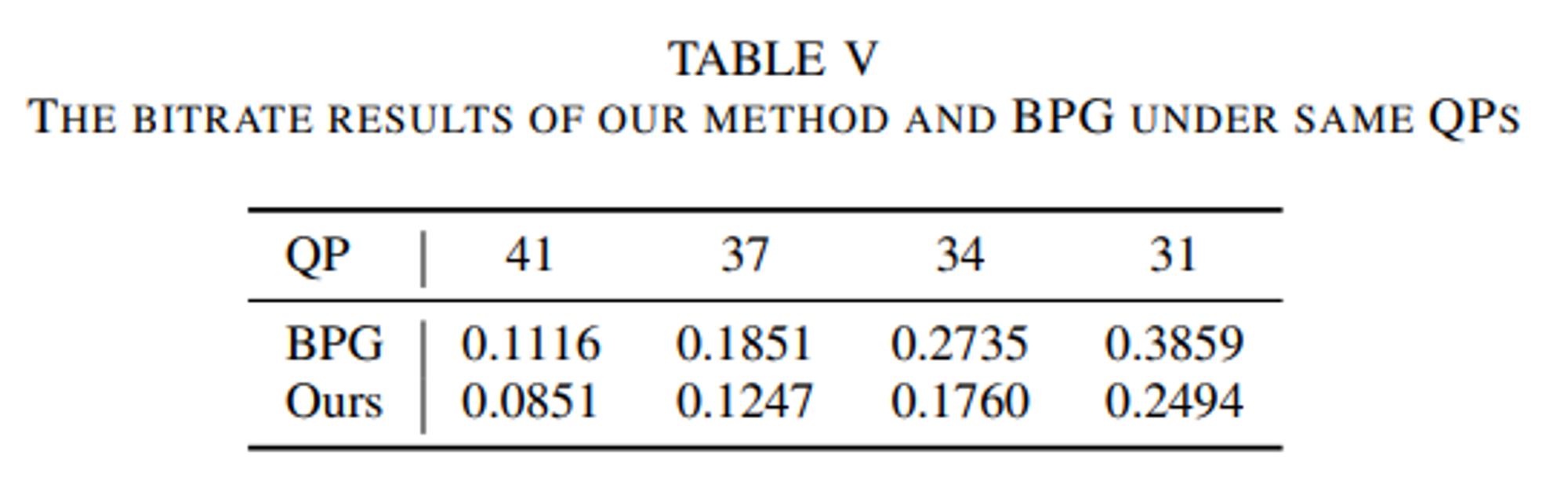
Analysis of the NPP module's impact on bitrate
동일한 양자화 파라미터(QP)설정에서, 제안한 NPP 모듈이 전처리된 이미지의 인코딩에 필요한 bitrate를 크게 줄이는 것을 관찰하였다.
결과를 정리한 것은 아래와 같다.
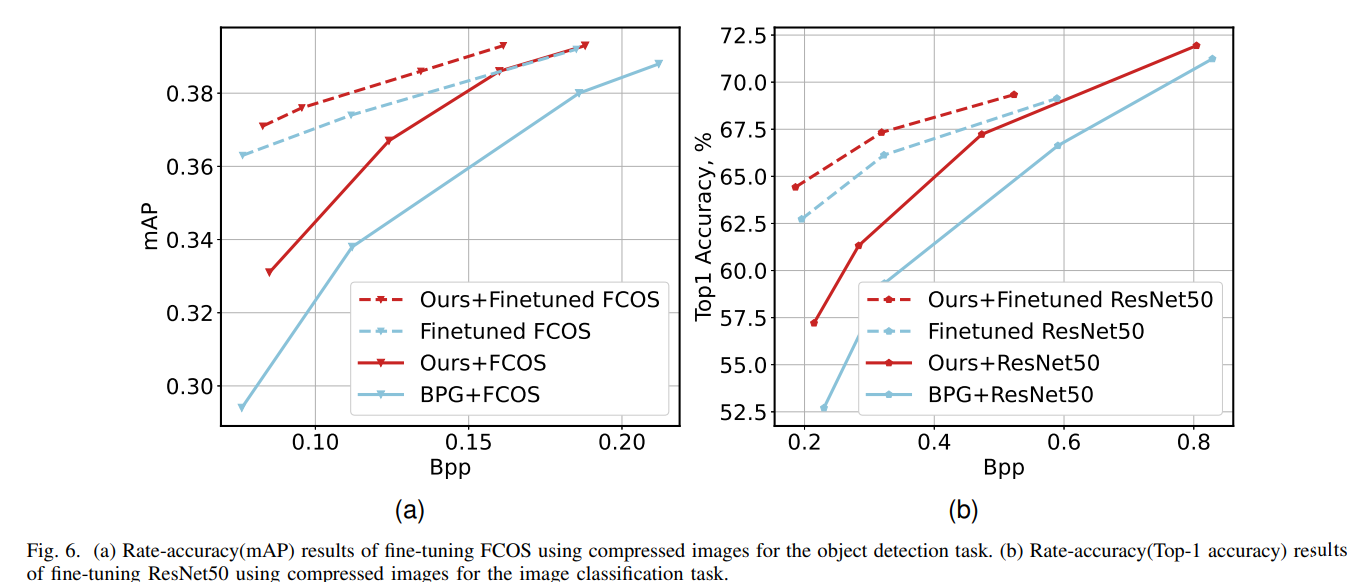
Experimental Results for Fine-tuned Downstream Networks
본문에서는 손실 압축을 거친 이미지에 대해 downstream visual task 모델이 fine-tuning이나 최적화를 거치지 않는다는 가정하에 작업을 하였다.
