Ensemble
-
여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
-
일반화 성능을 높이는 것이 핵심
-
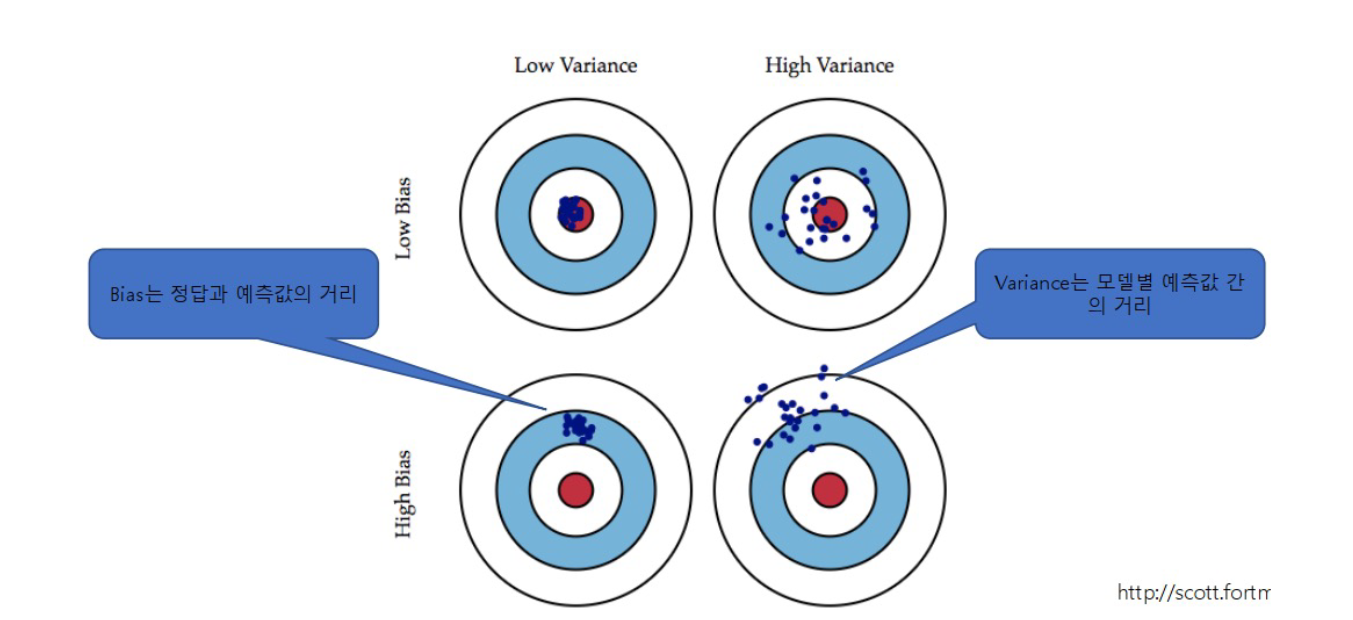
모델의 오류는 주로 Bias와 Variance로 이루어지므로 이를 최소화할 수 있는 방안을 찾음
- Bias: 정답과 예측값 사이의 거리 (예측 자체가 틀리는 정도)
- Variance: 예측값 사이의 거리 (모델이 예측을 일관되게 못함)
Low Bias, High Variance
- 각 모델별로 bias가 존재하는 다양한 bias를 종합하여 과적합 줄임
→ 서로 다른 실수를 하는 모델을 합치면 오히려 안정됨 - 각 모델별로 예측한 variance를 측정하여 예측력 높임
→ 들쭉날쭉한 결과들을 평균내면 더 정확해짐
기본 모형
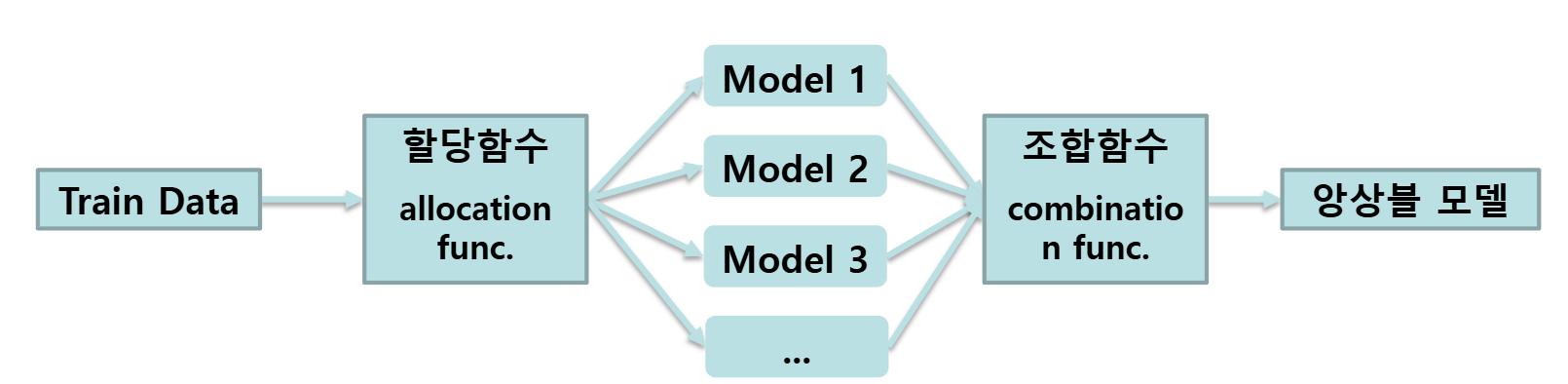
- 할당함수: 입력데이터를 인위적으로 다양하게 해서 다양성 증가
