오늘 학습 키워드
-
LIS
-
그리디 알고리즘
1. LIS
-
배열
arr이 주어졌을 때,arr의 요소들 간의 순서는 지키면서 요소가 증가하는 배열을 증가 부분 수열이라고 함
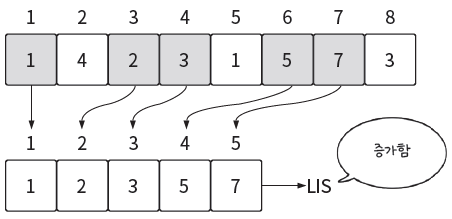
-
완전 증가여야하므로, {1, 1, 2}은 안 된다.
-
이 증가 부분 수열 중 가장 긴 길이를 가지는 부분 수열을 최장 증가 부분 수열 (LIS)이라고 부른다
O(N²) 알고리즘
-
DP를 이용하여 푸는 알고리즘
-
배열의 앞에서부터 시작하여 각 원소로 끝나는 LIS를 저장
-
N번째 요소로 끝나는 LIS는
- 이전의 (0~N-1) LIS들 중 마지막 원소보다 N번째 요소가 커야하며
- 이 조건을 만족시키는 앞의 LIS들 중 가장 긴 LIS에다가 N번째 요소를 붙이면 된다
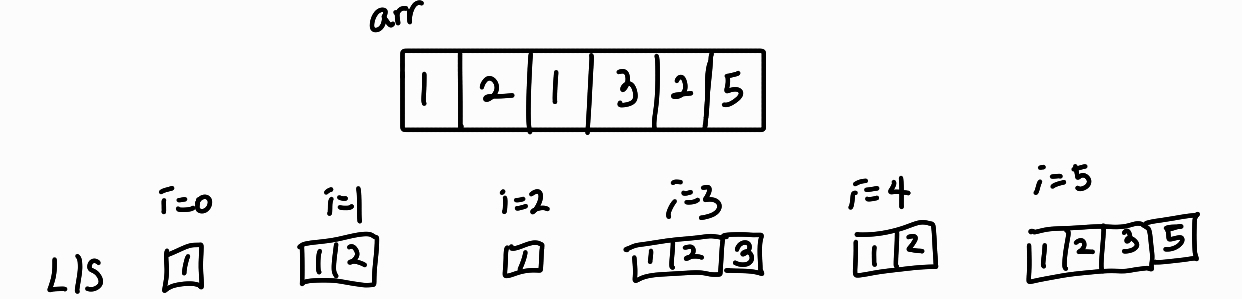
-
그리고 최종 답은 이 LIS들 중 가장 긴 LIS가 정답이다.
vector<int> nums = {1, 2, 1, 3, 2, 5};
vector<int> lis(nums.size(), 1);
for (int i = 1; i < nums.size(); i++) {
for (int j = 0; j < i; j++) { // 앞의 LIS들 중
if (nums[i] > nums[j]) // N번째 요소가 더 크면
lis[i] = max(lis[i], lis[j] + 1); // 최대값 갱신
}
}
return *max_element(lis.begin(), lis.end()); // LIS 중 최대값O(NlogN) 알고리즘
-
이전의 LIS들을 탐색하는 과정을 이진탐색(logN)으로 줄여 NlogN으로 만든 알고리즘
-
LIS를 만드는 과정에서 LIS의 마지막 원소가 최대한 작아야 더 긴 LIS를 만들 수 있다
-
그래서 이전과는 다른 새로운 배열 lis를 사용
- lis배열의 요소값은 "해당 길이의 증가 수열 중에서 마지막 원소 값의 최소값"
- lis 배열의 i번째 원소는 길이가 i+1인 증가 수열 중 가장 끝 숫자가 작은 값을 저장
- 새로 lis에 추가할 원소가
- lis의 마지막 원소보다 크면 lis 뒤에 추가
- 작다면, lis에서 자신보다 큰 수 중 가장 작은 수와 교체
-
예제) arr = [3, 5, 2, 6, 1]
- K = [3]
- K = [3, 5] (5 > 3)이므로 lis에 추가
- K = [2, 5] (2 < 5)이므로 3과 교체
- K = [2, 5, 6] (6 > 5)이므로 추가
- K = [1, 5, 6] (1 < 6)이므로 2와 교체
- 즉 길이가 (
1,2,3)인 증가부분수열들의 가장 작은 마지막 요소값이{1, 5, 6}라는 뜻.
