
저번 시간에는 범주형 데이터를 인코딩하는 방식과 가중치를 초기화하는 방식에 대해서 각각 알아보았다.
이번엔 데이터를 Normalization하는 방법, 그리고 과잉적합과 과소적합에 대해 알아보고 이를 방지하는 전략까지 다루어볼 것이다.🤔
7. 데이터 정규화
학습을 수행하기 전에 데이터를 정규화(Normalization)하는 것은 중요하다.
예를 들어 입력 x1, x2를 가지는 신경망이 하나 존재한다고 하자.
x1은 0~1의 값을 가지고, x2는 0~100의 값을 가진다.
신경망은 일련의 선형 조합과 비선형 활성화 함수를 통해 입력을 결합하여 학습하게 되므로 각 입력과 관련된 매개 변수도 서로 다른 범위를 가지면서 학습된다.
따라서 이것은 큰 범위의 특정 매개변수의 그래디언트에 더 중점을 둔 손실함수 모양이 될 것이다.❗❗❗
따라서 모든 입력을 정규화, 즉 같은 범위의 값으로 만들어주어야 한다.
가장 많이 사용되는 방법은 가우시안 정규화 기법이다.
고등학교 수학에서 배운 것같은데, 평균을 0, 값의 범위를 약 -1.0~1.0으로 제한되도록 수치데이터의 값을 바꾸어주는 것이다.
수식은 아래와 같다.
x' = (x - 평균) / 표준편차
sklearn의 데이터 정규화 방법
sklearn의 MinMaxScaler 클래스는 0에서 1사이의 범위에 있도록 값들을 정규화해준다.
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2],
[-0.5, 6],
[0,10],
[1,18]]
scaler = MinMaxScaler() # 객체 생성
scaler.fit(data) # 데이터의 최소값과 최대값 구함
print(scaler.transform(data)) # 데이터 변환Keras의 데이터 정규화 방법
Keras의 Normalization 클래스를 사용하였다.
이 객체의 adapt()메서드를 호출하면 케라스가 데이터를 분석하여 평균과 분산을 계산한다.
이후에 해당 클래스에 데이터를 넣어주면 정규화된 수치를 반환한다.
from tensorflow.keras.layers.experimental.preprocessing import Normalization
import numpy as np
# 정규화할 데이터의 범위
data = np.array([[1.],[2.],[3.],[4.],[5.]])
# 테스트로 넣어볼 데이터들
input_data = np.array([[1.],[2.],[3.]])
layer = Normalization() # 정규화 객체
layer.adapt(data)
print(layer(input_data))
이렇게 데이터를 넣어서 정규화하는 경우도 있지만, 직접 Normalization객체를 선언 시에 평균과 분산 값을 입력해줄 수도 있다.
8. 과잉 적합과 과소 적합
과잉 적합(Over fitting): 지나치게 훈련 데이터에 특화되어 실제 적용 시 좋지 못한 결과가 나오는 것
- 신경망의 매개 변수가 많을 때 발생
- 은닉층의 개수가 많거나 뉴런의 개수가 너무 많으면 심해진다.
- 신경망 모델을 너무 오래 훈련해도 발생할 수 있다.
훈련이 계속되어도 Test 데이터의 손실 수치가 감소하지 않으면 과잉 적합 가능성☝️☝️☝️
과소 적합(Under fitting): 신경망 모델이 충분히 훈련되지 않는 것
- 신경망 모델이 너무 단순하거나, 규제가 너무 많거나, 충분히 오래 훈련하지 않았을 때 발생
- 뉴런의 수가 너무 적거나, 은닉층의 개수가 부족한 경우 발생
예제
영화 리뷰를 분류하는 문제이다.
Tensorflow Keras의 imdb라는 데이터셋을 사용하였다.
아래의 코드에 대한 설명은 생략한다.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 데이터 다운로드
imdb = tf.keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
# 원-핫 인코딩
def one_hot_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, word_index in enumerate(sequences):
results[i, word_index]=1.
return results
train_data = one_hot_sequences(train_data)
test_data = one_hot_sequences(test_data)
# 신경망 모델 구축
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(16, activation="relu", input_shape=(10000,)))
model.add(tf.keras.layers.Dense(16, activation="relu"))
model.add(tf.keras.layers.Dense(1, activation="sigmoid"))
model.compile(loss="binary_crossentropy", optimizer = "adam", metrics=["accuracy"])
# 신경망 훈련, 검증 데이터 전달
history = model.fit(train_data,
train_labels,
epochs=20,
batch_size =512,
validation_data = (test_data, test_labels),
verbose=2)
# 훈련데이터의 손실함수값과 테스트데이터의 손실함수값을 그래프에 출력
history_dict = history.history
loss_values = history_dict['loss'] # 훈련 데이터 손실함수값
val_loss_values = history_dict['val_loss'] # 테스트 데이터 손실함수값
acc = history_dict['accuracy'] # 정확도
epochs = range(1, len(acc)+1) # 에포크 수
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title("Loss Plot")
plt.ylabel("loss")
plt.xlabel("epochs")
plt.legend(["train error", "val error"], loc = "upper left")
plt.show()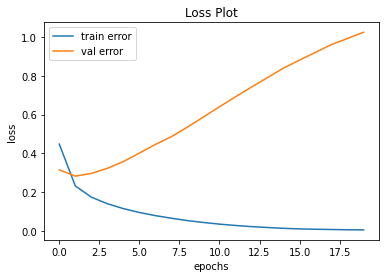
살펴보아야 할 점은 저 부분이다.
