2. 선형 회귀를 처음부터 구현하기
좋은 딥러닝 프레임워크를 이용하면 반복적인 일을 줄일 수 있지만 너무 프레임워크에 인존하면 딥러닝이 어떻게 동작하는지 이해하기 어렵게 될 수 있다. 따라서 NDArray 와 autograd만을 이용해서 선형 회귀 학습을 직접 구현해보자
먼저 필요한 패키지와 모듈을 import 하기!!
MXNet
MXNet은 딥러닝 프레임워크로 다양한 언어에서 사용할 수 있다. 자주 사용되는 두가지 핵심 개념이 있는데 'autograd'와 'NDArray'이다.
NDArray
- MXNet의 핵심 데이터 구조이다. N차원의 배열을 의미하며, numpy의 배열과 유사한 기능을 제공한다. NDArray는 다차원 배열을 효율적으로 처리하고 GPU 가속을 지원한다
import mxnet as mx
# CPU에서 NDArray 생성
a = mx.nd.array([[1,2,3], [4,5,6]])
print(a)
%matplotlib inline
from IPython import display
from matplotlib import pyplot as plt
from mxnet import autograd, nd
import randomautograd
- 자동미분 (automatic differentiation)을 위한 모율이다. 신경망의 학습에 필수적인 기울기(gradient)를 자동적으로 계산해준다.
from mxnet import autograd, nd
x= nd.array([1,2], [3,4])
x.attach_grad()
with autograd.record(){
y = x*2
z = y.sum()
z.backward()
print(x.grad)
데이터셋 생성하기
간단한 학습 데이터셋을 직접 만들어서 학습된 파라미터와 실제 모델의 파라미터의 차이를 시각적으로 비교해볼 . 수 있다. 일단! 학습 데이터셋의 샘플(sample) 개수를 1000개로 하고 특성(feature)개수는 2개로 하자.
임의로 생성한 배치 샘플 특성 X ∈ ℝ^(1000×2)와 실제 가중치 값 w = [2,-3.4]^T와 편향 (bias) b = 4.2를 사용하겠다. 그리고 임의의 노이즈 값 ϵ도 사용하자. 노이즈를 사용하면 실제 데이터를 더 현실적으로 만든다
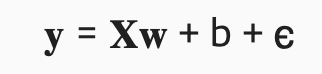
노이즈 항목ϵ은 평균이 0이고 표준편차가 0.01인 정규 분포를 따르도록 정의하자
num_inputs = 2 # 특성 개수
num_examples = 1000 # 학습 데이터셋의 샘플 개수
true_w = nd.array([2,-3.4]) #실제 가중치 값
true_b = 4.2 # 편향 (bias)
features = nd.random.normal(shape=(num_examples, num_inputs)) # 1000개의 데이터 샘플을 생성.
# 각 샘플은 평균이 0이고 표준편차가 1인 정규분포를 따르는 두 개의 특성을 가짐. 결과적으로 features는 (1000, 2) 형태의 배열이 됩니다.
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b #선형 방정식 𝑦 = 𝑤1𝑥1 + 𝑤2𝑥2 + 𝑏 에 해당
labels += nd.random.normal(scale=0.01, shape=labels.shape) #레이블에 약간의 노이즈(noise)를 추가. 노이즈는 평균이 0이고 표준편차가 0.01인 정규분포를 따른다features의 각 행은 2차원 데이터 포인트로 구성되고, labels의 각 행은 1차원 타겟 값으로 구성
features[0], labels[0]
features[:,1]과 labels를 이용해서 scatter plot을 생성해보면, 둘 사이의 선형 관계를 명확하게 관찰할 수 있다.