그러나 tine-tuning을 시도한 결과 성능을 아래와 같이 더욱 향상시킬 수 있었다.
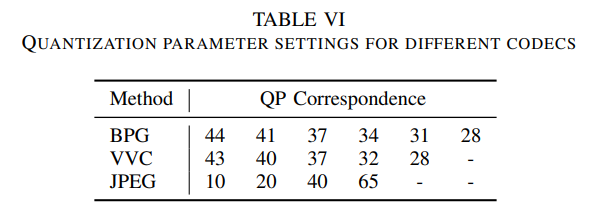
Quantization parameter settings for different codecs
- BPG 코덱: QP 44는 Kodak 데이터셋에서 약 27.63의 PSNR을 제공
- VVC 코덱: QP 43은 Kodak 데이터셋에서 약 27.38의 PSNR을 제공
Compression Performance in terms of Human Visual System
여기서 제안하는 프레임워크는 Machine Vision Task에 최적화되어 있기 때문에, PSNR 측면에서의 압축 성능은 떨어진다.
그러나 LPIPS, MS-SSIM, FSIM과 같은 지각 관련 Metric을 사용하였을 때, 기존 BPG 코덱과의 성능 격차는 줄어들지만 Bitrate는 더 많이 소비된다.
실험 결과상에서는 각각 8.5%, 8.8%, 7.3%의 추가 비트레이트를 소비한다.
Effectiveness of the Proxy Network
Proxy network의 성능을 입증하기 위해 BPG Codec과 Proxy network 간의 rate-distortion 성능을 비교하였다.
그 결과 proxy network는 BPG와 유사한 성능을 보였으며(-1.4% BDBR차이), 이는 훈련 단계에서 BPG Codec을 proxy network로 대체할 가능성을 시사한다.
Visualization of Downstream Results
아래는 실험 결과를 시각화한 것을 보인다.
이를 통해 제안된 NPP(Neural Preprocessing)모듈이 downstream 작업에 유익함을 보인다.
첫 째로 아래의 결과에서 1번째행과 2번째행을 보면,
제안된 방법(Ours)의 이미지는 올바르게 분류되는 반면 BPG에서의 결과는 잘못된 분류를 보인다.
또한, BPG와 비교하여 더 적은 Bitrate를 소비하는 것까지 확인할 수 있다.
3번째와 4번째 행에서도 유사한 결과가 나타난다.

Analyzing the Effectiveness of NPP module using Grad-CAM
아래의 그림에서는 Grad-CAM을 사용하여 NPP 모듈의 효과를 평가한다.
1번째 행의 Filtered 이미지의 동물에 대한 분류 모델의 attention이 더 넓게 퍼져 있으며, heat map상에서 더 뚜렷한 빨간 영역으로 나타나고 있다.
2번째 행도 마찬가지!
그 결과 위의 사진에서도 봤듯이 Filtered 된 이미지는 ResNet50모델을 기준으로 정확하게 Koala로 식별하고 압축된 원본 이미지는 비슷한 bpp 1.03에서 Monkey로 분류한 것을 확인할 수 있다.
자료에는 안나와있지만, 아래의 이미지에서도 Filtered 된 이미지는 bpp 3.0에서 Mongoose로 올바르게 식별하지만, 압축된 원본 이미지는 bpp 0.37에서 Banded Gecko로 잘못 분류하였다고 한다.

Running Time and Complexity
NPP 모듈의 파라미터 수는 9.42M개
입력 이미지 크기가 224x224일 때,
NPP 모듈의 추론 시간은 단일 RTX 3090 GPU에서 4.23ms가 소요된다.
V. Conclusion
해당 연구에서는 기존의 이미지 압축 알고리즘을 기반으로 downstrema machine vision task을 위한 preprocessing enhanced image compression 프레임워크를 제안하였다.
coding bitrate와 machine vision task의 성능 간의 더 나은 균형을 이루기 위해 Neural Preprocessing 모듈을 도입하였다.
또한, 전통적인 codec의 비미분 가능 문제를 해결하기 위해 proxy network 도입을 제안하였으며, 이를 통해 gradient가 Neural Preprocessing 모듈로 역전파될 수 있도록 보장하고, end-to-end 최적화를 달성한다.
논문이 길어서 조금 힘들었지만!
뭔가 학습과 추론 단계를 분리해서 backpropagation을 적용하고 이를 통해 end-to-end가 가능하도록 한 것이 신기했다.
아이디어가 신선했는데 다양한 task에서 성능이 우수한 것같아서 나중에 이러한 매커니즘으로 구현을 해볼 수도 있겠다는 생각이 들었다.
아직 논문 쓰는 것도 읽는 것도 초반이라 추론 시간 4.23ms가 긴 것인지 아닌지 그래서 실시간 프로그램에 적용될 수 있는 수치인지 와닿진 않지만, 이건 내가 실험해보고 논문써보면서 알아보도록 하자!😊✨