훈련 데이터가 학습되면서 손실 함수의 값이 떨어지는 것을 확인할 수 있는데,
반면에 일정 epoch부터 Test 데이터 즉 검증 데이터의 손실 함수값이 다시 증가하는 것을 확인할 수 있다.
즉 저 ephoch부터는 과잉 적합이 발생했다고 판단할 수도 있을 것이다.
9. 과잉 적합 방지 전략
사실 가장 단순하고 가장 좋은 방법은 양질의 훈련 데이터의 양을 늘리는 것이다.
하지만 훈련 데이터를 많이 확보하는 것은 한계가 존재한다.
이런 경우에 이를 방지할 수 있는 전략은 아래와 같다.
-
조기 종료: 검증 손실이 증가하면 훈련을 조기에 종료한다.
-
가중치 규제 방법(Weight Regularization)⭐: 가중치의 절대값을 제한한다.
- L1규제: 가중치의 절댓값에 비례하는 비용이 추가된다.
- 가중치를 0으로 만든다는 단점
- L2규제: 가중치의 제곱에 비례하는 비용이 추가된다.
- 가중치 파라미터를 제한하긴 하지만 완전히 0으로 만들진 않는다.
- 이로 인해 L2 규제를 더 많이 사용
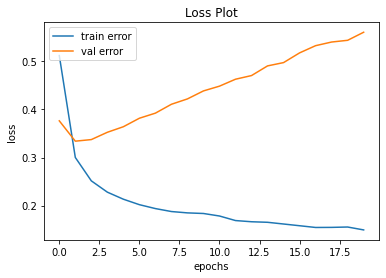
- 아래의 예제를 통해 이전에 비해서는 손실값이 줄어드는 것을 확인할 수 있다.
- L1규제: 가중치의 절댓값에 비례하는 비용이 추가된다.
# 신경망 모델 구축
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(16, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation="relu", input_shape=(10000,)))
model.add(tf.keras.layers.Dense(16, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation="relu"))
model.add(tf.keras.layers.Dense(1, activation="sigmoid"))
model.compile(loss="binary_crossentropy", optimizer = "adam", metrics=["accuracy"])
- 데이터 증강 방법: 데이터를 많이 만든다.
- 소량의 훈련 데이터에서 많은 훈련 데이터를 뽑아내는 방법
- 이미지를 확대하거나, 좌우로 반전시키거나, 회전 시켜서 변형된 이미지를 생성
- 드롭아웃 방법⭐⭐⭐: 몇 개의 뉴런을 쉬게 한다.
- 신경망에서 가장 효과적이고 널리 사용되는 규제 기법
- 훈련단계에서만 적용
- 신경망 모델에 Layer 처럼
add() - 몇 개의 노드들을 학습 과정에서 랜덤하게 제외하는 것
# 신경망 모델 구축
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(16, activation="relu", input_shape=(10000,)))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(16, activation="relu"))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(1, activation="sigmoid"))이전과 달리 tf.keras.layers.Dropout(0.5)를 확인할 수 있을 것이다.
또한 아래처럼 손실함수값도 이전보다 훨씬 향상되었다.👍👍
데이터 정규화의 중요성, 과잉적합과 과소적합이 검증 데이터에 얼마나 큰 문제를 야기하는지 느낄 수 있었다.
과잉 적합으로 인해 증가하는 손실값이 크다는 것을 느꼈고, 적당한 Epoch값과 방지 전략들을 잘 활용해야겠다는 생각이 들었다🥺
특히 Dropout() 메서드! 잘 기억해주겠어😊
참고 자료
https://goodtogreate.tistory.com/entry/Neural-Network-%EC%A0%81%EC%9A%A9-%EC%A0%84%EC%97%90-Input-data%EB%A5%BC-Normalize-%ED%95%B4%EC%95%BC-%ED%95%98%EB%8A%94-%EC%9D%B4%EC%9C%A0
https://limjun92.github.io/assets/TensorFlow%202.0%ED%8A%9C%ED%86%A0%EB%A6%AC%EC%96%BC/2.%20Keras%EB%A5%BC%20%EC%82%AC%EC%9A%A9%ED%95%9C%20ML%20basic/%5B%ED%8A%9C%ED%86%A0%EB%A6%AC%EC%96%BC5%5D%EA%B3%BC%EB%8C%80%EC%A0%81%ED%95%A9%EA%B3%BC%20%EA%B3%BC%EC%86%8C%EC%A0%81%ED%95%A9/