- 조합함수: M1, M2, M3 예측값이 다 다르므로 어떻게 결과를 조합할지 결정
Voting
- 서로 다른 알고리즘을 가진 여러 개의 모델을 학습하고, 이들의 예측 결과를 다수결 투표나 평균화하여 최종 예측을 수행하는 방법
- 예를 들어, 서로 다른 결정 트리, 서포트 벡터 머신, 로지스틱 회귀 등의 모델을 보팅으로 조합할 수 있다
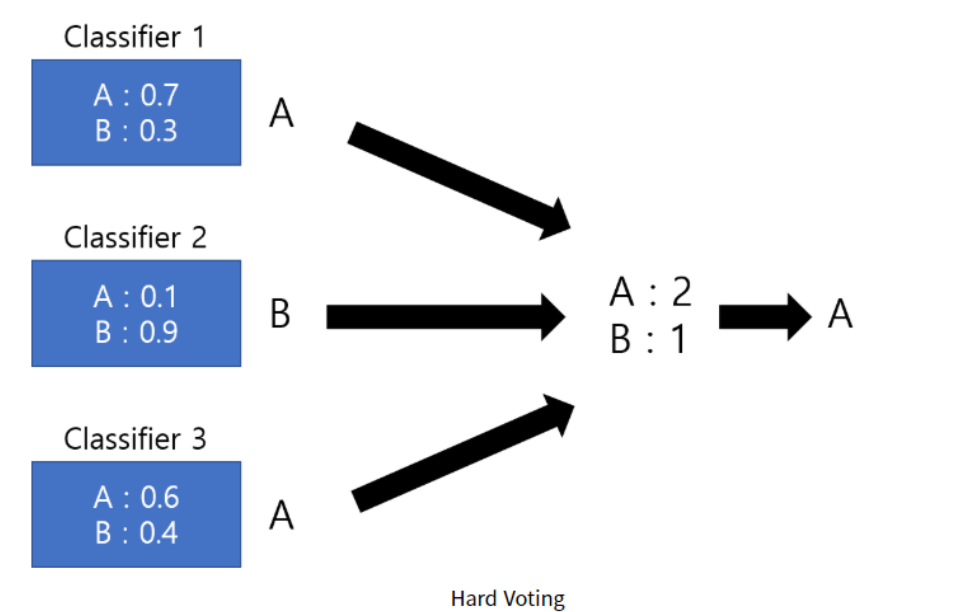
Hard Voting
- 가장 많은 표를 얻은 것을 채택
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
lr = LogisticRegression(solver='liblinear')
knn = KNeighborsClassifier(n_neighbors=8)
voting_clf = VotingClassifier(estimators=[('LR', lr), ['knn',knn], vointg= 'hard'])
