알고리즘의 종류
지도학습과 비지도학습
지도학습
- 알고리즘은 과거의 데이터를 학습하여 새로운 데이터를 예측하는 알고리즘
비지도학습
- 학습할 데이터가 없이, 현재의 데이터만을 보고 분류하는 알고리즘
분류와 군집화
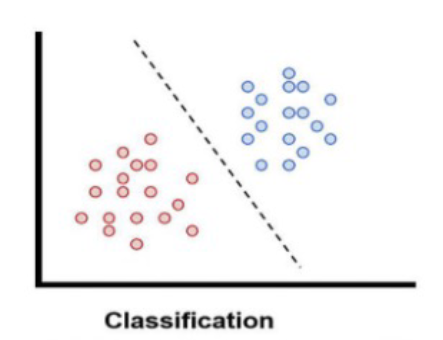
분류(Classification)
- 정답이 있는 데이터를 지도학습을 통해 분류
- decision boundary로 구분
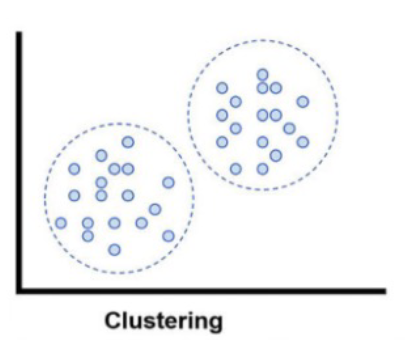
군집화(Clustering)
- 정답이 없는 데이터를 클러스터링
지도학습의 종류
-
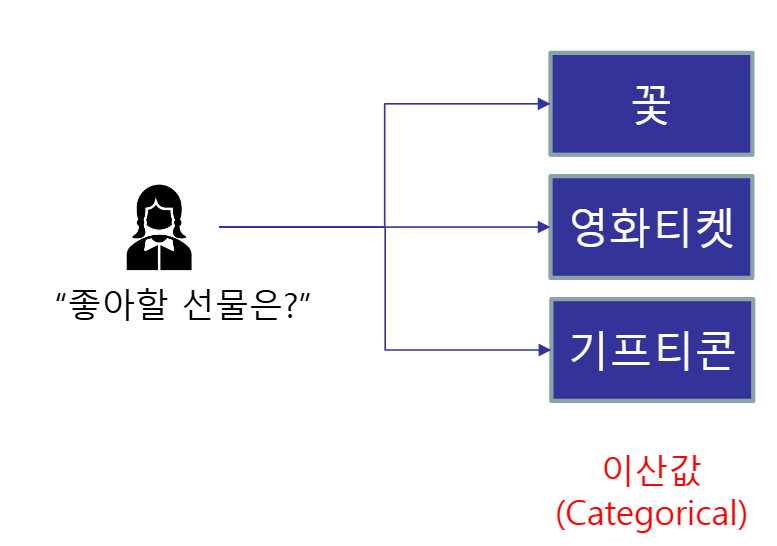
분류 : 가능성 있는 몇몇 후보 중 하나를 선정
- 이진 분류(binary classification) : 클래스가 두개
- A 또는 B중 어디에 속할지
- 예: 스팸 메일 구분 y/n
- 다중 분류(multiclass classification) : 클래스가 셋 이상
- A,B,C 중 어디에 속할지
