Goorm AI
1.지도학습 기법 1_1
알고리즘의 종류 지도학습과 비지도학습 지도학습 알고리즘은 과거의 데이터를 학습하여 새로운 데이터를 예측하는 알고리즘 비지도학습 학습할 데이터가 없이, 현재의 데이터만을 보고 분류하는 알고리즘 분류와 군집화 분류(Classification) 정답이 있는 데이터를 지도학
2.지도학습 기법 1_2
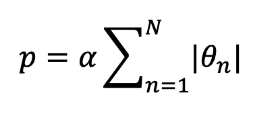
Linear 선형 모델은 전체 데이터셋에서의 중심선을 찾는다 직선의 형태를 갖기 때문에 선형 모델 중심선은 잔차(오차)의 제곱의 합이 최소가 되게 하는 선 잔차 = 참값 - 예측값 MSE(mean squared error) 평균제곱오차 경사하강법 어떤 계수가 최소
3.평가

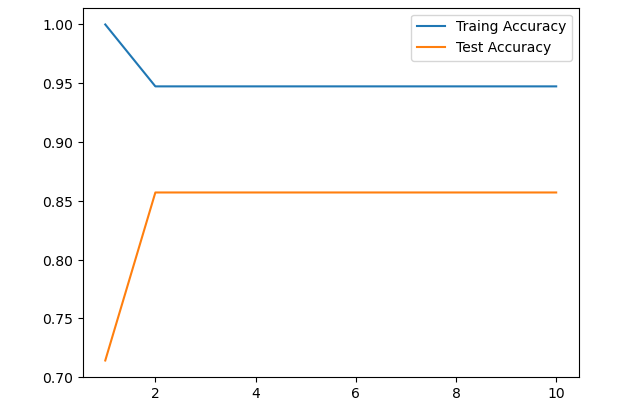
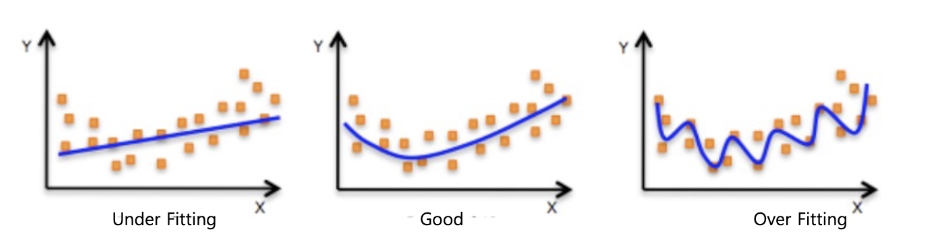
예측 모델 성능 평가 데이터 셋 구성 Training set (훈련 데이터) → 모델을 학습시키는 데 사용 Validation set (검증 데이터) → 모델 훈련 중 성능을 확인하고, 과적합(overfitting) / 과소적합(underfitting) 을 방지 → 언제 학습을 멈춰야 할지 판단하는 데 도움 Test set (테스트 데이터...