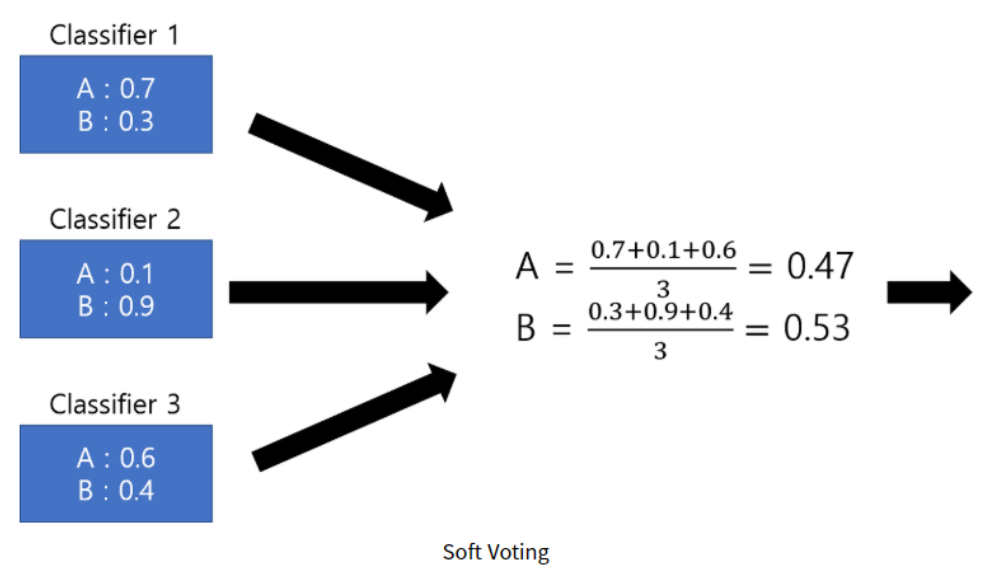
voting_clf.fit(X_train, y_train)Soft Voting
- 각 클래스별로 모델이 예측한 확률을 합산해서 가장 높은 클래스 선택
voting_clf = VotingClassifier(estimators=[('LR',lr),['knn',knn], voting= 'soft'])
voting_clf.fit(X_train, y_train)Bagging
-
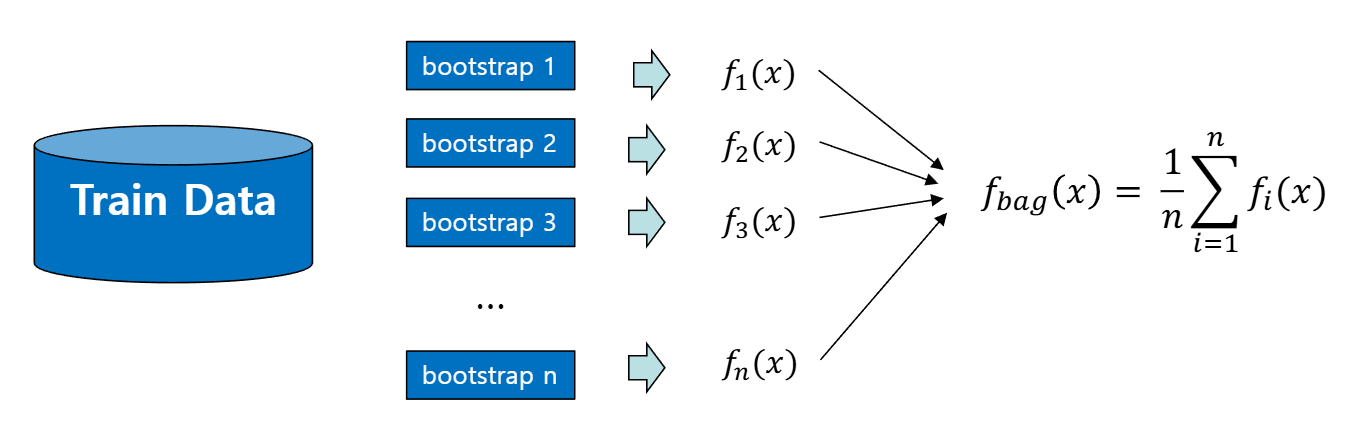
bootstrap aggregating의 약자
-
bootstrap은 우선 복원 추출로 여러 개의 비슷한 데이터를 만든다
- 예: 100개의 샘플이 있는 데이터가 있을 때, 100번 복원 추출해서 10개의 데이터셋을 만든다
- 그래서 10개의 비슷하지만 조금씩 다른 데이터셋이 만들어짐
-
복원 추출이므로 하나의 데이터셋에는 같은 샘플이 여러 개 들어있을 수 있음
-
통합은 평균(예측의 경우) 또는 투표(분류의 경우)를 이용
