
자 그럼 이번에는 이미지 분류를 할 것이다!~😎
5. 필기체 숫자 이미지를 분류해보자.
아래의 라이브러리를 추가 설치해주어 이미지를 불러올 수 있게 해주자!
pip install pandas
pip install matplotlib이번에 활용할 필기체 숫자 이미지는 미국의 MNIST가 배포하는 데이터셋이다.
해당 데이터셋의 숫자들은 28*28의 2차원 이미지로 표현된다.
즉 784개의 픽셀로 이루어져 있다.
데이터셋 확인
아래와 같은 필기체의 숫자 이미지가 담겨져 있다.
import matplotlib.pyplot as plt
from sklearn import datasets, metrics
from sklearn.model_selection import train_test_split
# MNIST 안에 저장된 숫자 이미지 데이터셋 불러옴
digits = datasets.load_digits()
# 이미지 띄우기
plt.imshow(digits.images[0], cmap = plt.cm.gray_r, interpolation = 'nearest')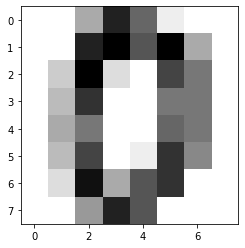
그러나 우리는 2차원 이미지 배열이 아닌 1차원 배열을 사용할 것이다!
이 과정을 평탄화(flatten)라고 한다.
평탄화 하는 이유는 일반적인 머신러닝 알고리즘은 특징들을 1차원으로만 받기때문이다.
따라서 (8, 8) 형상을 (64,1) 형상으로 바꾸어줘야 한다는 것이다.
이를 위해 아래와 같은 코드를 추가해준다.
n_sample = len(digits.images) # 이미지 개수
data = digits.images.reshape((n_sample, -1))훈련 데이터와 테스트 데이터 분할
훈련 데이터와 테스트 데이터를 8:2 비율로 분할해주었다.
# 훈련 데이터와 테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(data, digits.target, test_size = 0.2)모델 선택 및 학습/평가
이번에도 이전과 같이 KNN 알고리즘을 적용할 것이다.
# 모델 학습
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 6)
knn.fit(X_train, y_train)
# 모델 평가
y_pred = knn.predict(X_test)
scores = metrics.accuracy_score(y_test, y_pred)
print(scores)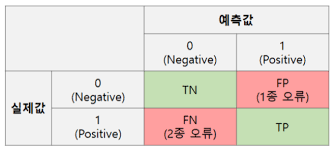
정확도가 98.3%~!👍
6. 머신러닝 알고리즘의 성능평가
우리는 지금까지 실습에서 knn 알고리즘만 사용해보았는데!
사실 이 외에도 SVM, 결정 트리, 신경망 등의 알고리즘이 존재한다.
따라서 우리가 어떤 알고리즘을 사용할지 정하기 위해서는 각 알고리즘의 성능을 평가해볼 필요가 있다.
이를 위해 우리는 대표적으로 2가지 방법을 사용한다.
- 정확도(Accuracy)
- 혼동행렬
a. 민감도(Sensitivity)
b. 특이도
혼동행렬을 보기 위해서는
metrics.plot_confusion_matrix(모델, 입력값(x_test), 출력값(y_test))을 출력하면 된다.
7. 머신러닝의 용도
머신러닝이 사용되는 곳에 대해 알아보자!
책에 있는 내용으로만 마무리하겠다!
- 영상 인식, 음성 인식처럼 프로그램으로 작성하기에는 규칙과 공식이 너무 복잡할 때
- 전자 메일 메시지가 스팸이닞 아닌지 여부
- 신용 카드 거래가 허위인지 여부를 판별하는 시스템
- 구매자가 클릭할 확률이 가장 높은 광고가 무엇인지 알아내는 시스템
- 이미지 인식 시스템
- 넷플릭스에서 비디오 추천 시스템
- 이미지 탐색 시스템
- 자율 주행 자동차
- 텍스트 자동 인식 시스템
머신러닝의 기본적인 개념과 실습에 대해서 마쳤다😎😎😎
이제 다음 챕터에서는 선형 회귀에 대해서 알아보자~!
비록 앞에서 실습을 했지만 아마 조금 더 구체적이겠지?ㅎ_ㅎ?
고고~