def use_svg_display():
#Display in vector graphics
display.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
#Set the size of the graph to be plotted
plt.rcParams['figure.figsize'] = figsize
set_figsize()
plt.figure(figsize = (10, 6))
plt.scatter(features[:,1].asnumpy(), labels.asnumpy(),1); 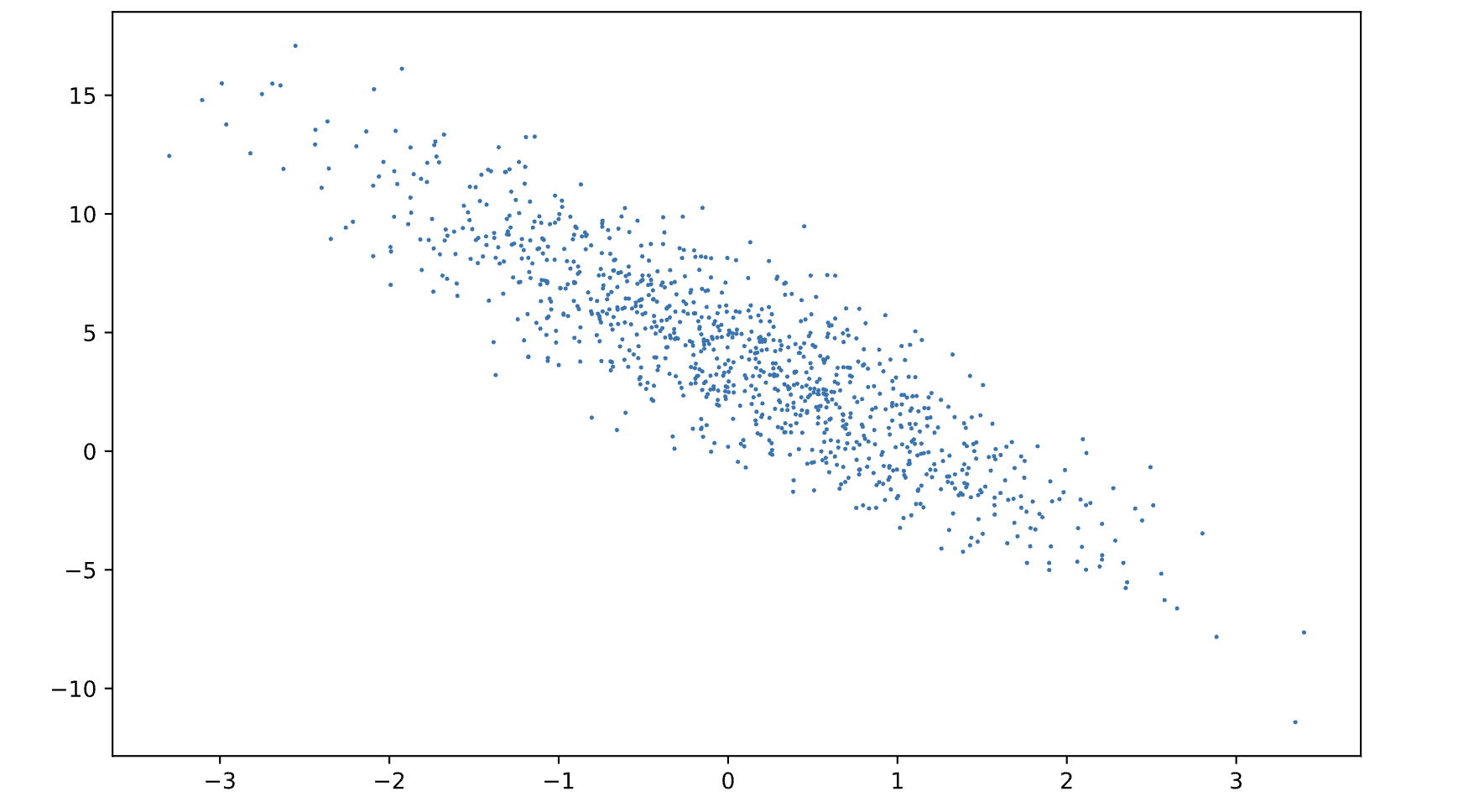
데이터 읽기
모델을 학습시킬때, 전체 데이터셋을 반복적으로 사용하면서 각 데이터의 미니 배치를 얻어야 한다. 아래 함수는 임의로 선택된 특성(feature)들과 태그(tag)들을 배치 크기의 개수만큼 리턴해주는 역할을 한다.
왜 한번에 하나의 샘플을 사용하지 않고 여러 샘플을 리턴하는 iterator를 작성할까?
