1. 선형 회귀(Linear Regression)
회귀 문제란?
- 주어진 데이터포인트 x에 해당하는 실제 값으로 주어지는 타겟 y를 예측하는 문제
- 예) 주택 가격, 기온, 판매량 등과 같은
연속된 값을 예측하는 문제
기본 요소들
선형 회귀는 선형 예측 함수를 사용해 회귀식을 모델링하며, 알려지지 않은 파라미터는 데이터로부터 추정한다
선형 모델
집의 면적과 지어진 후 몇 년이 되었는지를 입력으로 사용해서 주택 가격을 예측해보자!
간단해 보이지만 두 개 이상의 입력 변수가 사용되는 경우 굉장히 긴 공식이 된다. 하지만 벡터를 사용하면 간단하게 표현가능.
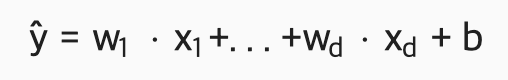
- x = 데이터 포인트들
- y = 타겟 변수
- d = 변수의 갯수
데이터 포인트 xi와 이에 대한 label값인 yi를 추정해서 연관시켜주는 가중치(weight) 벡터 w와 bias b를 찾아보는것으로 시도. ŷ =w⊤x+b로 나타낼수 있다.
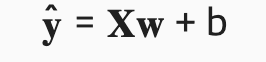
또한 데이터 포인트들의 집합 X와 예측값은 위에 같은 행렬벡터 곱의 공식으로 나타낼수 있다.
이에 따라 x와 y의 관계가 선형적이라고 가정하는것은 합리적. 그래서 우리가 파라메터 w를 찾기 위해서는 모델의 품질을 정해야하고 그 품질을 향상시킬수 있어야 한다.
학습 데이터
여러 집들의 실제 판매가격과 그 집들의 크기와 지어진 후 몇 년이 지났는지에 대한 데이터가 필요!
머신러닝 용어
학습 데이터 or 학습 셋: 데이터 셋
샘플(sample): 하나의 집 (집과 판매가격)
레이블(lable): 그 집의 판매가격
피처(feature) 또는 공변량(covariate): 레이블을 예측하기 위해 사용되는 두 값. 피처는 샘플의 특징을 표현하는데 사용된다.
수집한 샘플의 개수를 n으로 표기라고 각 샘플은 인덱스 i를 사용해서 x(i)=[x(i)1,x(i)2] 로 표현하고 레이블은 y(i)로 표기
Loss 함수
모델 학습을 위해서는 모델이 예측된 가격과 실제 가격의 오차를 측정해야 한다! 보통 오차는 0 or 양수. 값이 작을 수록 오차가 적다는 의미! 오차 계산은 아래의 제곱함수를 이용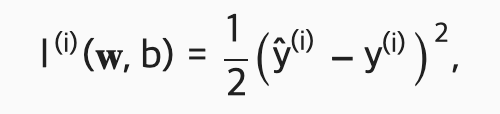
수식에 곱해진 1/2 상수값은 2차원 항목을 미분했을때 값이 1이 되게 만들어서 조금 . 더 간단하게 수식을 만들기 위해서 사용된 값! 오류값이 작을수록 예측된 값이 실제 가격과 더 더 비슷해지고 두 값이 같으면 오류는 0이 된다. 이 함수를 모델 파라미터를 파라미터로 갖는 함수라고 생각할 수 있다.
loss function : 오류를 측정하는 함수
square loss : 제곱 오류 함수
이제 집값이 집 크기에만 의존한다는 모델을 가정해서 일차원 문제로 회귀 문제를 도식화한 것으로 예시를 들어보자
의존성(quadratic dependence) 으로 인해서 예측값 ŷ (i)과 실제값 y(i)의 큰 차이는 loss에서 더 크게 반영이 된다. -> 전체 데이터셋에 대해서 모델의 품질을 측정하기 위해서 학습셋에 대한 loss의 평균값을 사용할 수 있다.
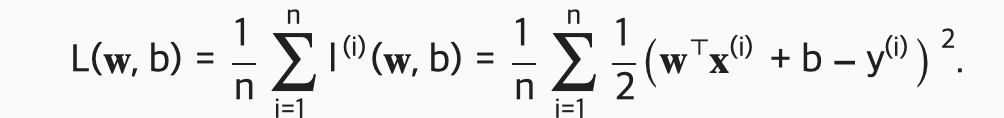
이제 여기서 학습 샘플들의 평균 loss를 최소화하는 모델 파라미터 w와 b를 찾는것이 모델을 학습시키는것!! (하.. 수학 진자 실타)

최적화 알고리즘
모델과 loss함수가 상대적으로 간단하게 표현되는 경우 앞에서 정의한 loss를 최소화하는 방법은 위에서 정리한 역행렬을 사용해서 명확한 수식으로 표현할 수 있다.