4.지도학습 기법 2_1
Decision Tree 가능한 적은 질문으로 문제를 해결하는 것을 목표 기본적인 결정에 도달하기 위하여 Yes/No 질문을 이어나가며 학습 규칙의 기준은 순수도(purity)를 가장 높여줄 수 있는 쪽을 먼저 선택해 진행 순수도 측정에는 지니 척도 또는 정보 이익이
5.지도학습 기법 2_2
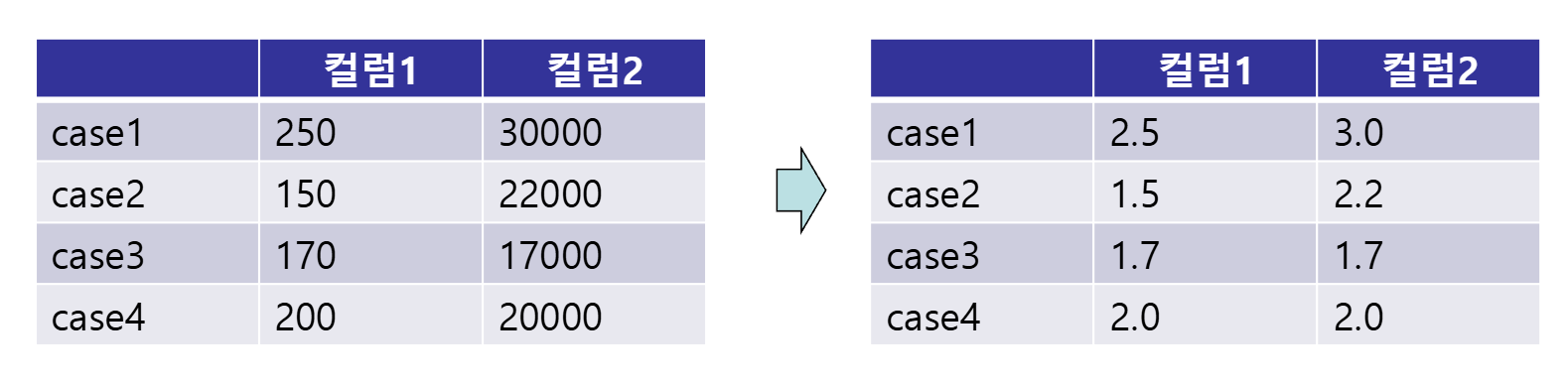
Feature Scaling 범주형 데이터 처리
6.앙상블 기법
Ensemble 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법 일반화 성능을 높이는 것이 핵심 모델의 오류는 주로 Bias와 Variance로 이루어지므로 이를 최소화할 수 있는 방안을 찾음 Bias: 정답과 예측값 사이의 거리 Varia
7.비지도학습 기법

군집분석 데이터셋을 클러스터라는 그룹으로 나누는 작업 서로 유사한 데이터는 같은 클러스터로, 서로 유사하지 않은 데이터는 다른 클러스터로 분리 군집분석은 현재 데이터의 분포 상태를 보고 묶음 지도학습과는 달리 정답이 없는 상태에서 쓰이며, 레이블링도 무작위 활용 예:
8.딥러닝 개요
딥러닝 Deep Learning 적용 가능 분야 추천 시스템, 번역 시스템, 컴퓨터 비전 등 책임 소재 및 의사결정의 이유가 필요하지 않은 분야 높은 성능이 요구되는 분야 데이터가 충분히 확보되어 있어야함 > 딥러닝이 주목받은 이유? -
9.신경망
