오늘 학습 키워드
-
코드카타
-
템플릿
-
STL
코드카타
to_string()
-
to_string은 문자열로 만들어 반환하지만 임시객체를 반환 -
즉, 해당 함수가 있는 code가 끝나면 임시객체가 사라짐
-
따라서 아래와 같이 사용할 경우 sv는 임시객체를 참조하고 있으므로 이 코드가 끝나면 이상한 값을 참조하게 됨
std::string_view sv {to_string("123")}; - 그러므로 임시객체를 참조하지 말고
string으로 아예 객체를 생성해서 받아야 함
std::string s {to_string("123")};stoi()
-
그럼 문자열을 정수형으로 바꾸려면
stoi()를 쓰면 된다 -
atoi()의 경우char*를 인자로 받기 때문에string자료형을 사용할 수 없어, 대신에stoi()를 사용
int n {stoi("-12345")};템플릿
템플릿 함수
int,double,class등 자료형에 관계없이 일반적인 함수를 만들어 사용
using namespace std;
template <typename T>
T getMax(T a, T b) { return (a > b) ? a : b; }
template <typename T> // 템플릿 함수 정의부마다 앞에 선언
void printArray(T arr[], int size) { // 일반화 하고 싶은 곳만 T 써도 됨
for (int i = 0; i < size; i++)
cout << arr[i] << " ";
cout << endl;
}
int main() {
cout << getMax(10, 20) << endl; // 정수 비교
cout << getMax(3.5, 2.7) << endl; // 실수 비교
cout << getMax(string("apple"), string("banana")) << endl; // 문자열 비교
int intArr[3] = {1, 2, 3};
char charArr[4] = {'A', 'B', 'C', 'D'};
printArray(intArr, 3); // 정수 배열 출력
printArray(charArr, 4); // 문자 배열 출력
}- 템플릿 함수 내에서 변수의 자료형으로도 사용 가능
using namespace std;
template <typename T>
void swapValues(T &a, T &b) {
T temp = a; // 템플릿 자료형 사용
a = b;
b = temp;
}
int main() {
int x = 10, y = 20;
swapValues(x, y); // x = 20, y = 10
double p = 3.14, q = 2.71;
swapValues(p, q); // p = 2.71, q = 3.14
}- 템플릿으로 클래스를 받는 것도 가능함
class MyClass {
public:
void hello() { std::cout << "Hello from MyClass\n"; }
};
template <typename T>
void printHello(T obj) {
obj.hello();
}
int main() {
MyClass myObj;
printHello(myObj); // 정상 동작
}템플릿 클래스
- 클래스 내에서도 템플릿을 이용하여 선언 가능
using namespace std;
template <typename T>
class Array {
T data[100]; // 템플릿 사용. 다양한 자료형 배열 생성 가능
int size;
public:
Array() : size(0) {}
void add(const T& element) {
if(size < 100)
data[size++] = element;
}
void remove() {
if(size > 0)
size--;
}
};
int main() {
Array<int> arr; // 정수형 배열 생성
arr.add(10);
arr.remove();
Array<double> arr1; // double형 배열로 생성
}알아두기
-
템플릿 클래스나 함수는 컴파일 타임에 특정 타입으로 인스턴스화되고, 이때
T의 크기를 알게 되어 메모리 크기를 계산하여 할당 -
컴파일러는 소스 파일을 컴파일할 때 포함된 헤더 전체를 읽으므로, 템플릿 구현부(정의부)가 헤더에 있어야 읽고 다양한 타입에 대해 메모리 크기 계산과 코드 생성이 가능
STL
- Standard Template Library(표준 템플릿 라이브러리)의 약자로 3가지로 이루어짐
- Container
- Algorithm
- Iterators
