
1. 선형 회귀
이전 velog에서 작성했듯이 선형 회귀에는 회귀(Regression)과 분류(Classification)이 있다.
선형 회귀는 직선의 방정식으로 표현된다.
f(X) = m*x +b
이 중에서 m과 b를 우리가 제어할 수 있다.
m은 가중치(weight)이라고 하고, b는 바이어스(bias) 즉 편향값이라고 한다.
선형 회귀 식은 2가지로 나누어볼 수 있다.
- 단순 선형 회귀
- 독립변수(x)가 하나인 선형 회귀
f(x) = w*x + b
- 다중 선형 회귀
- 독립변수가 여러 개인 선형 회귀
f(x, y, z) = w0 + w1*x + w2*y + w3*z- w1, w2, w3는 계수 또는 가중치
- x, y, z는 각 정보의 속성
- 예를 들어, 매출액을 예측할 때 속성에 포함될 수 있는 값으로는 인터넷 광고, TV광고, 신문 광고에 대한 회사의 광고 지출액이 될 수 있을 것이다.
이제 f(X)를 찾는 방법을 알았다.
우리는 도출해 낸 x에 대한 f(x)의 값과 x에 매핑되는 실제 y값간의 간격을 줄이는 것이 제일 중요할 것이다⭐
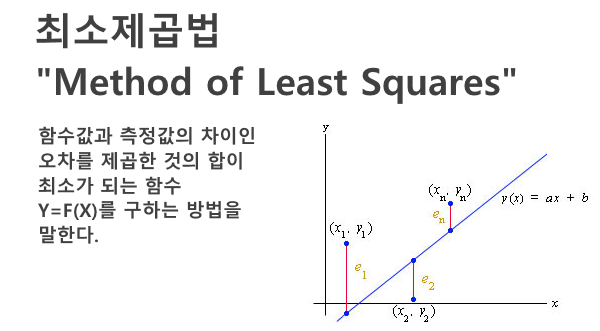
이 때 사용하는 것이 손실 함수(Loss Function) 또는 비용 함수(Cost Function)이다.
이는 방금 말한 "간격"의 제곱의 합이다.

머신러닝에서 모델을 학습시킨다는 것은 훈련 데이터로부터 손실을 최소화하는 가중치(w)와 바이어스 값(b)을 학습하는 것이다.
2. 선형 회귀에서 손실 함수 최소화 방법
분석적인 방법
독립 변수와 종속 변수가 각각 하나인 선형 회귀에서는 손실 함수의 형태는 2차 함수로 단순하다.
통계학에서 사용되는 최소 제곱법을 사용하면 된다!
그러나 독립 변수가 여러개인 경우라면 해당 방식이 매우 복잡해질 것이다. 이를 보완한 방법이 경사 하강법👍👍👍
경사 하강법(Gradient Descent Method)
현재 위치에서 경사(기울기)를 이용하여 방향을 잡는 방법이다.
w(가중치)에 대한 손실함수(f(w))의 값을 함수로 표현하고, 가중치를 변경했을 때 기울기에 따라 매개변수를 업데이트해가며 Loss(손실)을 줄여 나가는 방식이다.🥺
너무 말을 어렵게 한거같다,,,
그림으로 간단하게 보면 아래와 같다!
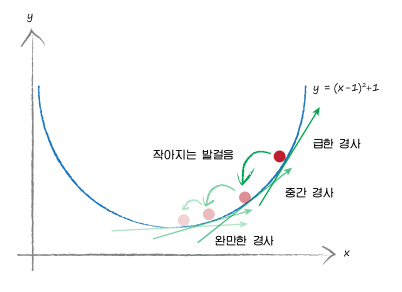
손실값이 최저가 되는 지점찾기!!⭐⭐⭐
방법은 다음과 같다.
- 기울기가 음수면 가중치를 증가시키기
- 기울기가 양수라면 가중치를 감소시키기
그렇다면 가중치를 증가시키고 감소시킬 때 얼마나 이동해야 할까?🤔
이를 결정하는 것이 학습률(Learning Rate)
학습률: 한 번에 매개변수를 변경하는 비율
이를 적절하게 설정하는 것이 중요하다.
그 이유는 아래의 그림과 같이 너무 크면 너무 큰 보폭으로 이동하여 최소값을 지나쳐 발산할 수도 있고, 반대로 너무 작으면 계산량이 증가하기 때문이다.
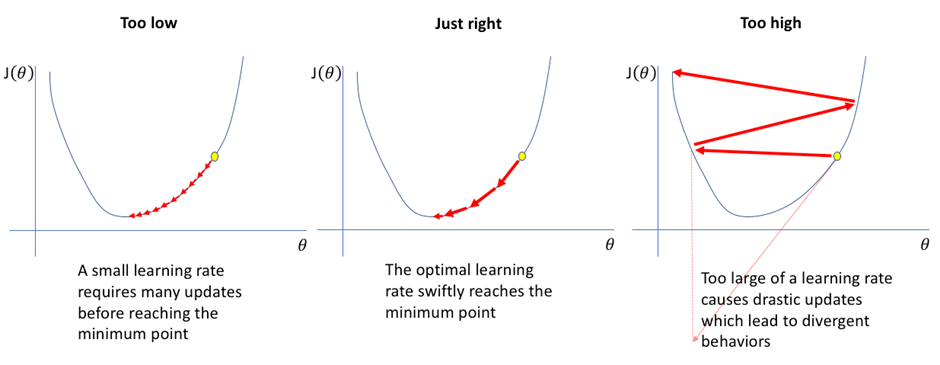
3. 선형 회귀 파이썬 구현 #1
선형 회귀에서 경사 하강법을 구현해보자!
간단하게 임의의 배열을 만들어서 w와 b를 구하는 과정을 구현하였다.
import numpy as np
import matplotlib.pyplot as plt
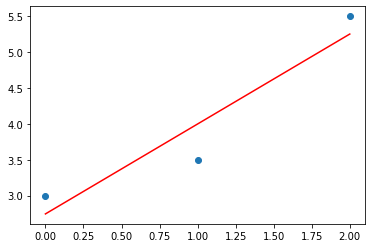
X = np.array([0.0, 1.0, 2.0])
y = np.array([3.0, 3.5, 5.5])
w = 0 # 가중치
b = 0 # bias
lrate = 0.01 # 학습률
epochs = 1000 # 반복 횟수
n = float(len(X))
for i in range(epochs):
y_pred = w*X+b
# 손실함수를 각각 w, b로 편미분했을 때의 값
dw = (2/n) * sum(X*(y_pred-y))
db = (2/n) * sum(y_pred-y)
# w와 b를 각각 업데이트해주기
w = w - dw * lrate
b = b - db * lrate
print(w, b)
y_pred = w*X + b
# 입력 데이터를 그래프 상에 찍는다.
plt.scatter(X, y)
# 예측값은 선그래프로 그린다.
plt.plot([min(X), max(X)], [min(y_pred), max(y_pred)], color = 'red')
plt.show()

