
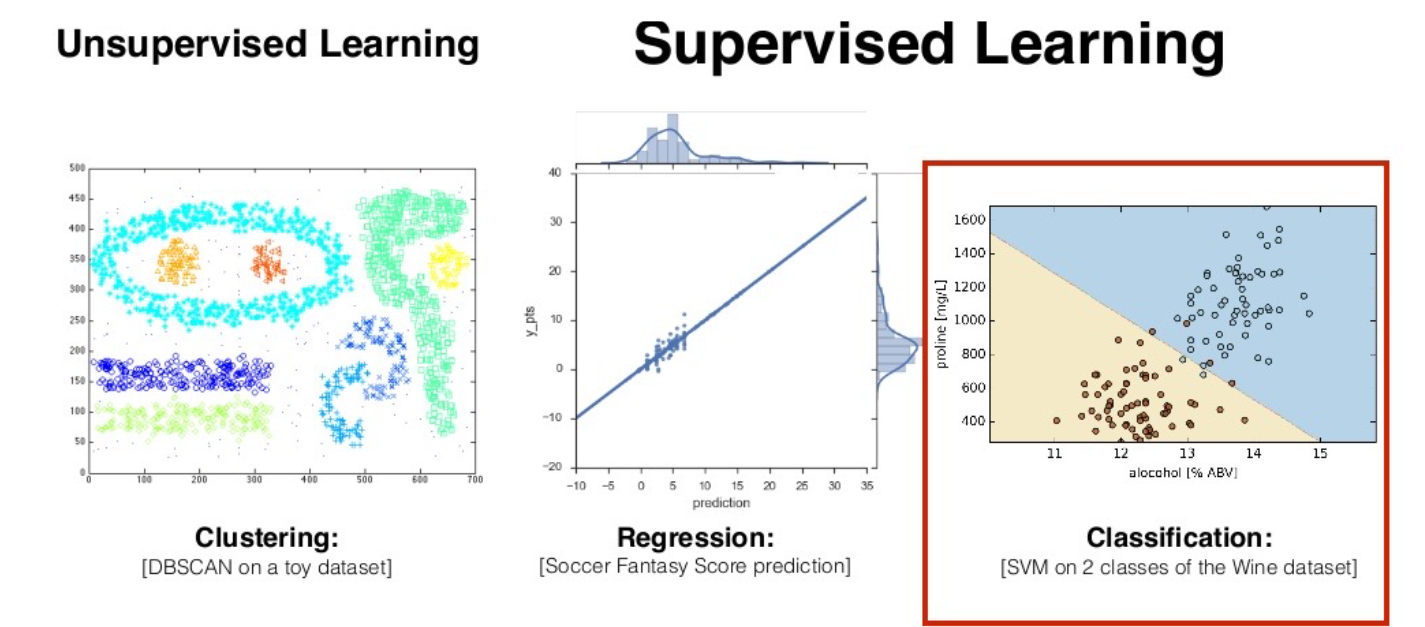
군집분석
- 데이터를 비슷한 애들끼리 묶는 작업
- 비슷한 건 같은 그룹, 다른 건 다른 그룹으로 나눔
- 정답(label)이 없는 데이터에 사용하는 비지도 학습
- 데이터가 어떤 식으로 분포돼 있는지 파악할 때 유용함
활용 예시
- 추천 시스템: 비슷한 제품끼리 묶어서 추천
- 검색 엔진: 관련된 검색 결과끼리 묶기
- 시장 분석: 비슷한 고객들끼리 그룹 나누기
K-means clustering
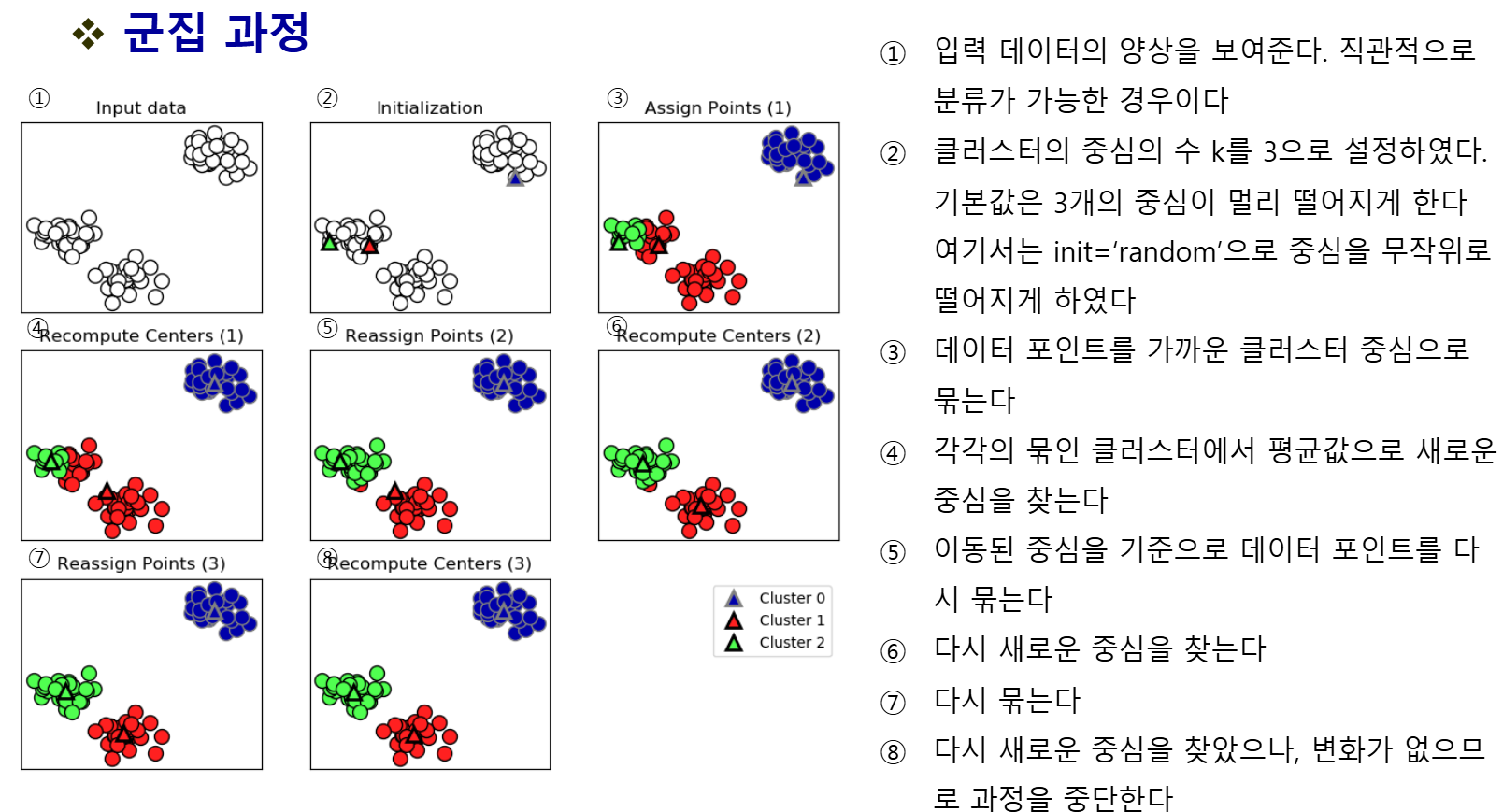
- 제일 대표적인 군집 방법
- 클러스터 수(K)를 먼저 정해야 함
- 각 그룹의 중심점을 기준으로 묶음
- 계산이 빠르고 간단하지만, 이상치에 민감함
- 데이터 범위가 다르면 → 스케일링 필요
핵심 개념
- "K": 나누고 싶은 그룹 개수
- "means": 그룹 중심점과의 거리 평균 → 이걸 최소화하는 게 목표