-
배깅은 통합하는 모델 각각에 동등한 가중치를 적용
-
각 표본이 유사하여 예측력이 떨어질 수 있다
# Decision Tree
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier()
tree.fit(X_train,y_train)
# Bagging
from sklearn.ensemble import BaggingClassifier
bag = BaggingClassifier(DecisionTreeClassifier(), n_estimators=10)
bag.fit(X_train, y_train)RandomForest
-
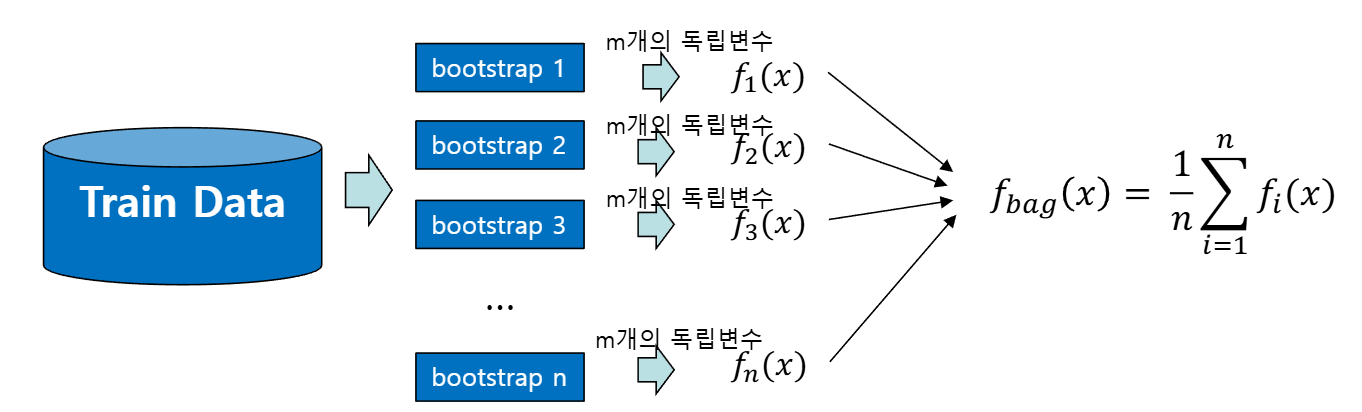
랜덤포레스트는 기본적으로 배깅과 유사한 절차를 거치나, 표본을 더 다양하게 만든다
-
표본마다 독립변수 일부만 랜덤하게 추출하여 서로 다른 모델을 만들기 때문에 일반적으로 예측력이 더 좋아짐
-
장점
- 파라미터 튜닝에 민감하지 않음