- 그 이유는 최적화를 효율적으로 하기 위해서! 한번에 하나의 1차원 값을 처리했을때 성능이 아주 느렸다. 하나의 샘플을 처리하는 것처럼, 하나의 벡터가 아닌 행렬로 표현된 샘플들의 전체 배치를 한번에 처리하는 것도 동일하게 할 수 있다. 특히 GPU는 행렬을 다룰때 아주 빠른 속도로 연산을 수행한다. 이것이 딥러닝에서 보통 하나의 샘플 보다는 미니 배치 단위로 연산을 하는 이유 중 하나다.
#This function has been saved in the d2l package for future use
def data_iter(batch_size, features, labels): # 이 함수를 통해 데이터셋을 작은 배치 단위로 나누어 처리가능
num_examples = len(features) # 샘플 개수
indices = list(range(num_examples)) #데이터셋의 인덱스를 리스트로 만든다. 예를 들면 1000을 [0,1,2,,,999]
#The examples are read at random, in no particular order
random.shuffle(indices) # 샘플의 순서를 랜덤하게 섞음
for i in range(0, num_examples, batch_size): # batch size간격으로 반복. 예를 들면 batch_size가 10이면 num_examples가 1000이면 i는 0,10,20,,990
j = nd.array(indices[i: min(i + batch_size, num_examples)]) # 현재 배치의 인덱스를 선택. 마지막 배치는 데이터의 끝에 도달할 수 있으므로 min(i + batch_size, num_examples)로 범위 제한
yield features.take(j), labels.take(j) # 현재 배치의 특성과 레이블 잔환. take 함수는 주어진 인덱스에 해당하는 요소를 선택
# The "take" function will then return the corresponding element based on the indices첫번째 작은 배치를 읽어서 출력해보자! 각 배치의 특성(feature)들의 모양(shape)은 배치 크기와 입력 차원의 수와 연관된다. 배치 크기와 동일한 레이블(label)들을 얻는다
batch_size = 10
for x, y in data_iter(batch_size, features, labels):
print(x,y)
break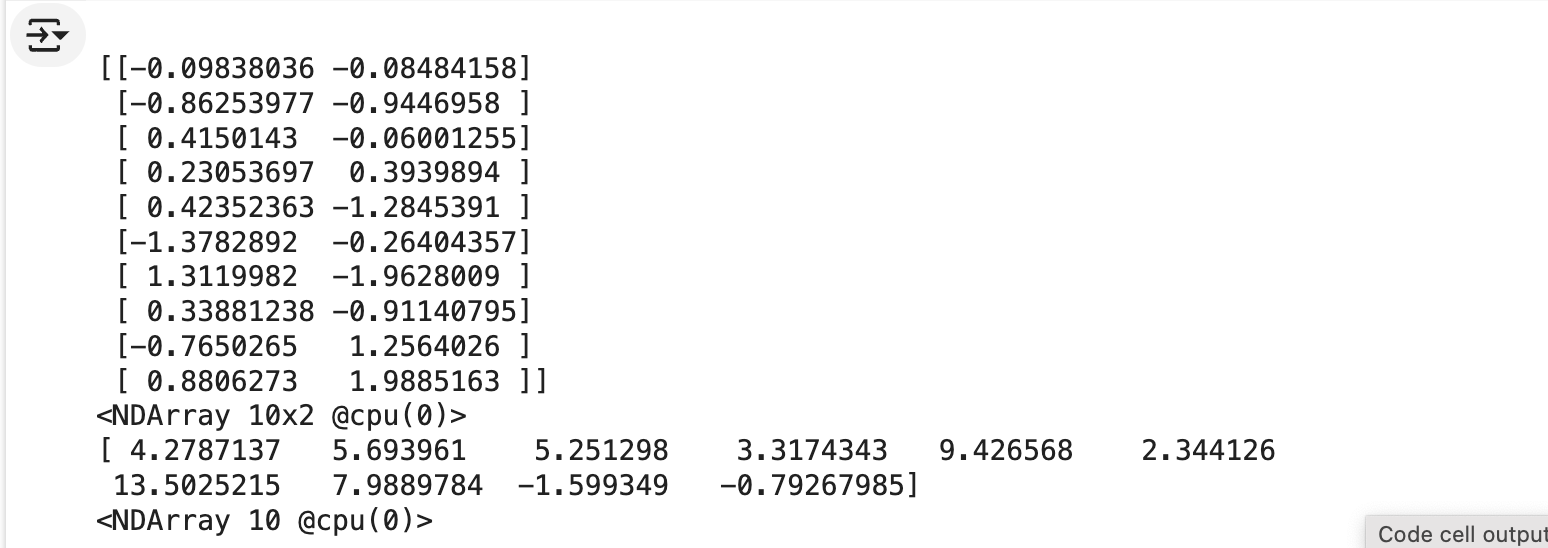
큰 데이터셋을 작은 배치로 나누어 처리할 수 있도록 하는 것이다. 이는 머신 러닝 모델 학습에서 일반적으로 사용되며, 특히 미니배치 경사하강법(mini-batch gradient descent)에서 유용합니다. data_iter 함수는 무작위로 섞인 데이터를 배치 단위로 제공하여 모델 학습 시 데이터 순서에 따른 편향을 줄여줍니다