- 예: Iris 하위종 구분 (Setosa/ Versicolor/Virginica)
- 이진 분류(binary classification) : 클래스가 두개
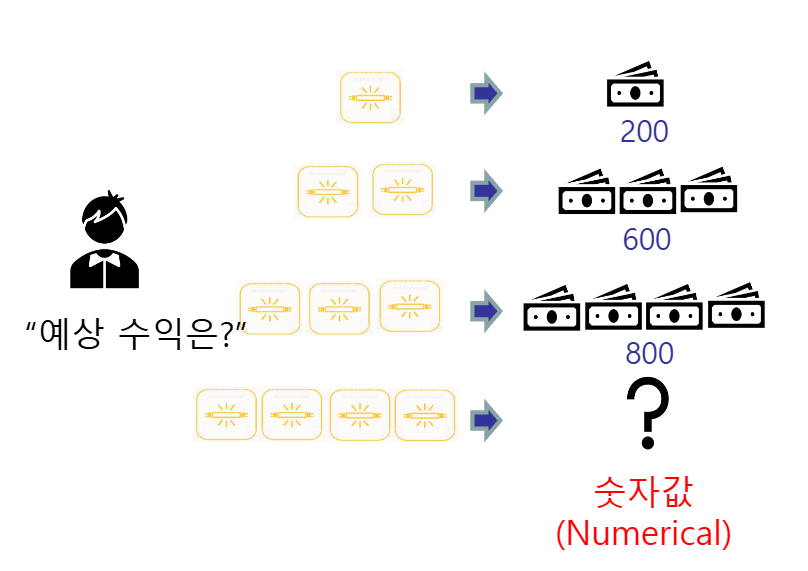
- 회귀 : 연속적인 숫자 값을 예측
- 키가 큰 부모의 자녀들도 세대가 지날수록 평균에 회귀한다는 사실을 발견- 부모의 키 : 독립변수 = 설명변수
- 자녀의 키 : 종속변수 = 반응변수
- 예: 온도, 강우량, 고용인원으로 수확량 예측하기, 형광등 수에 따른 매출액 예측하기
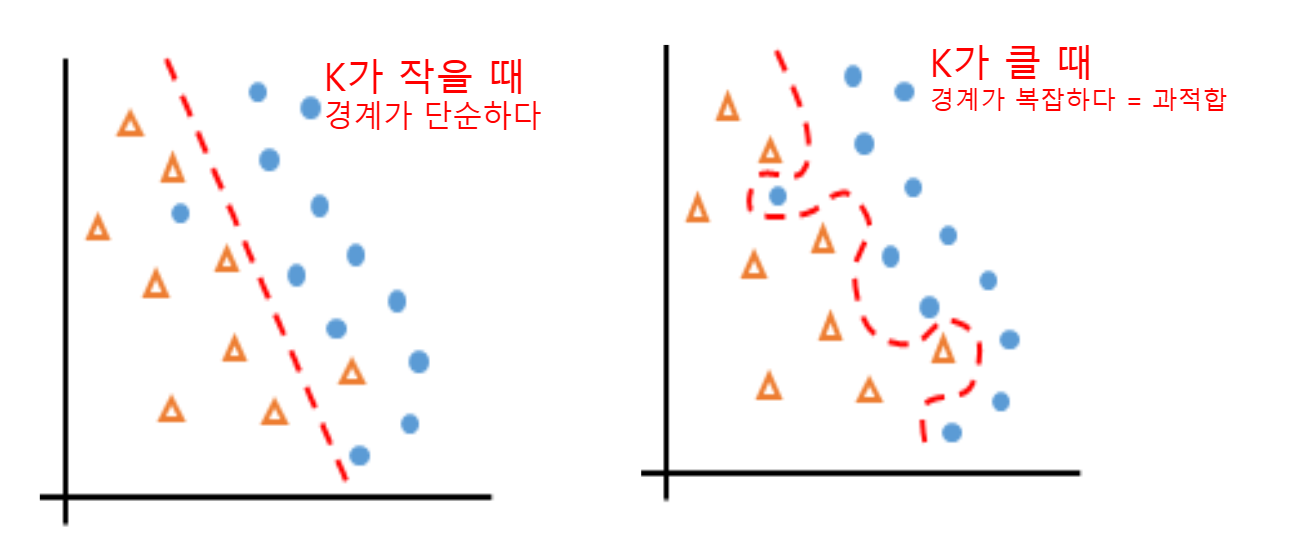
Overfitting 문제
- 규칙이 매우 복잡하게 구성되어 있어 훈련 데이터는 잘 맞추지만, 새로운 데이터는 잘 맞추지 못하는 모델을 과대적합 되었다고 한다
- 반면 규칙이 너무 단순하게 만들어진 모델은 과소적합 되었다고 한다.
일반화(Generalization)
- 중요한 것은 모델이 새로운 데이터를 잘 맞추게 하는것이다. 이러한 모델은 일반화 되었다고 한다
- 데이터셋이 다양성을 갖춰야 한다!