4. 선형 회귀 파이썬 구현 #2
방금은 되게 힘들게 수학 식을 직접 구현하여 나타냈지만,
사실 우리한텐 라이브러리가 있다!🥹
아나콘다에 포함되어 있는 사이킷런 라이브러리이다.
이걸로 한번 w와 b를 출력해보자~!
import matplotlib.pylab as plt
from sklearn import linear_model
# 선형 회귀 모델 객체 생성
reg = linear_model.LinearRegression()
# 임의의 데이터 배열 선언
X = [[0], [1], [2]]
y = [3, 3.5, 5.5]
# 학습
reg.fit(X,y)
print(reg.coef_) # 직선의 기울기(가중치)
print(reg.intercept_) # 직선의 y 절편
print(reg.score(X,y)) # 회귀 분석이 얼마나 잘 데이터에 맞춰졌는지 확인 -> 1에 가까울 수록 잘 맞추어진 것

선형 회귀 그래프로 나타내기
위에서 생성한 모델에 임의의 값을 입력하여 얼마나 잘 예측하는지 확인해보자!
학습이 끝난 후에 테스트할 때는
predict()를 사용하는데 이 때 2차원 리스트로 데이터를 전달해야 한다. 머신러닝에서 입력은 항상 2차원 배열이니 잘 생각해둘 것⭐⭐⭐
# 임의의 X값인 5를 대입하여 예측 출력값 출력
print(reg.predict([[5]]))
# 기존 모델 생성시에 사용했던 실제 값들 출력
plt.scatter(X, y, color='black')
y_pred = reg.predict(X) # 방금 입력한 값에 대한 예측값
plt.plot(X, y_pred, color = 'blue', linewidth = 3) # 선형 회귀 함수
plt.show()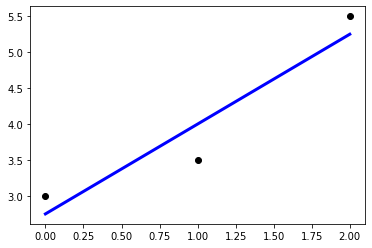

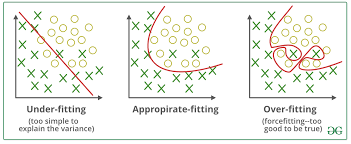
5. 과잉 적합 vs 과소 적합
머신러닝에서 흔하게 볼 수 있는 것이 과잉 적합(Overfitting)과 `과소 적합(Underfitting)이다.
과잉 적합: 학습하는 데이터에서는 성능이 뛰어나지만, 새로운 데이터(일반화)에 대해서는 성능이 잘 나오지 않는 모델을 생성하는 것이다.
원인: 훈련 데이터에 섞인 Noise까지 학습하기 때문이다.
과소 적합: 훈련 데이터에서도 성능이 좋지 않은 경우이다.
원인: 모델 자체가 적합지 않은 경우로 더 나은 모델을 찾아야 한다.
이번엔 머신러닝 중에서 선형회귀 알고리즘에 대해서 알아보고 Overfitting, Underfitting에 대해서 간단히 알아보았다.
다음 시간부터는 신경망에서 중요한 퍼셉트론 개념에 대해서 살펴보자!