모델 파라미터들 초기화하기
w = nd.random.normal(scale=0.01, shape=(num_inputs, 1)) # 표준편차(scale)가 0.01인 정규분포를 따르는 난수값들로 가중치 초기화
b = nd.zeros(shape=(1,)) # 편향 0으로 초기화모델이 데이터를 잘 예측할 수 있도록 파라미터들을 업데이트한다.
- 손실 함수(loss function)의 파라미터에 대한 gradient, 즉 다변수 미분을 구해야 한다. 손실 값을 줄이는 방향으로 각 파라미터를 업데이트 할 것이다.
autograd가 적당한 데이터 구조를 준비하고 변경을 추적할 수 있도록 gradient들을 명시적으로 붙여줘야한다. 머신러닝 모델을 학습시킬때, 손실함수의 기울기를 계산하여 가중치와 편향을 업데이트해야한다
# w와 b에 대한 기울기를 추적하고 저장할 수 있도록 한다
w.attach_grad()
b.attach_grad()모델 정의하기
아주 간단한 인공신경망 선형 모델을 정의하자. 선형 모델의 결과를 계산하기 위해서, 입력 값과 모델의 가중치 w를 곱하고 offset b를 더한다
def linreg(x,w,b) :
return nd.dot(x,w) + b # nd.dot 함수는 행렬 곱셈을 수행
# y=x⋅w+b를 계산손실 함수 정의하기
선형 회귀 손실을 정의하는데 사용한 제곱 손실 함수 (sqaured loss function)을 사용하겠다. 이를 구현하기 위해서 실제값 y의 shape를 예측값 y_hat의 shape과 동일하게 변형한다. 다음 함수의 리턴 값은y_hat의 모양과 동일하게 바꾼다 -> 여기서 y_hat은 모델이 예측한 값
def squared_loss(y_hat, y): # 예측값과 실제값 사이의 손실 계산
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
# 예측값과 실제값 사이의 차이의 제곱을 계산하여 손실을 구한다
#y의 형태를 y_hat의 형태와 일치시키기 위해 재구성. 오차 제곱을 반으로 나누어 평균 제곱 오차의 기본형식 따름최적화 알고리즘 정의하기
선형 회귀 문제는 잘 정의된 솔루션이 있지만 우리가 다루게 될 많은 재밌는 모델은 분석적인 방법으로 풀릴 수 없다. 그렇기 때문에, 이 문제를 확률적 경사 하강법 (stochastic gradient descent) sgd를 이용해서 풀어보자
- 각 단계에서 데이터셋 중 임의로 선택한 배치를 이용해서, 가중치들에 대한 손실의 gradient를 추정한다
- 손실을 줄이는 방향으로 파라미터들을 조금씩 업데이트한다.
- 여기서 자동 미분 모듈 (autograd)로 계산된 gradient는 샘플들의 배치의 gradient합이다.