- 데이터 스케일 맞출 필요 없음
- 데이터 커도 잘 작동
- 분산처리 손쉬움
-
단점
- 차원 높고 sparse한 데이터에선 힘들어짐
- 메모리 많이 쓰고 상대적 느림
from sklearn.ensemble import RandomForestClassifier
forest = RandomClassifier(n_estimators=10)
forest.fit(X_train,y_train)Boosting
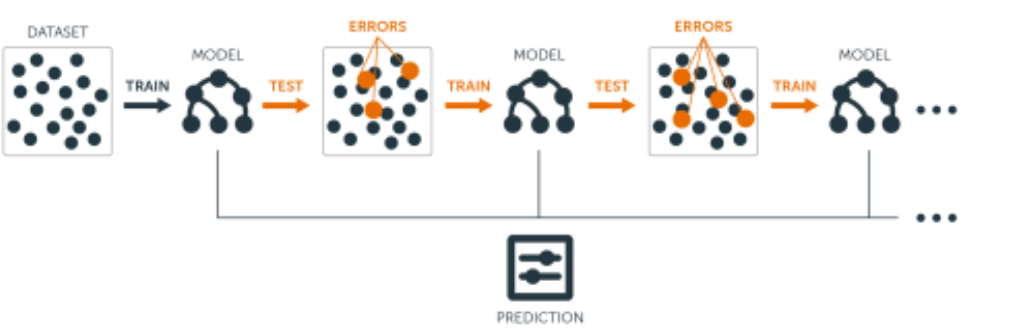
- 여러 개의 약한 모델을 순차적으로 학습시켜서
앞에서 틀린 데이터에 더 집중하면서 예측력을 점점 높여가는 방식 - 과적합 가능성이 높음
- Adaboost, Gradient Boosting이 있음
기본 아이디어
- 모델을 한 번에 여러 개 만들지 않고, 하나씩 차례대로 만듦
AdaBoost
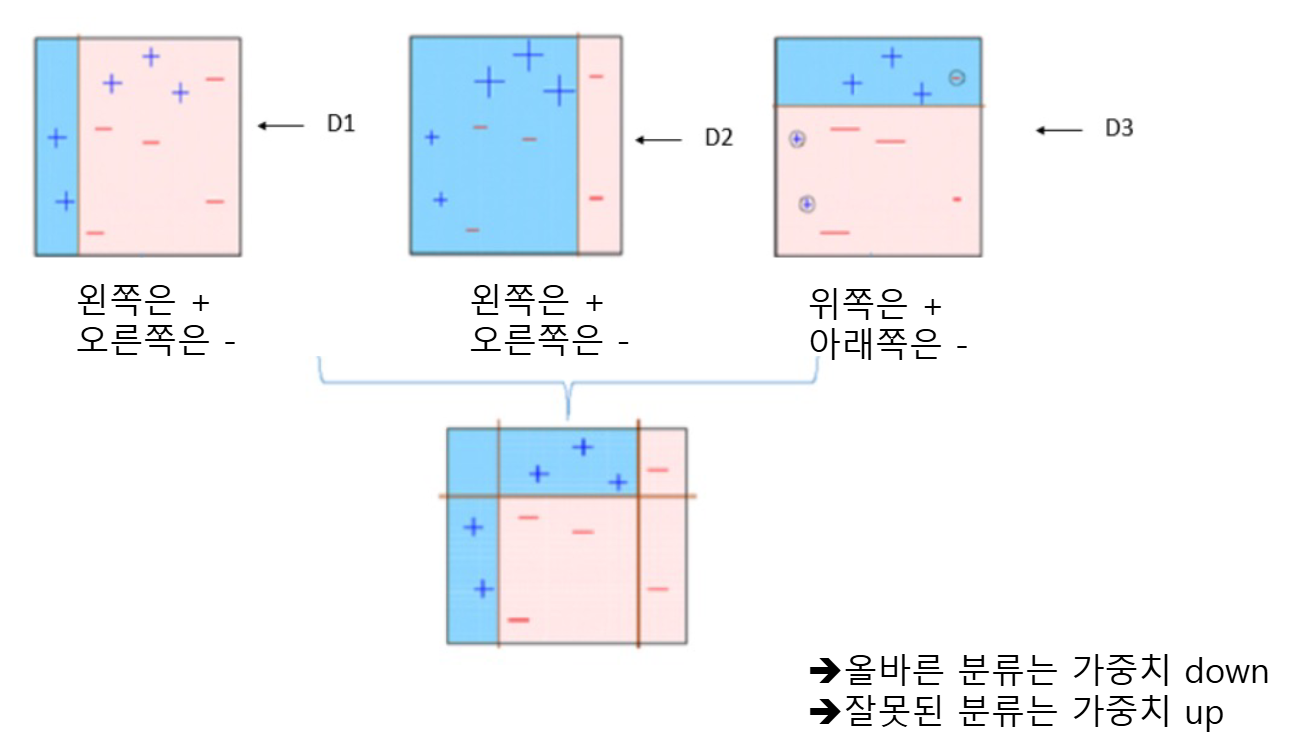
- 이전 모델의 오차를 보완하는 모델을 만들어 결합!