-
lis 배열은 실제 부분수열을 저장하는 게 아니라, "길이별 최적의 증가 수열 끝값들"을 저장
// 이진 탐색 후 원소값 교체
void change(int x, vector<int>& lis) {
int start = 0, end = lis.size() - 1;
int mid, target, dist = 100000000;
while (start <= end) {
mid = (start + end) / 2;
if (lis[mid] == x)
return;
if (lis[mid] < x) {
start = mid + 1;
continue;
}
if (dist > abs(x - lis[mid]))
{
dist = abs(x - lis[mid]);
target = mid;
}
end = mid - 1;
}
lis[target] = x;
}
int solution(const vector<int> nums) {
vector<int> lis = {nums[0]};
for (const auto& x : nums) {
if (x > lis.back()) { // 크면 넣어주고
lis.push_back(x);
}
else if (x < lis.back()) {
change(x, lis); // 아니면 바꾸기
}
}
return lis.size();
}- 이 알고리즘은 LIS의 길이를 구하는 알고리즘으로, 실제 LIS배열을 구하고 싶다면 추가적인 작업이 필요하다
2. 그리디 알고리즘
-
매 단계에서 '지금 당장 가장 좋은 선택'을 하는 방식
-
전체 문제를 한꺼번에 고려하지 않고, 현재 상황에서 최적의 선택을 해서 문제를 해결
-
문제의 해결법이 그리디 알고리즘이려면
- 지금 당장 한 선택이 최적해의 일부일 수밖에 없음을 보임.
- 문제를 여러 부분 문제로 나누었을 때, 각각의 부분 문제도 최적해를 갖는 성질 증명.