- 다양한 경우를 포함한 데이터 샘플을 많이 확보 하는 것이 중요하다
훈련데이터와 테스트 데이터
전체 데이터셋을 임의로 섞어 약 70%만으로 모델을 만든다. 모델이 30%의 테스트 데이터를 잘 예측하면 일반화 되었다고 함
- 파이썬에는 전체 데이터셋을 훈련데이터와 테스트데이터로 구분해주는 함수가 있다
X_train, X_test, y_train, y_test = train_test_split(data, target)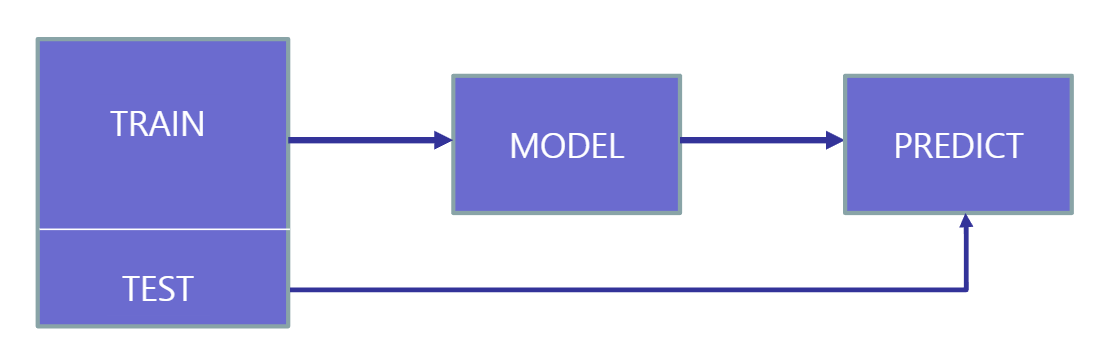
KNN (K- Nearest Neighbors)
- knn 알고리즘은 예측할 데이터와 가장 가까운 데이터를 찾아서 분류
- k=3은 가까운 이웃 셋을 본다는 뜻
- 이웃의 분류가 많은 쪽으로 예측
- 보통 k의 숫자는 홀수를 취함
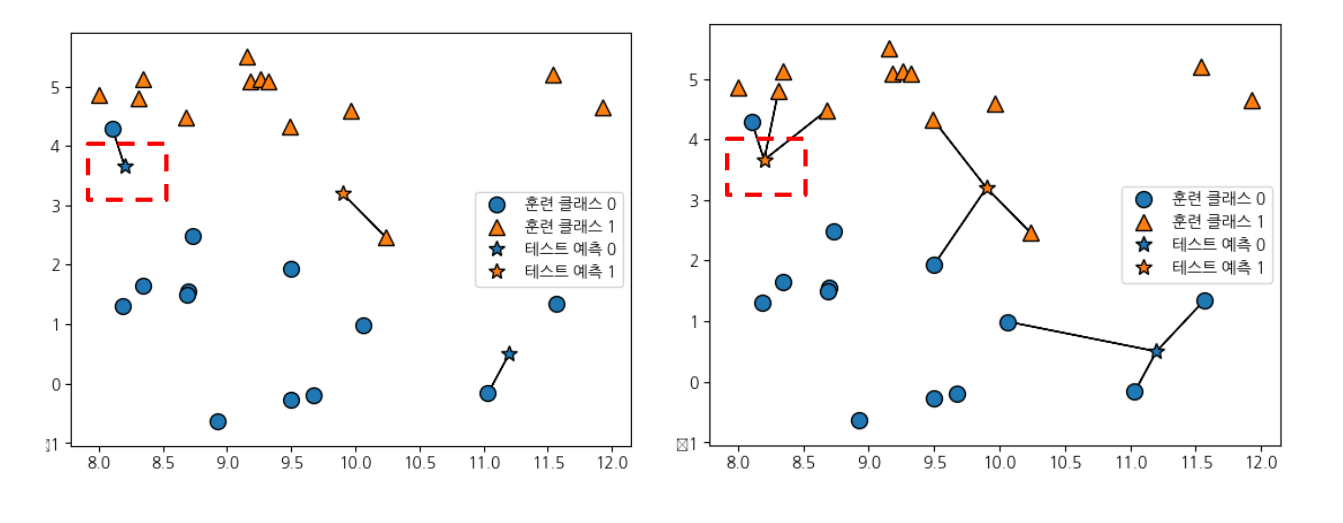
- 너무 작은 k를 선정하면 주변 소수의 데이터에 큰 영향을 받는다
- 너무 큰 k를 선정하면 관련이 없는 먼 곳의 데이터까지 분류에 영향을 끼치고 정작 중요한 주변 데이터 영향력은 작아진다
-> 과적합 우려