Container
-
데이터를 담는 자료구조
-
모든 컨테이너는 템플릿으로 구현되어 있으므로, 다양한 타입의 데이터를 저장할 수 있다
-
모든 컨테이너는 메모리 관리를 내부적으로 하여 메모리 할당과 해제를 고려 안 해도 됨
Vector
-
배열과 비슷한 Container
-
삽입되는 원소 개수에 따라 내부 배열의 크기가 자동으로 조정
-
인덱스 접근 가능
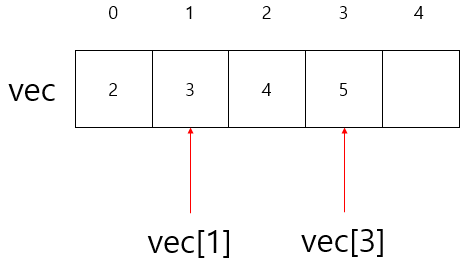
-
배열처럼 삽입 / 삭제는 맨 뒤에 하는 게 좋다. 중간 삽입 / 삭제는 비효율적
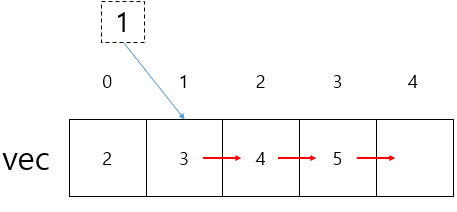
-
선언법
# include <vector> // vector 사용 위한 파일
using namespace std;
vector<int> vec1; // 초기화 없이 선언
vector<int> vec2(3, 5); // 크기 3, 모든 원소를 5로 초기화
vector<int> vec3 = { 5, 4, 2, 6 }; // 5, 4, 2, 6으로 초기화
vector<int> vec4(vec3); // vec3의 복사본을 새로운 메모리에 생성
vec1 = vec3; // 마찬가지로 vec3의 내용을 vec1에 복사
vector<vector<int>> vec2D(3, vector<int>(4, 7)); // 3x4 행렬, 모든 원소가 7로 초기화- 관련함수
using namespace std;
vector<int> vec1;
// 마지막에 원소 삽입
vec1.push_back(10);
vec1.push_back(20);
vec1.push_back(30);
for (int num : vec1) // 각 원소를 받는 반복문
cout << num << " ";
vec1.pop_back(); // 마지막에 있는 원소 제거
cout << vec1.size() // 원소 개수 (2개)
// 반복자를 제거해주는 erase (비효율적)
vector<int> vec = {10, 20, 30, 40, 50};
vec.erase(vec.begin() + 1); // 2번째 원소 제거 (10, 30, 40, 50)
vec.erase(vec.begin() + 1, vec.begin() + 3); // 2~4 번째 요소 제거 (10, 50)Map
-
Key를 사용하여 Value를 검색하는 기능을 제공하는 "연관 컨테이너"
python의 Dictionary와 비슷 -
키-값 쌍은
<Key, Value>형태로 저장 -
키값 기준 오름차순으로 자동으로 정렬(추가, 제거되어도 정렬 유지)
-
키값의 중복은 안 됨
-
사용법
#include <map> // map 사용 위한 파일
using namespace std;
map<int, string> nameTable; // key는 int로, value는 string으로
nameTable[100] = "Alice";
nameTable[102] = "Bob";
nameTable[101] = "Charlie"; // key 기준 오름차순 정렬(100, 101, 102)
for (const auto& pair : nameTable)
// first로 key값을 받고, second로 value 받음
cout << pair.first << ": " << pair.second << endl;
map<int, string> myMap;
// insert로 pair 추가하기
myMap.insert(make_pair(1, "Apple")); // make_pair로 pair만들어 insert로 추가
myMap.insert({2, "Cherry"}); // 중괄호로 pair 만들어 insert로 추가- 관련 함수
map<int, string> myMap = { // 직접 초기화도 가능
{1, "Apple"},
{2, "Banana"},
{3, "Cherry"}
};
int key = 2;
// find로 key값을 찾으면 iterator를 반환, 없다면 map.end()를 반환
auto it = myMap.find(key);
if (it != myMap.end())
cout << "Found! Key: " << it->first << ", Value: " << it->second << endl;
else
cout << "Key " << key << " not found!" << endl;
cout << myMap.size() << endl; // 크기 3을 반환
cout << myMap.erase(3); // 키값 3을 제거. 성공하면 1, 실패하면 0 반환