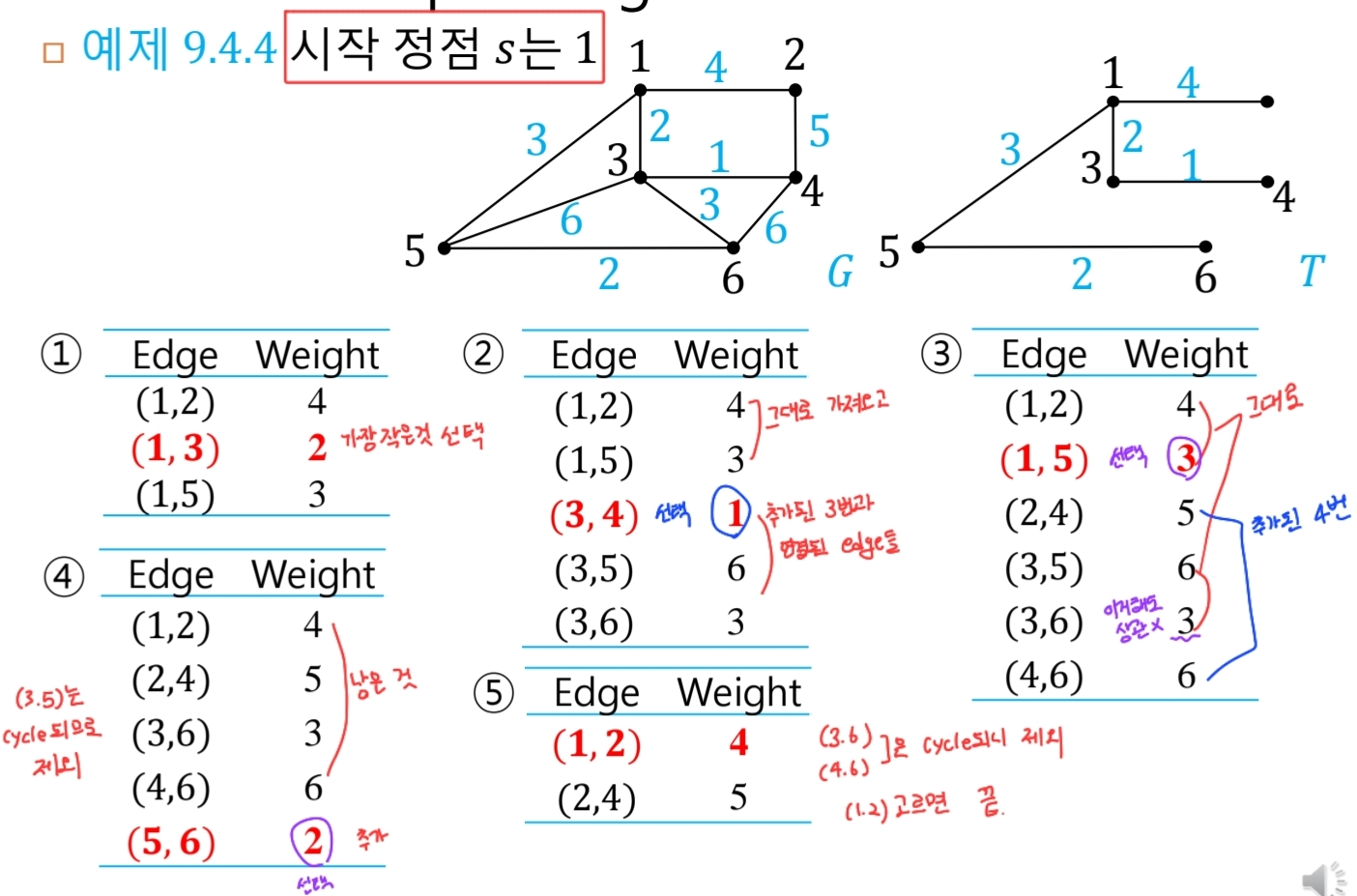
최소 신장 트리 (MST)
-
T가 그래프 G의 모든 정점을 포함하는 부분 그래프로 트리이면(cycle 없으면), T는 G의 신장 트리이다.
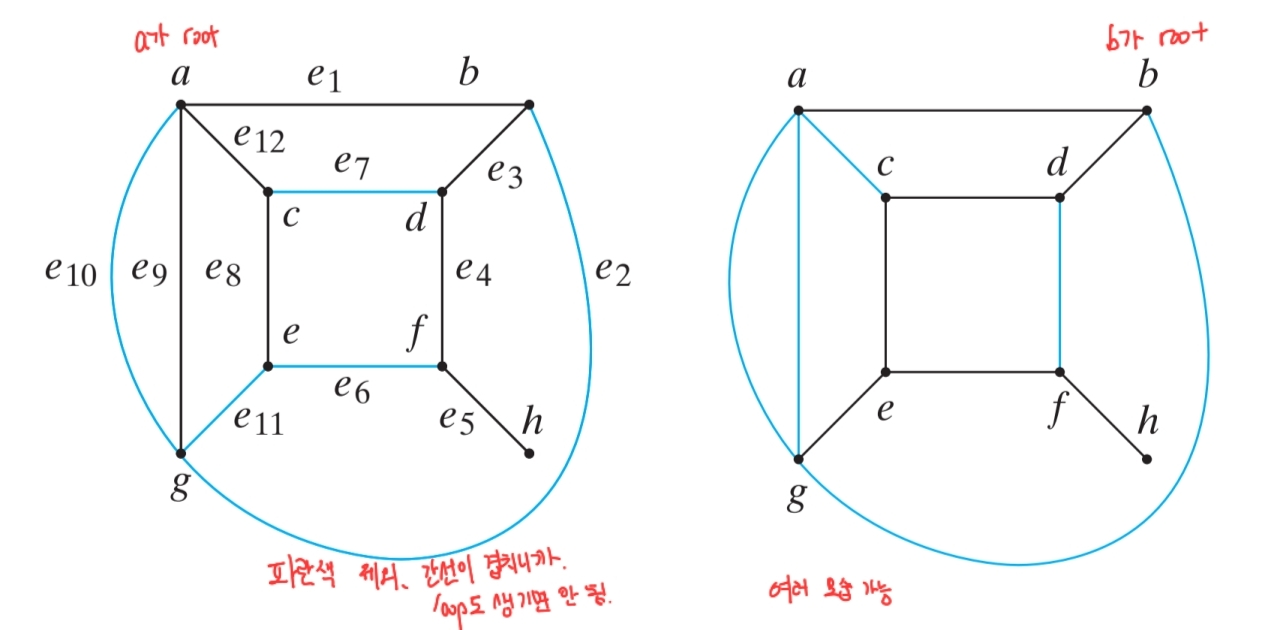
-
신장 트리의 간선의 개수는 무조건 V - 1개. 그 이상이면 cycle이 생기고, 그 이하이면 모든 정점을 포함하지 못 한다.
-
이 신장 트리 중 간선의 가중치의 총합이 가장 작은 트리를 최소 신장 트리라 함
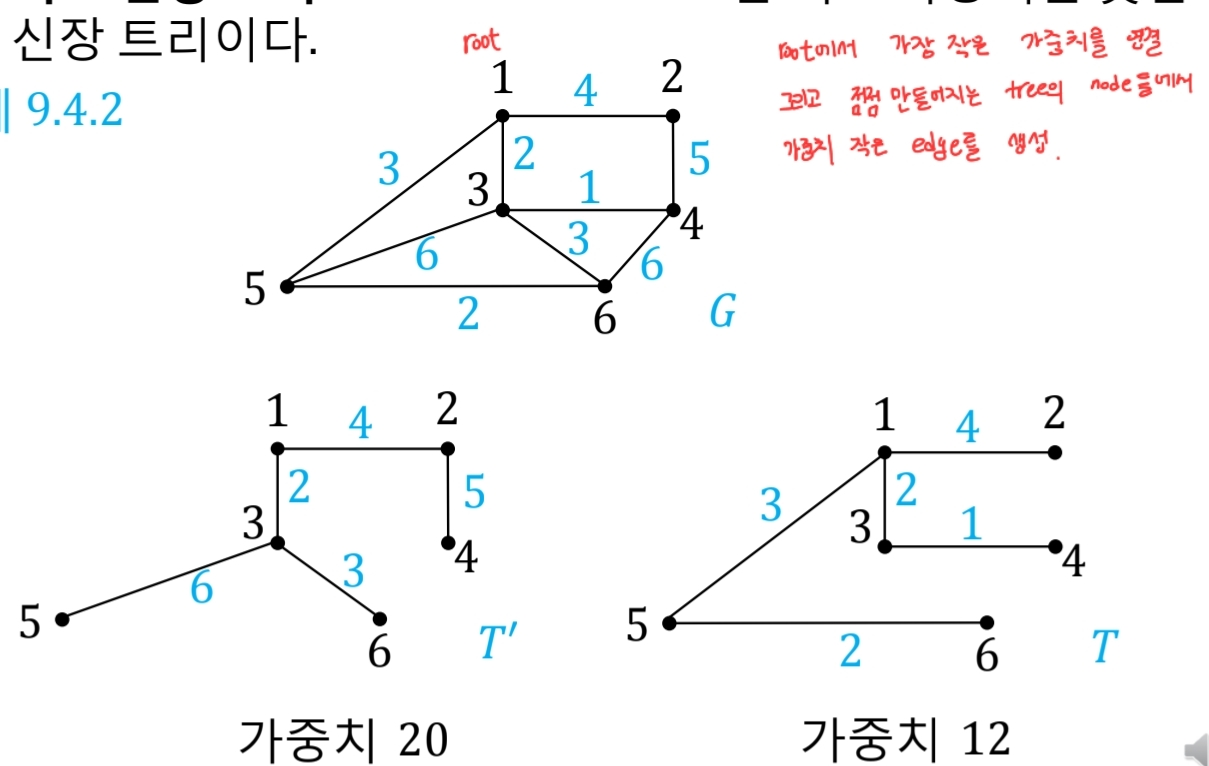
프림 알고리즘
-
최소 신장 트리를 만드는 알고리즘(그리디) O(ElogV)
-
시작 정점을 신장트리에 넣고, 신장트리에 있는 정점으로부터 가중치가 가장 작은 정점들(신장트리에는 없는)을 신장트리에 넣으면 된다.
