오늘 학습 키워드
-
덱
-
Unordered_map
-
탐색시간
-
재귀함수
1. 덱
-
vector와 마찬가지로,
begin()은 맨 앞의 원소를 가리키고,end()는 맨 뒤의 원소를 가리킴 -
배열처럼 연속적인 메모리를 가지는 배열과 달리, 덱은 여러 개의 청크(chunk)라고 불리는 영역으로 쪼개져 있음
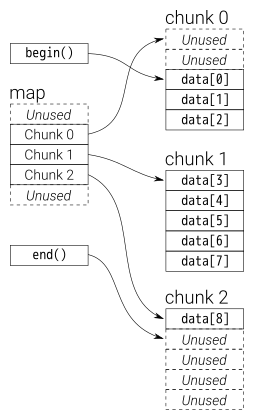
-
벡터는 맨 앞에 원소를 삽입하거나 삭제할 때, 그 뒤의 원소들의 위치를 다 바꿔줘야해서 오래걸리지만, 덱은 청크로 나누어져있으므로 첫 번째 원소에 대한 삽입, 삭제가 용이 O(1)
-
capacity 꽉 찰 경우 벡터의 경우 더 큰 메모리를 할당받고 다 복사하는 과정이 필요하지만, 덱은 청크단위이므로 청크 하나만 더 할당하면 되어서 더 효율적
-
다만,
[]를 이용한 임의접근에서는 벡터가 좀 더 빠름.
내부적으로 메모리가 떨어져있기에, map을 들어가고 청크를 또 들어가는 과정이 있어서 -
따라서, 맨 앞 요소 수정이 빈번할 경우 덱을 사용
#include <iostream>
#include <deque>
using namespace std;
int main() {
deque<int> d;
// 데이터 추가
d.push_back(10); // 뒤에 10 추가
d.push_front(20); // 앞에 20 추가
cout << << d.front() << endl; // 20
cout << "<< d.back() << endl; // 10
// 인덱스 접근
cout << d[1] << endl; // 10
cout << d.at(0) << endl; // 20
// 데이터 삭제
d.pop_front(); // 앞쪽 20 삭제
d.pop_back(); // 뒤쪽 10 삭제
// 비었는지 확인
if (d.empty()) cout << "empty" << endl;
}
2. Unordered_map
-
map은 레드블랙트리구조로, 항상 정렬된 상태를 유지. 따라서 삽입, 삭제, 검색에 O(logN)이 걸림 -
Unordered_map은 해시구조로, 정렬은 안 되지만, 삽입, 삭제, 탐색 다 O(1)이 걸림 -
사용법은
map과 거의 동일
#include <unordered_map>
std::unordered_map<int, std::string> unorderedMap;3. 탐색 시간(find())
-
vector: 모든 원소를 돌며 찾아야하므로 O(N)
-
set, map: 정렬되어 있으므로 O(logN)
-
unordered_set, unordered_map: 해시이므로 O(1)
-
따라서 정렬이 필요하냐 없냐도 중요하지만, 탐색을 얼마나 자주하느냐도 자료구조 결정에 영향을 끼침
4. 재귀함수
- 재귀함수의 호출 과정은 스택구조를 따르기에, DFS(깊이우선탐색), 백트래킹 등 스택 기반 알고리즘을 구현할 때 재귀함수를 사용하면 효율적이다
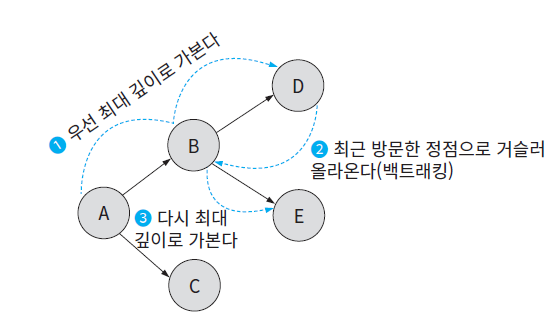
-
자식 노드를 재귀호출을 통해 방문할 수 있고, 형제 노드의 경우 반복문을 통해 접근. 후에 자식 노드들의 방문이 다 끝나면 스택구조에 따라 자동으로 부모 노드로 반환
-
반복문과의 장단점
| 특성 | 재귀 함수 | 반복문 |
|---|---|---|
| 정의 | 함수가 자기 자신을 호출하여 작업을 수행하는 방식입니다. | for, while 등의 제어 구조를 사용하여 작업을 반복 수행하는 방식입니다. |
| 메모리 사용 | 각 함수 호출 시 스택 메모리를 사용하며, 호출이 깊어지면 스택 오버플로우가 발생할 수 있습니다. | 스택 메모리를 사용하지 않으며, 일반적으로 메모리 사용이 효율적입니다. |
| 실행 속도 | 함수 호출과 복귀를 위한 컨텍스트 스위칭으로 인해 반복문보다 느릴 수 있습니다. | 함수 호출 없이 반복을 수행하므로 일반적으로 빠른 실행 속도를 가집니다. |
| 가독성 | 코드가 간결하고, 특히 알고리즘이 재귀적으로 표현되기에 자연스러운 경우 가독성이 높습니다. | 코드 길이가 길어질 수 있으며, 많은 변수를 사용하게 되어 가독성이 떨어질 수 있습니다. |
| 변수 사용 | 상태를 유지하기 위해 추가적인 변수를 사용하지 않아도 되어 코드가 간결해집니다. | 상태 유지를 위해 여러 변수를 사용해야 할 수 있어 코드가 복잡해질 수 있습니다. |
| 무한 반복 시 | 종료 조건을 잘못 설정하면 스택 오버플로우가 발생할 수 있습니다. | 종료 조건을 잘못 설정하면 CPU를 계속 사용하게 되어 시스템에 부하를 줄 수 있습니다. |
다음 학습
-
C++ 코딩테스트
-
git local->github 실습해보기