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
kmeans.labels_→ 클러스터를 3개로 나눠서 라벨 0,1,2로 분류됨
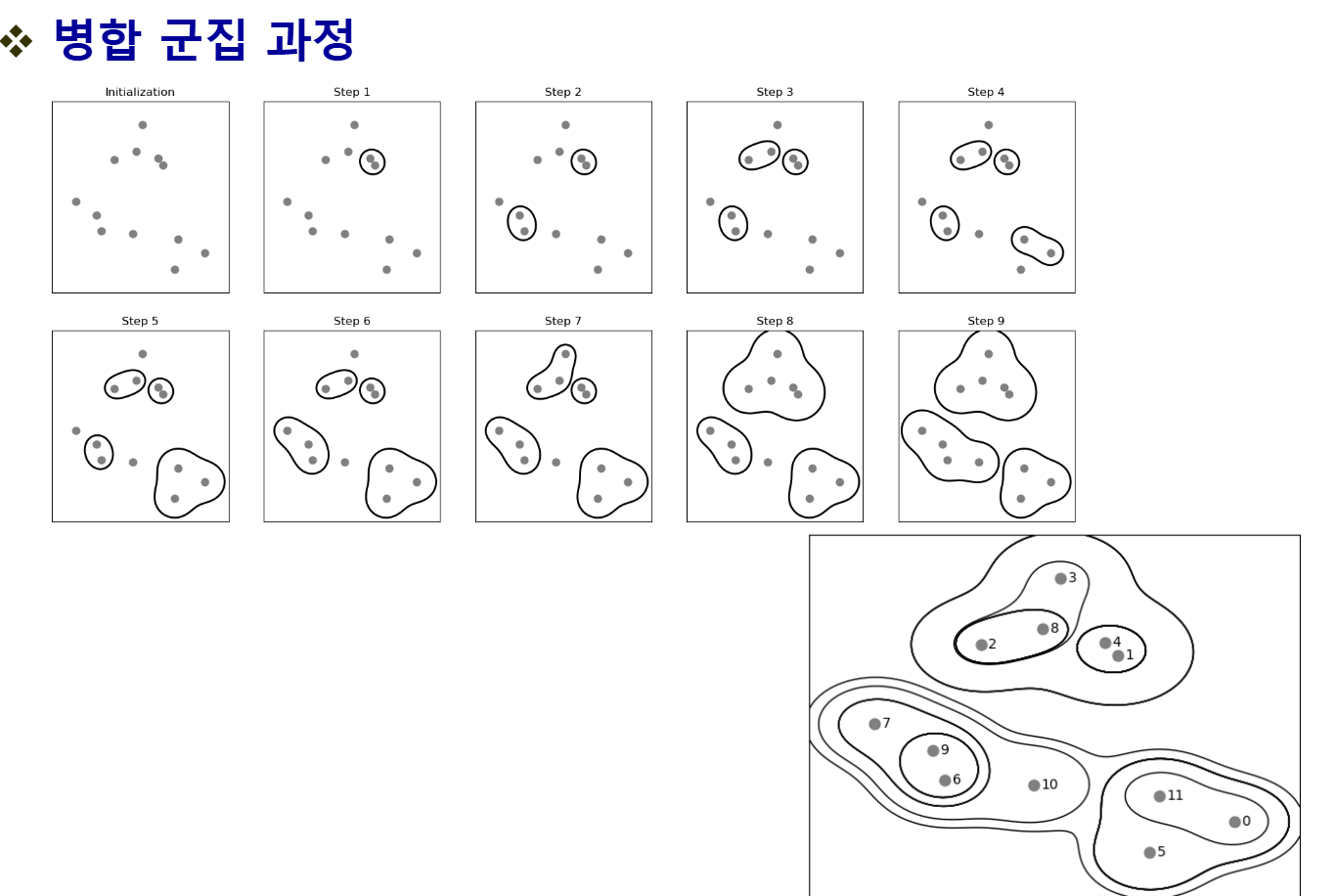
Agglomerative Clustering (병합 군집)
- 처음엔 각 데이터가 하나의 클러스터
- 비슷한 것끼리 점점 병합해서 클러스터 만들어감
- 몇 개로 나눌 건지 n_clusters로 지정
유사도 계산 방식
- ward: 합쳤을 때 분산이 덜 늘어나는 쌍
- average: 평균 거리가 가장 가까운 쌍
- complete: 가장 멀리 떨어진 점 간 거리가 가장 짧은 쌍
from sklearn.cluster import AgglomerativeClustering
agg = AgglomerativeClustering(n_clusters=2)