- 수학적 분석을 적용할 수 있다
- 간단한 경우에만 적용 가능
대부분 딥러닝 모델은 분석적 방법을 적용할 수 없기때문에 loss 함수의 값은 최적화 알고리즘을 사용해서 모델 파라미터를 유한한 횟수로 업데이트하면서 줄!이!는! 방법을 적용해야한다.
딥러닝에서는 산술적인 솔루션으로 미니배치를 적용한 확률적 경사 하강법 (stochastic gradient desecent) 방법이 널리 사용된다.
-
우선 일반적으로 난수를 이용해서 모델 파라미터를 초기화한다
-
데이터를 반복적으로 사용해서 loss 함수의 값을 줄이는 것을 반복한다.
-
각 반복에서는 학습 데이터에서 미리 정한 개수만큼의 샘플들을 임의로 또 균일하게 뽑아서 미니 배치를 구성하고 미니 배치의 값들에 대한 평균 loss값의 모델 파라미터에 대한 미분을 구한다
-
결과와 미리 정의된 스탭 크기 η> 0을 곱해서 loss값이 최소화 되는 방향으로 파라미터를 변경한다
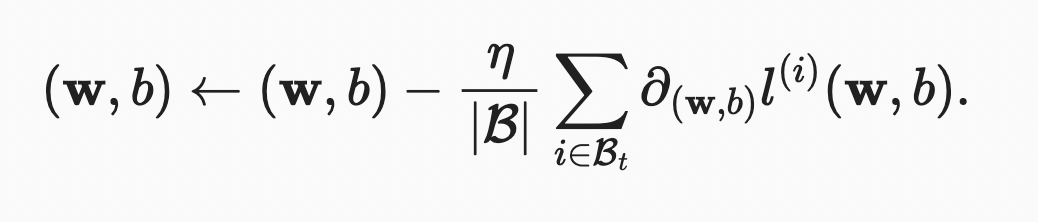
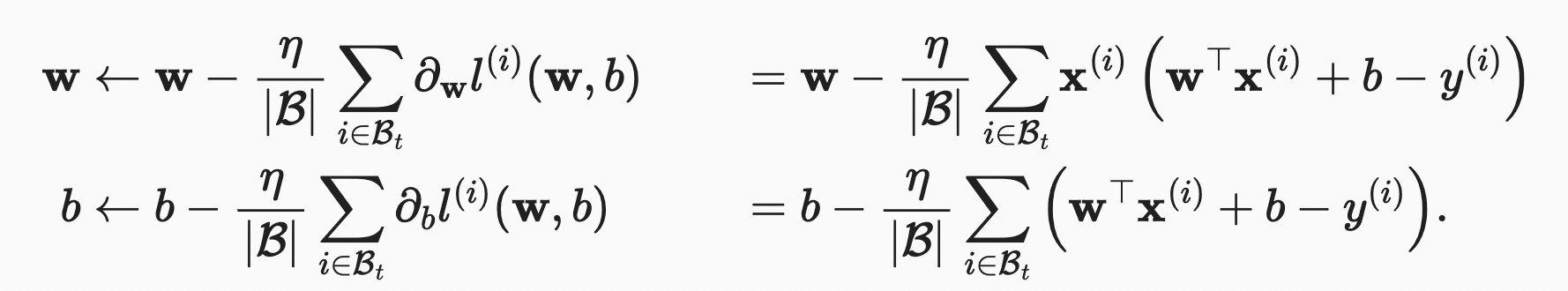
|B|: 각 미니 배치의 샘플 개수
η : 학습속도 (learning rate) -> 양수값 사용
미니배치 크기와 학습속도는 모델 학습을 통해서 찾아지는 값이 아니라 우리가 선택해야한다... 따라서 이 값들을 hyper-parameters라고 부름
모델을 이용한 예측
모델 학습이 끝나면 모델 파라미터 w,b에 해당하는 값 ŵ 와 b̂ 을 저장한다. 이후 학습된 선형 회귀 모델 ŵ⊤x+b̂ 을 이용해서 학습 데이터셋에 없는 집 정보에 대한 집 가격을 추정한다.