- 평균을 구하기 위해서 값을 배치 크기로 나누고 학습속도
lr로 정의된 값에 비례해서 업데이트를 하게 된다
def sgd(params, lr, batch_size): # 파라미터를 업데이트하는 함수
for param in params:
param[:] = param - lr * param.grad / batch_sizeparams: 업데이트할 모델 파라미터들의 리스트. (w와 b등이 포함)lr: 학습률. 파라미터 업데이트 크기를 조절하는 값이다. 학습률이 너무 크면 학습이 불안정해지고 너무 작으면 학습이 매우 느려진다batch_size: 배치크기. 기울기의 평균을 내기 위해 사용params.grad: 현재 파라미터의 기울기. 손실함수에 대해 파라미터의 변화율을 나타낸다lr * param.grad: 학습률과 기울기를 곱한다. 파라미터를 얼마나 업데이트 할지를 결정lr * param.grad / batch_size: 배치 크기로 나눠 평균 기울기를 구한다. 이는 미니배치 경사 하강법에서 일반적으로 사용되는 방법
예시
만약 w와b가 있고 기울기 grad가 0.1과 0.2라고 가정하자. lr이 0.03이고 배치 크기가 10일때
params = [w,b]
lr = 0.03
batch_size = 10
# 가정: w.grad = 0.1, b.grad = 0.2
for param in params:
param[:] = param - lr*param.gard/ batch_size-> w = w - 0.03 0.1 / 10
b = b - 0.03 0.2 / 10
학습
학습은 데이터를 반복해서 사용하면서 모델의 파라미터를 최적화시키는 것이다.
- 현재 얻어진 미니 배치의 데이터 샘플들 (피처
x와 레이블y)을 이용해서 역함수인backward함수를 호출해서 미니 배치에 대한 확률적 경사를 계산한다. - 최적화 알고리즘
sgd을 호출해서 모델 파라미터들을 업데이트하게 된다. 앞의 소스 코드에서 배치크기 batch_size을 10으로 설정했으니, 각 미니 배치별로 손실l의 모양은 (10,1)이 된다.
만약 gradient를 계산하는 코드를 직접 작성해야 한다면 g를 계산해주는 자동 미분을 이용한다. loss l 은 스칼라 변수가 아니라서 l.backward()을 수행하면 l의 모든 항목들을 합해서 새로운 변수를 만들고, 이를 이용해서 다양한 모델 파라미터의 gradient를 계산한다.
lr = 0.03 #학습률
num_epochs = 3 #학습 횟수
net = linreg #모델
loss = squared_loss # 0.5 (y-y')^2
for epoch in range(num_epochs): #학습 횟수만큼 반복
for x, y in data_iter(batch_size, features, labels): # 데이터셋을 배치 단위로 반복
with autograd.record():
l = loss(net(x, w, b), y) # 예측값과 실제값 사이의 손실 계산
l.backward() # 손실의 기울기를 계산
sgd([w, b], lr, batch_size) # 파라미터 업데이트
train_l = loss(net(features, w, b), labels) #학습 손실 계산
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().asnumpy()))
학습된 모델을 평가하는 방법으로 실제 파라미터와 학습을 통해서 찾아낸 파라미터를 비교해보면, 이것들이 매우 비슷해졌다
print('Error in estimating w', true_w - w.reshape(true_w.shape))
print('Error in estimating b', true_b - b)
노이즈가 있는 샘플들을 이용해도 숨겨진 상관관계를 정확하게 찾아낼 수 있을 정도로 많은양의 데이터가 주어진 강한 블록 최적화(strongly convex optimzation) 문제가 그런 경우다. 대부분의 경우는 이렇지는 않고 실제로는 학습데이터가 사용되는 순서를 포함해서 모든 경우가 동일하지 않는 경우가 아니면 딥 네트워크의 파라미터들이 비슷하거나 같게 나오지 않는다. 그럼에도 불구하고 인공신경망은 좋은 모델을 만들어내는데 이는 예측을 잘하는 여러 파라미터 집합들이 존재하기 때문이다.
요약
이번절에서 NDArray와 autograd만 사용해서 계층 정의나 optimizer를 위한 별도의 도구 없이 딥 네트워크 구현 및 최적화를 어떻게 할 수 있는지 살펴봤다. 다음에는 지금까지 배운것들을 기반으로 다양한 딥러닝 모델을 살펴보자