agg.fit(X)
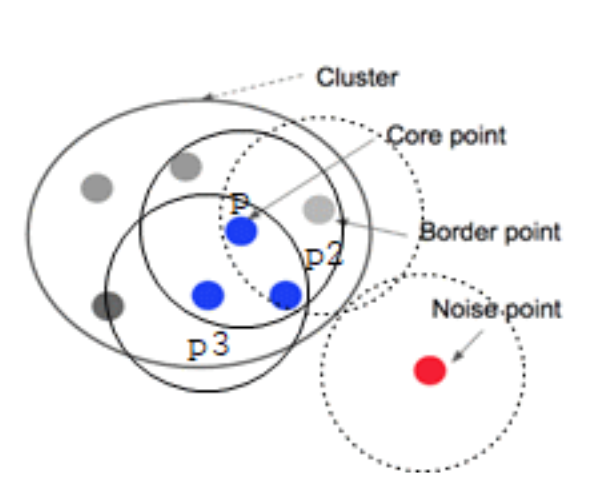
agg.labels_DBSCAN
- 밀도 기반 클러스터링
- 밀집된 부분은 클러스터로 묶고, 떨어진 건 노이즈 처리
용어 정리
- core point: 주변에 점이 많은 중심점
- border point: 군집 안에 있지만 주변에 점이 적음
- noise: 어디에도 속하지 않음
장점
- 클러스터 수 미리 정할 필요 없음
- 이상치에 강하고, 복잡한 모양도 잘 잡음
from sklearn.cluster import DBSCAN
dbs = DBSCAN(eps=0.5)
dbs.fit(X)
dbs.labels_→ eps 값을 늘리면 더 넓게 묶임
dbs = DBSCAN(eps=1)
dbs.fit(X)
dbs.labels_군집 성능 평가
1. ARI (Adjusted Rand Index)
- 정답이 있는 경우 사용
- 레이블이 같으면 1, 섞여 있으면 0에 가까움