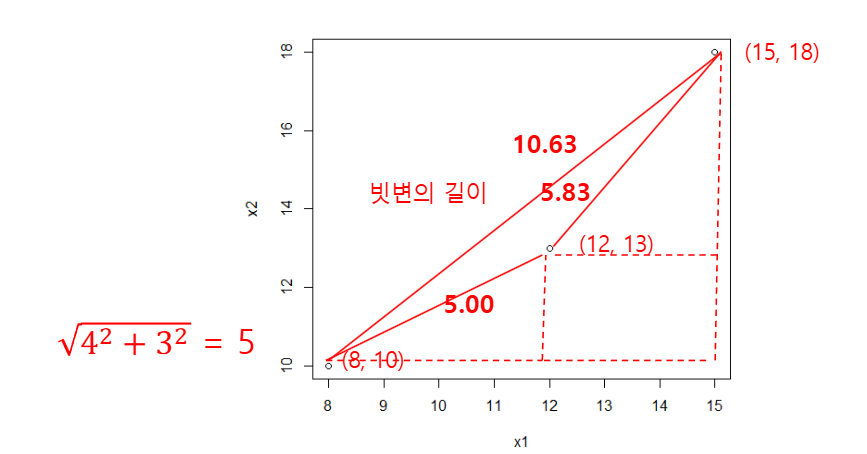
거리 측정
- 이웃인지 알려면 거리를 측정해야함
- 유클리디안 기법과 맨하탄 기법이 있음
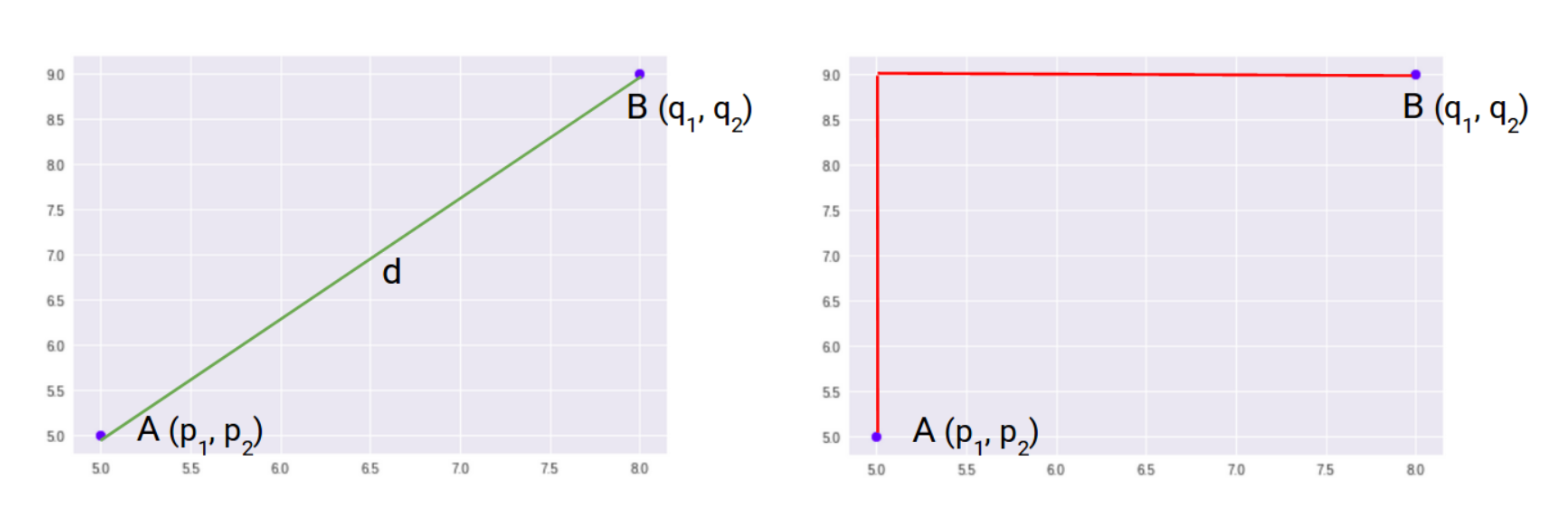
유클리디안 기법
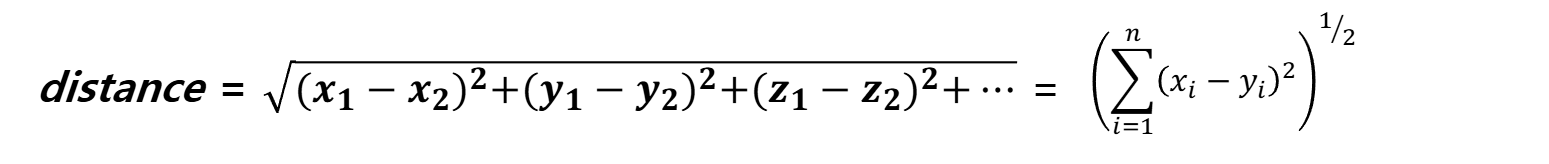
맨하탄 기법
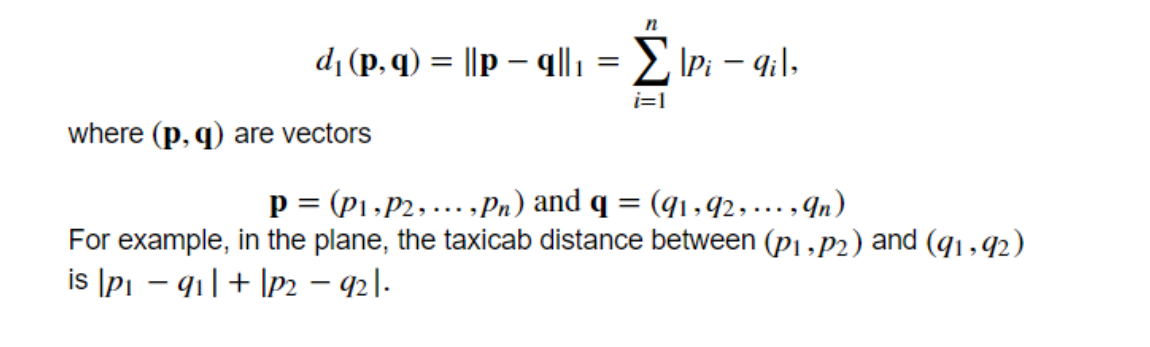
장단점
- 이해하기 쉬운 알고리즘이지만 계산 속도가 느리다
- 독립변수가 수백 개 이상이면 계산이 복잡해져 특히 느려진다
- 각 독립변수의 내용은 비슷한 값의 범위를 갖도록 전처리 해야한다
k를 변경해보기
%matplotlib inline
import matplotlib.pyplot as plt # pyplot 패키지 로딩
train_accuracy = [] # 결과를 받는 빈 리스트
test_accuracy = []
n_neighbors_settings = range(1, 11) # 1~10까지 변경
for n_neighbors in n_neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors) # 객체 생성