- 가중치를 높이면 잘못 분류한 샘플이 추출될 확률이 높아짐
- model1이 잘못 예측한 데이터에 가중치 부여
- model2는 잘못 예측한 데이터를 분류하는 데 집중
- model3는 model1,2가 잘못 예측한 데이터를 분류하는 데 더 집중
- 분류와 회귀 모두 가능하며, 회귀는
AdaBoostRegressor사용
from sklearn.ensemble import AdaBoostClassifier
ab = AdaBoostClassifier(n_estimators=10)
ab.fit(X_train, y_train)Gradient Boosting
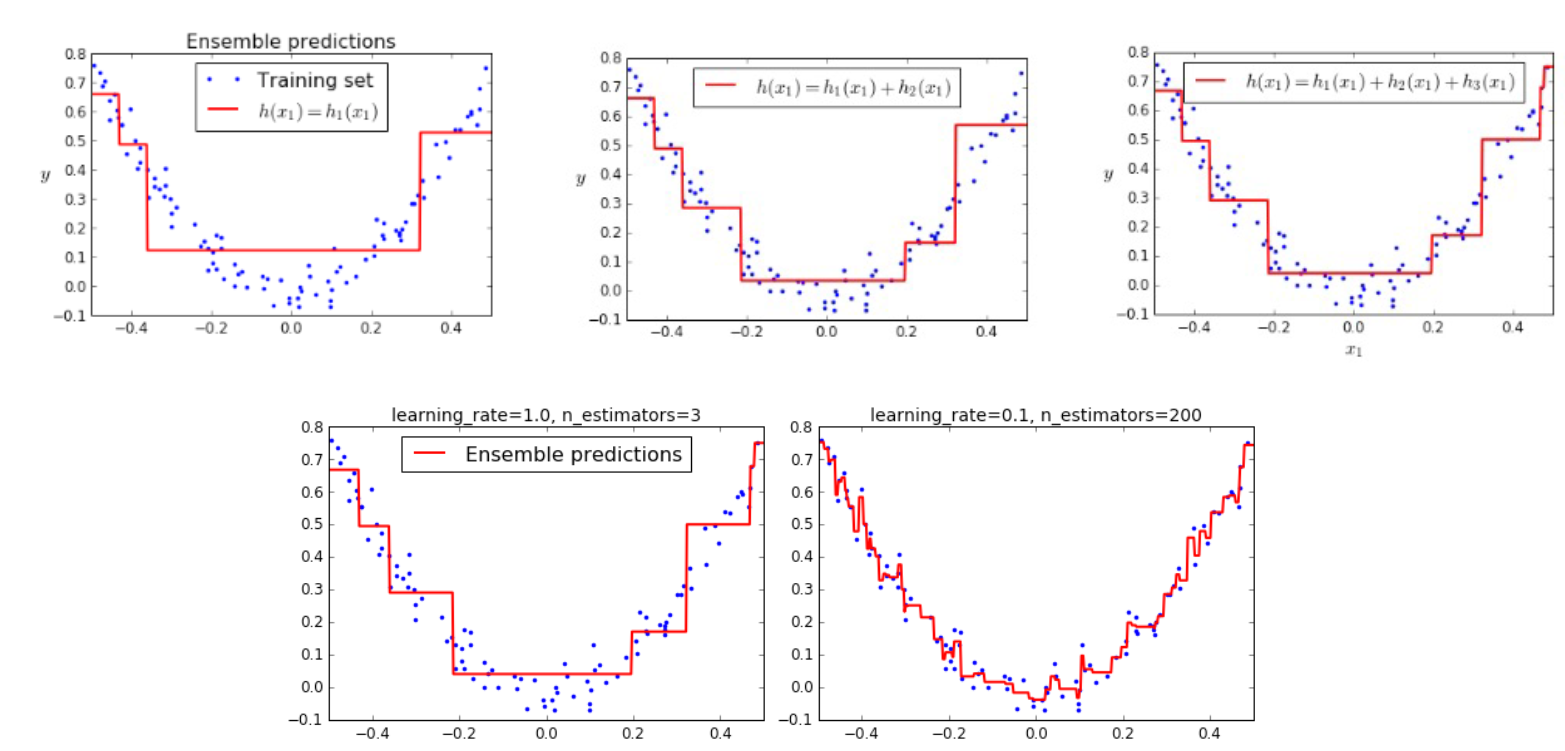
- 깊이가 얕은 트리(예: 깊이 3 정도)를 여러 개 사용
- 트리를 많이 추가할수록 성능이 올라감
- Adaboost처럼 샘플 가중치를 수정하지 않고,
이전 모델이 틀린 정도(residual error) 를 기준으로 다음 모델 학습 - 경사하강법을 사용해서 오차를 줄임
- 분류와 회귀 모두 가능하며, 회귀는
GradientBoostingRegressor사용
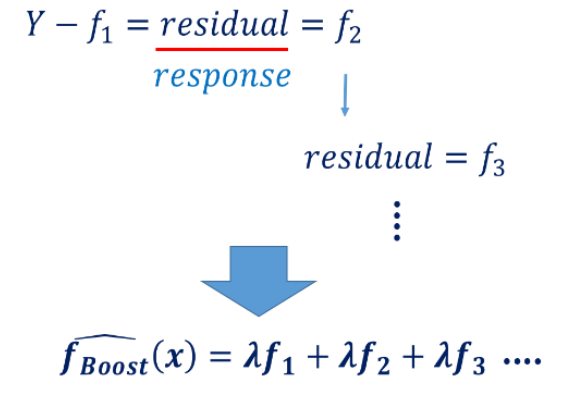
- 이전 모델의 residual error에 fitting하는 모델
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(n_estimators=10)
gb.fit(X_train,y_train)XGBoost
- 트리 기반의 앙상블 학습에서 가장 각광받는 알고리즘
- 분류 문제에 매우 강력함
- GBM + 병렬 처리 → GBM보다 훨씬 빠름
from xgboost import XGBClassifier
xgb = XGBClassifier(n_estimators=10)
xgb.fit(X_train, y_train)LightGBM
- XGBoost처럼 빠른 병렬/분산 처리 지원
- 손실값이 큰 리프노드를 계속 분할하는 방식이라서
균형 트리 방식보다 예측 오류를 더 잘 줄임
from lightbgm import LGBMClassifier
lightgbm = LGBMClassifier(n_estimators=10)
lightgbm.fit(X_train, y_train)요약
- Bagging: 모델을 다양하게 만들기 위해 데이터를 재구성
- RandomForest: 데이터뿐만 아니라 변수도 재구성
- Boosting: 틀린 데이터에 집중해서 점점 잘 맞춰가는 방식

인공지능.관심 있습니다.