myMap.clear(); // 모든 pair 제거Algorithm
Sort
-
sort(시작 주소, 마지막 주소, comp함수): 시작주소의 원소부터 마지막 주소의 원소를 제외한 그 앞에까지 오름차순으로 정렬. comp함수를 정의함으로써 원하는대로 정렬방법 설정 가능 -
comp함수: true를 반환하면 순서 유지, false 반환하면 순서 바꿈
bool comp(int a, int b) {return a < b;}- 배열
bool comp(int a, int b) {return a > b;}
int arr[] = {5, 2, 9, 1, 5, 6};
sort(arr, arr + 6); // 오름차순 정렬
sort(arr, arr + 6, comp); // 내림차순 정렬- 벡터
vector<int> vec = {5, 2, 9, 1, 5, 6};
sort(vec.begin(), vec.end()); // 오름차순 정렬
sort(vec.begin(), vec.end(), compare); // 내림차순 정렬- class에도 사용 가능
class Person {
private:
string name;
int age;
public:
Person(string name, int age) : name(name), age(age) {}
string getName() const { return name; }
int getAge() const { return age; }
};
// 나이 오름차순 → 이름 오름차순
bool compareByAgeAndName(const Person& a, const Person& b) {
if (a.getAge() == b.getAge())
return a.getName() < b.getName(); // 이름 오름차순
return a.getAge() < b.getAge(); // 나이 오름차순
}
int main() {
vector<Person> people = {
Person("Alice", 30),
Person("Bob", 25),
Person("Charlie", 35),
Person("Alice", 25)
};
sort(people.begin(), people.end(), compareByAgeAndName);
}- class 내에 비교함수가 있을 경우
sort는 정적 함수나 함수 객체, 또는 람다를 기대하지만, 멤버 함수(비정적)는 인스턴스(this 포인터)가 필요하므로 불가능. 따라서 static을 붙여 정적 함수로 변경
class myClass
{
public:
void process(vector<int>& vec)
{
sort(vec.begin(), vec.end(), comp);
}
// static을 해줘야 함
static bool comp(const int& a, const int& b) { return a > b; }
};find
-
컨테이너 내부에서 특정 원소를 찾아 해당 원소의 반복자를 반환하는 함수
-
find(first, last, 찾을 값)과 같이 사용
-
마찬가지로 last 앞의 원소까지 찾으며 찾으면 해당 원소의 반복자를 반환, 못 찾으면 last 반복자를 반환
-
벡터
vector<int> vec = {10, 20, 30, 40, 50};
auto it = find(vec.begin(), vec.end(), 30); // 30 찾기
if (it != vec.end()) // 찾았으면
cout << "값 30이 벡터에서 발견됨, 위치: " << (it - vec.begin()) << endl;
// 해당 원소의 인덱스 값 출력 (2)- 배열
int arr[] = {1, 2, 3, 4, 5};
int size = sizeof(arr) / sizeof(arr[0]);
auto it = find(arr, arr + size, 4);
if (it != arr + size) {
cout << "값 4가 배열에서 발견됨, 위치: " << (it - arr) << endl;
} else {
cout << "값 4가 배열에 없음" << endl;
}- 문자열
string str = "hello world";
// 문자 'o' 찾기
auto it = find(str.begin(), str.end(), 'o');
if (it != str.end()) {
cout << "문자 'o'가 문자열에서 발견됨, 위치: " << (it - str.begin()) << endl;
} else {
cout << "문자 'o'가 문자열에 없음" << endl;
}