-
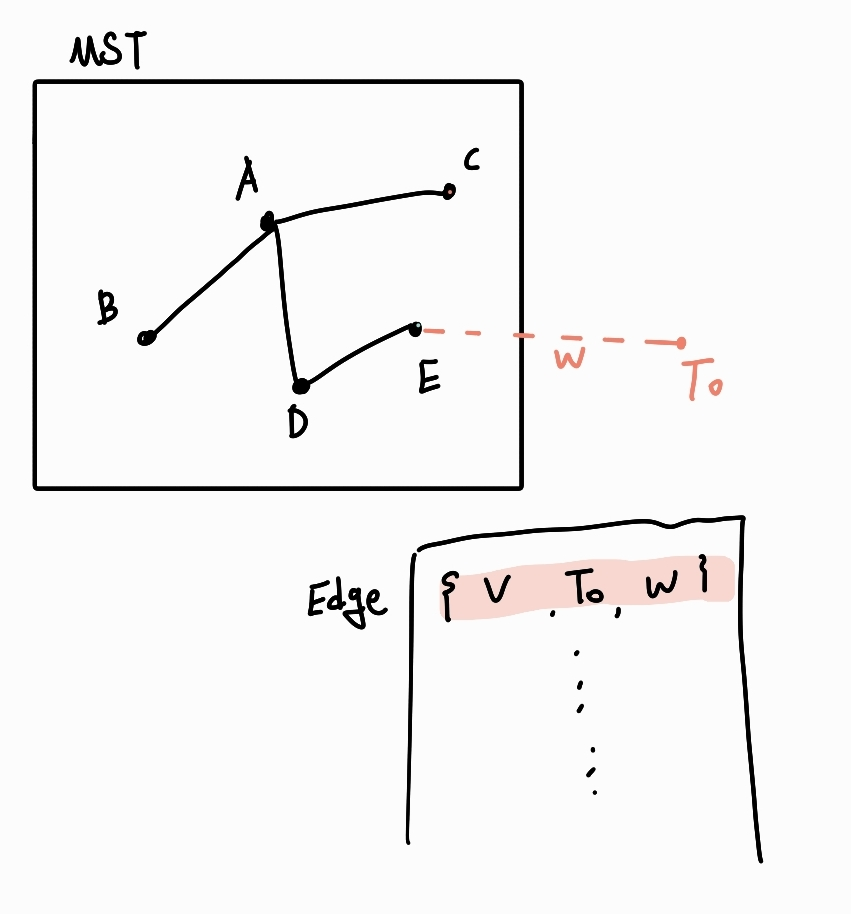
그리디로 풀리는 이유:
-
그리디는 현재 MST에 들어있는 정점들의 간선들 중 최소가중치인 간선을 택함
(V, To, w)현재w가 가장 최소 가중치.
-
그리디가 틀렸다고 가정해보자. 즉, 이 간선을 택하지 않는 것이 MST를 만드는 방법
-
그렇다면,
To는 현재 MST에 있는 정점이 아니라 아직 MST에 포함되지 않은 다른 정점(V')으로부터 이어져야 함.