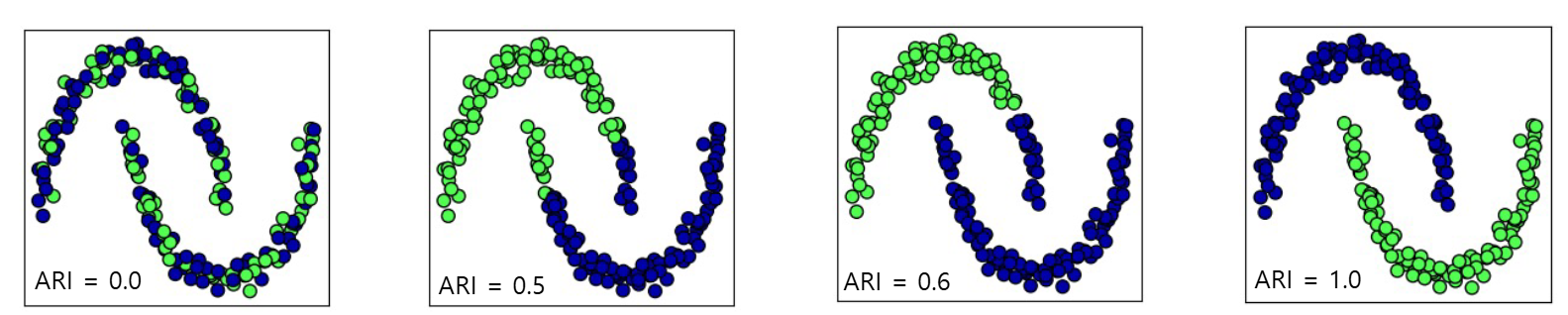
from sklearn.metrics.cluster import adjusted_rand_score
adjusted_rand_score(y, kmeans.labels_)
adjusted_rand_score(y, agg.labels_)
adjusted_rand_score(y, dbscan.labels_)2. 실루엣 계수
- 정답이 없을 때 사용
- 같은 그룹 안에서는 가까워야 하고, 다른 그룹과는 멀어야 함
- 값이 클수록 군집이 잘 된 것
from sklearn.metrics.cluster import silhouette_score
silhouette_score(X, kmeans.labels_)
silhouette_score(X, agg.labels_)
silhouette_score(X, dbs.labels_)
인공지능.관심 있습니다.