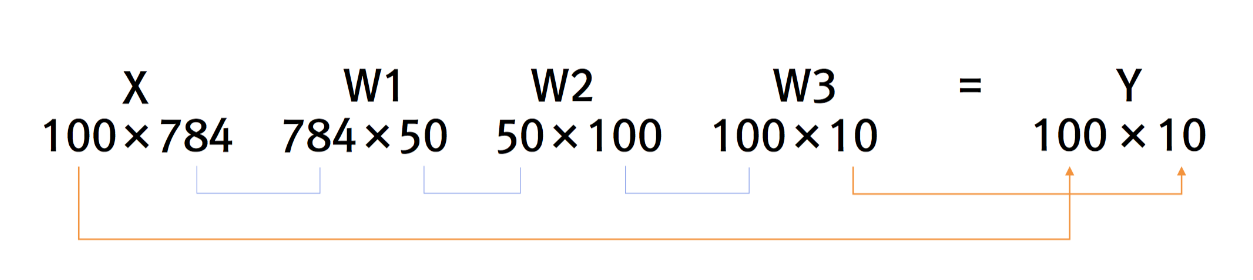
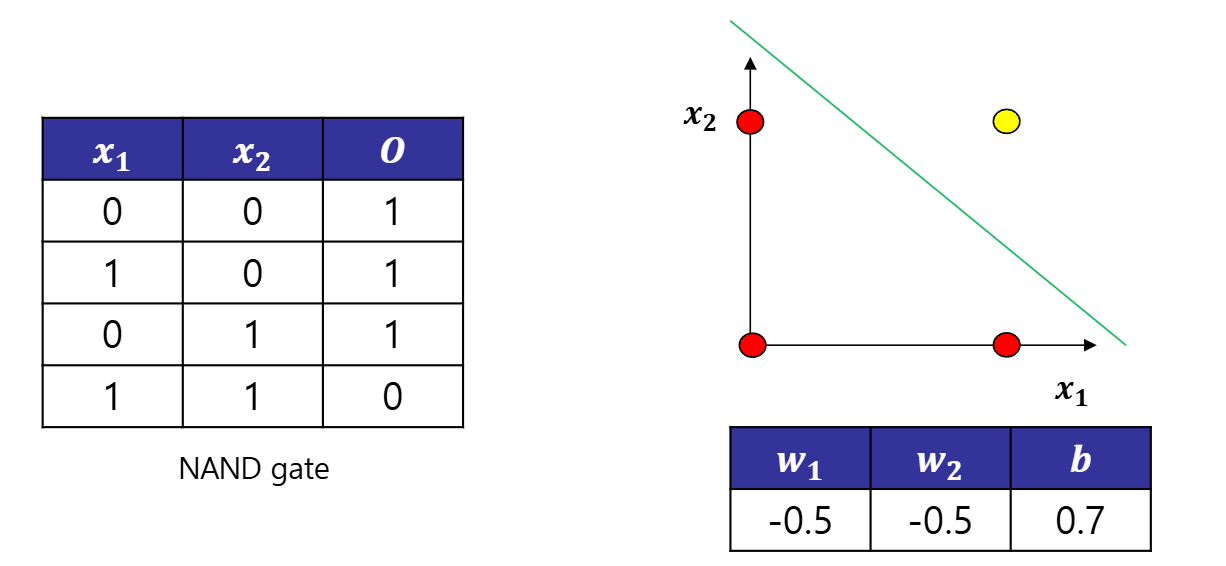
Neural Network Perceptron의 장단점 장점: 복잡한 함수의 표현이 가능하며, 이론적으로 컴퓨터가 수행하는 처리까지 가능 단점: 가중치를 설정하는 작업이 수동임 퍼셉트론에서 신경망으로 가중치가 b이고 그 input이 1인 뉴런 추가 x1,x2
10.신경망의 학습
데이터 주도 학습은 신경망이 데이터를 보고 스스로 최적의 가중치와 편향을 찾아가는 과정사람이 직접 설정 안 하고, 데이터로 자동 학습가중치 매개변수: 신경망이 입력을 출력으로 바꿀 때 쓰는 값들. 이걸 조정해서 예측을 더 정확하게 만듦.데이터로 학습: 데이터를 보고 가
11.Back Propagation
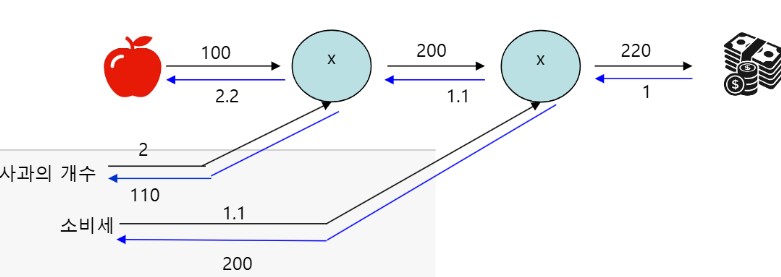
Computational graph 계산 그래프는 계산 과정을 그래프로 나타낸것 노드와 엣지로 표현 그래프의 계산 방향이 왼쪽에서 오른쪽 : 순전파 (forward propagation) 그래프의 계산 방향이 오른쪽에서 왼쪽 : 역전파 (backward propaga
12.파이토치
파이토치 개요 파이토치는 2017년 초에 공개된 딥러닝 프레임워크 루아 언어로 토치를 페이스북에서 파이썬 버전으로 내놓은 것 대상 넘파이를 대체하면서 GPU를 이용한 연산이 필요한 경우 최대한 유연성과 속도를 딥러닝 연구 플랫폼이 필요한 경우 텐서는 행렬의 다차원