추정을 모델 예측(prediction) 또는 모델 추론(inference) 이라고 함
선형 회귀에서 딥 네트워크로
이제는 선형 함수만이 아닌 인공신경망에 대해서 이야기해보자. 모든것을 층(layer) 표기법으로 다시 기술 ㄱㄱ
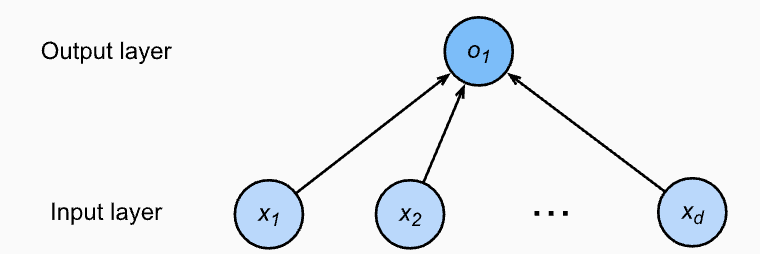
인공신경망 다이어그램
인공신경망 다이어그램에서는 모델 파라미터인 가중치(weight)와 편형(bias)을 직접 표현하지 않는다.
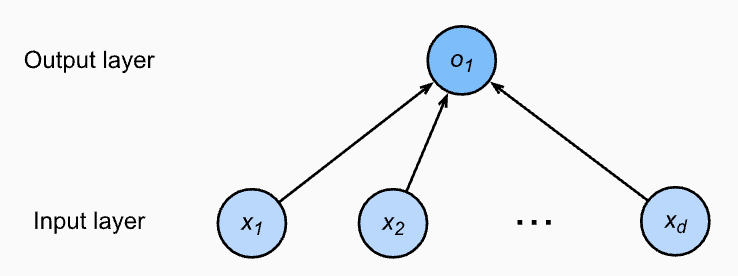
여기서의 입력값은 x1,x2,…xd이다.데이터를 표현하는 데 필요한 축을 Dimension이라고 할 수 있는데 이때 Feature의 갯수를 Dimension의 갯수라고 볼 수 있다.
이 경우는 입력값의 개수는 d 이고 출력값의 갯수는 1이다. 출력값을 선형 회귀 모델의 예측 결과로 그대로 사용한다. 입력 레이어에는 어떤 비선형이나 계산이 적용되지 않기 때문에, 이 네트워크의 총 레이어의 갯수는 1개이다. 종종 이런 신경망을 단일층 신경망이라고 부른다.
단일층 신경망
- 하나의 입력층과 하나의 출력층으로 구성된 인공신경망 모델
- 입력 데이터가 입력층으로 들어가면 출력층에서 결과가 출력된다
- 연결층에는 여러개의 뉴런이 존재한다
모든 입력들이 모든 출력들과 연결되어 있기 때문에 이 레이어는 완전 연결 계층(fully connected layer) 또는 밀집층(dense layer)라고 불린다
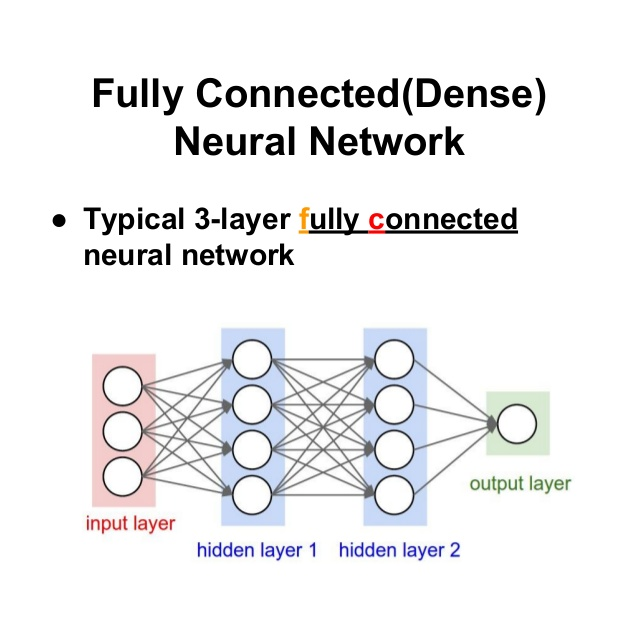
요약
- 머신러닝에서 중요한 요소는 학습 데이터, loss 함수, 최적화 알고리즘, 그리고 모델 자체
- 벡터화는 모든것을 좋게 만들고 코드를 빠르게 만들어준다
- objective 함수를 최소화하는 것과 maximum likelihood를 구하는 것은 같다
- 선형 모델도 신경망 모델이다
