
5. 가중치 초기화 문제
가중치가 모두 동일하게 주어지면 문제가 발생한다!
각각의 은닉층의 노드가 결국 같은 일을 하는 것이기 때문이다.
이러한 문제를 해결하는 것을 균형 깨뜨리기(Breaking the symmetry)라고 한다.
이를 방지하기 위해 가중치의 초기값은 난수로 결정되어야 한다.
그러나 반대로 너무 큰 가중치를 받게되면 그래디언트 폭발(Exploding Gradients)를 일으킨다고 한다.
가중치는 적절한 작은 난수로 초기화하는 것이 적합하다.=
가중치 초기화 방법
-
Xavier 방법
-
He 방법
케라스에서의 가중치 초기화 방법
1. 라이브러리 추가
from tensorflow.keras import layers
from tensorflow.keras import initializers2-(1). 정규 분포로 텐서를 생성
initializer = tf.keras.initializers.RandomNormal(mean=0., stddev=1.)
layer = tf.keras.layers.Dense(3, kernel_initializer=initializer)2-(2). 균일 분포로 텐서를 생성
initializer = tf.keras.initializers.RandomUniform(minval=0., maxval=1.)
layer = tf.keras.layers.Dense(3, kernel_initializer=initializer)6. 범주형 데이터 처리
지금까지 우리는 입력 데이터가 숫자인 것만 살펴보았었다.
그러나 입력 데이터 중에 'male','female'과 같은 문자열이 포함된 것이 많다.
머신러닝과 딥러닝의 신경망에서는 입력 및 출력 변수가 모두 숫자여야 한다.
따라서 이러한 범주형 데이터는 우린 숫자로 바꾸어주어야 할 필요가 있다.
방법은 간단하다.
for ix in train.index:
if train.loc[ix, 'Sex'] == 'male':
train.loc[ix, 'Sex'] = 1
else:
train.loc[ix, 'Sex'] = 0ㅋㅎㅋㅎ반복문을 돌면서 조건에 따라 바꾸어 준 것이다.
이런 방법말고 범주형 데이터를 숫자로 인코딩하는 일반적인 3가지 방법에 대해서 소개하겠다!
정수 인코딩(Integer Encoding)⭐: 각 레이블이 정수로 매핑원-핫 인코딩(One Hot Encoding)⭐: 각 레이블이 이진 벡터에 매핑임베딩(Embedding): 범주의 분산된 표현이 학습
아래와 같은 데이터를 가정하여 세 경우에 적용해보겠다.
| Country | Age | Salary |
|---|---|---|
| Korea | 38 | 7200 |
| Japan | 27 | 4800 |
| China | 30 | 3100 |
정수 인코딩
import numpy as np
x = np.array([['Korea', 44, 7200],
['Japan',27, 4800],
['China', 30, 3100]])
from sklearn.preprocessing import LabelEncoder
labelEncoder = LabelEncoder()
x[:,0]=labelEncoder.fit_transform(x[:, 0])
print(x)
정수 인코딩 문제점: 정수 값이 0, 1, 2로 나오는 경우, 신경망 모델이 이들 사이에 어떤 순서가 있다고 오해할 수도 있다.
=>원-핫 인코딩방식 제안
원-핫 인코딩(sklearn 사용)
sklearn 라이브러리의 OneHotEncoder 클래스를 호출한 것이다.
import numpy as np
x = np.array([['Korea', 44, 7200],
['Japan',27, 4800],
['China', 30, 3100]])
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder()
# 원하는 열을 뽑아서 2차원 배열로 만들어서 전달하기
xx=onehotencoder.fit_transform(x[:, 0].reshape(-1, 1)).toarray()
print(x[:,0].reshape(-1, 1)) # 이 과정이 열을 뽑아서 2차원 배열로 만든 것
print("------------")
print(xx) # 원-핫 인코딩한 결과물
x = np.delete(x, [0], axis = 1) # 0번째 열 삭제
x = np.concatenate((xx, x), axis = 1) # x와 xx를 붙인다.
print("------------")
print(x) 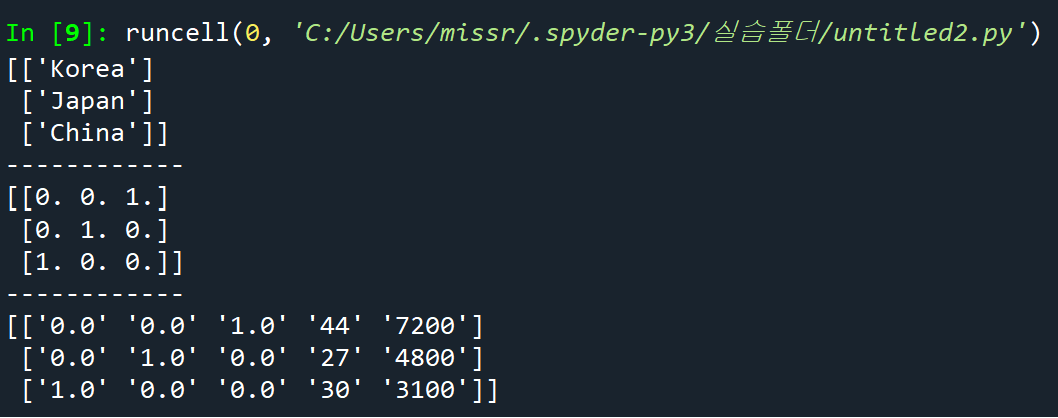
원-핫 인코딩(케라스 사용)
Keras의 to_categorical()을 호출해서 인코딩할 수도 있다.
뭔가 익숙하다 했더니 이전에 MNIST 손글자 숫자 인식 모델만들 때 사용했었다 ㅎㅎ!
들어가보면 정답 레이블의 형태를 바꾸는 과정에서 사용된 것을 확인할 수 있을 것이다.
그래도 간단하게 사용하는 방법을 확인해보면 아래와 같다.
class_vector = [2, 6, 6 , 1]
from tensorflow.keras.utils import to_categorical
out = to_categorical(class_vector, num_classes = 7, dtype = "int32")
print(out)
이 방법이 제일 간단하고 단순해보이지만 사실 class_vector를 먼저 정수 인코딩한 후에 해야한다. 이 과정을 생략해서 짧아보이는 듯!
이번 시간엔 가중치 값을 정의하는 여러 방법과 범주형 데이터를 처리하는 과정에 대해서 알아보았다.
범주형 데이터를 처리할 일을 많을 것같아서 꼭 알아둬야할 것같다!
sklearn 라이브러리나 Keras를 사용해야 하고,
sklearn라이브러리에서는 LabelEncoder객체 혹은 OneHotEncoder객체,
Keras에서는 to_categorical() 메서드를 사용한다.