왜냐하면, MST에 있는 다른 정점에서 이어진다면 가중치가w보다 높으므로 애초에 MST가 안 됨.
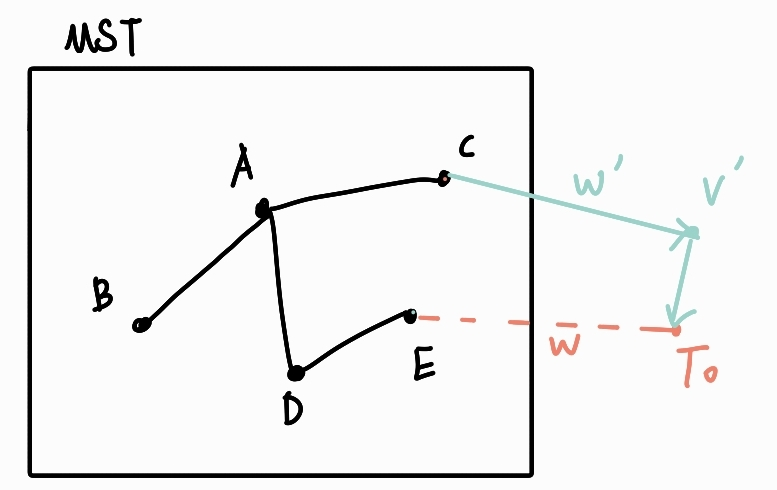
-
그럼 나중에
V'도 MST에 추가가 될 것이고, 그 때To가 연결되며 MST에 들어올 것이다. -
하지만 그림에서도 볼 수 있듯이,
w'은w보다 큼.
애초에 처음 MST에서 가장 작은 가중치가w였기 때문. -
즉,
C->V'->To가 아니라E->To->V'로 연결되어야 MST가 됨.
따라서 모순이 발생하므로 그리디로 푸는 것이 옳다
-
using namespace std;
const int MAX = 100;
const int INF = 1000000000;
int cost[MAX][MAX]; // 인접 행렬: 간선의 비용 저장
bool visited[MAX]; // 방문 여부
struct comp {
bool operator() (const vector<int>& a, const vector<int>& b) {
return a[2] > b[2];
}
};
int main() {
int V = 5; // 정점의 개수
// 간선 비용 초기화 (없는 간선은 INF)
for (int i = 0; i < V; i++) {
for (int j = 0; j < V; j++) {
cost[i][j] = INF;
}
}
// 예시 간선들 (무방향 그래프)
cost[0][1] = cost[1][0] = 2;
cost[0][3] = cost[3][0] = 6;
cost[1][2] = cost[2][1] = 3;
cost[1][3] = cost[3][1] = 8;
cost[1][4] = cost[4][1] = 5;
cost[2][4] = cost[4][2] = 7;
cost[3][4] = cost[4][3] = 9;
// {from, to, weight}. 가중치 기준 minHeap
priority_queue < vector<int>, vector<vector<int>>, comp> mQ;
for (int i = 0; i < V; i++) {
if (cost[0][i] != INF)
mQ.push({0, i, cost[0][i]}); // 0번 정점의 간선으로 시작
}
visited[0] = true;
vector<int> top;
int from, to;
int E = 0;
while (E < V - 1) { // 간선 V - 1개 생성
top = mQ.top();
mQ.pop();
if (visited[top[1]])
continue;
from = top[0];
to = top[1];
visited[to] = true;
for (int i = 0; i < V; i++) {
if (cost[to][i] != INF)
mQ.push({ to, i, cost[to][i] }); // 해당 정점의 간선들 후보로 추가
}
E++;
}
return 0;
}크루스칼 알고리즘
-
마찬가지로 그리디 방식
-
프림 알고리즘은 정점을 기준으로 MST를 만들었다면, 크루스칼은 간선 기준.
- 간선을 가중치 순으로 오름차순 정렬 후 작은 것부터 고르며 MST 생성
- 선택한 간선의 정점 2개가 같은 서로소 집합에 있다면 cycle이므로 건너뜀
- 마찬가지로 V - 1번 택하면 된다.
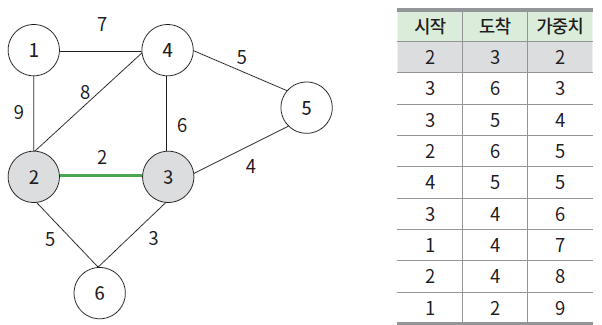 | (2, 6, 5)의 경우 이미 연결되어 있어 건너띔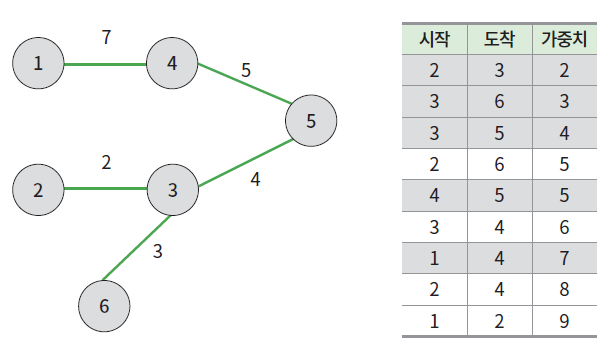 |
|---|
-
cycle이 생기는 지 확인하는 법은 서로소 집합을 사용.
단순 방문 정보로는 cycle을 확인할 수 없기 때문
정점 추가 시 서로 다른 집합의 정점이면 서로소 집합 합쳐줌 -
시간 복잡도: 간선 정렬에 O(ElogE)가 소요되고, Union-Find 연산은 O(α(V))로 매우 빠름. O(ElogE) 수준이다.
using namespace std;
// 간선 정보를 담는 구조체
struct Edge {
int u, v, weight;
// 간선 정렬 (가중치 오름차순)
bool operator<(const Edge& other) const {
return weight < other.weight;
}
};
// 서로소 집합에서 부모 찾기 (경로 압축)
int findParent(vector<int>& parent, int x) {
if (parent[x] == x) return x;
return parent[x] = findParent(parent, parent[x]); // 부모 바로 찾기 가능
}
// 서로소 집합 합치기 (union)
bool unionParent(vector<int>& parent, int a, int b) {
a = findParent(parent, a);
b = findParent(parent, b);
if (a == b) return false; // 이미 같은 집합이라 사이클 생김
if (a < b) parent[b] = a;
else parent[a] = b;
return true;
}
// 크루스칼 알고리즘 함수
int kruskal(int n, vector<Edge>& edges) {
vector<int> parent(n);
for (int i = 0; i < n; ++i)
// 초기에는 각 정점이 자신의 서로소집합에 속함
// 그리고 그 집합의 루트는 자기 자신
parent[i] = i;
sort(edges.begin(), edges.end()); // 가중치 기준 오름차순 정렬
int mst_weight = 0; // MST 가중치 합 계산용
for (auto& edge : edges) {
if (unionParent(parent, edge.u, edge.v)) {
mst_weight += edge.weight;
}
}
return mst_weight;
}
int main() {
int n = 4; // 정점 수
vector<Edge> edges = {
{0, 1, 1},
{0, 2, 4},
{1, 2, 2},
{1, 3, 3},
{2, 3, 5}
};
int result = kruskal(n, edges);
cout << "최소 신장 트리의 가중치 합: " << result << "\n";
return 0;
}