clf.fit(X_train, y_train) # 모델 훈련
train_accuracy.append(clf.score(X_train, y_train)) # 훈련 정확도 저장
test_accuracy.append(clf.score(X_test, y_test)) # 테스트 정확도 저장
plt.plot(n_neighbors_settings, train_accuracy, label="Traing Accuracy") # 훈련 정확도
plt.plot(n_neighbors_settings, test_accuracy, label="Test Accuracy") # 테스트 정확도
plt.legend() # 범주
plt.show()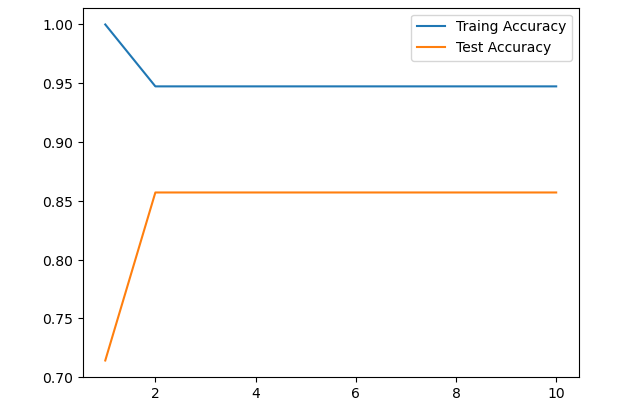
- K=1일때 훈련데이터에서 정확도가 100%가 된 것은 모델이 과대적합 되었기 때문이다
- 따라서 knn에서는 K=3 이상을 적절한 값으로 본다
KNN Regressor
- knn은 연속된 숫자를 예측하는 회귀 상황에서도 쓰일 수 있다,
- k개의 이웃이 가진 값의 평균을 구한다
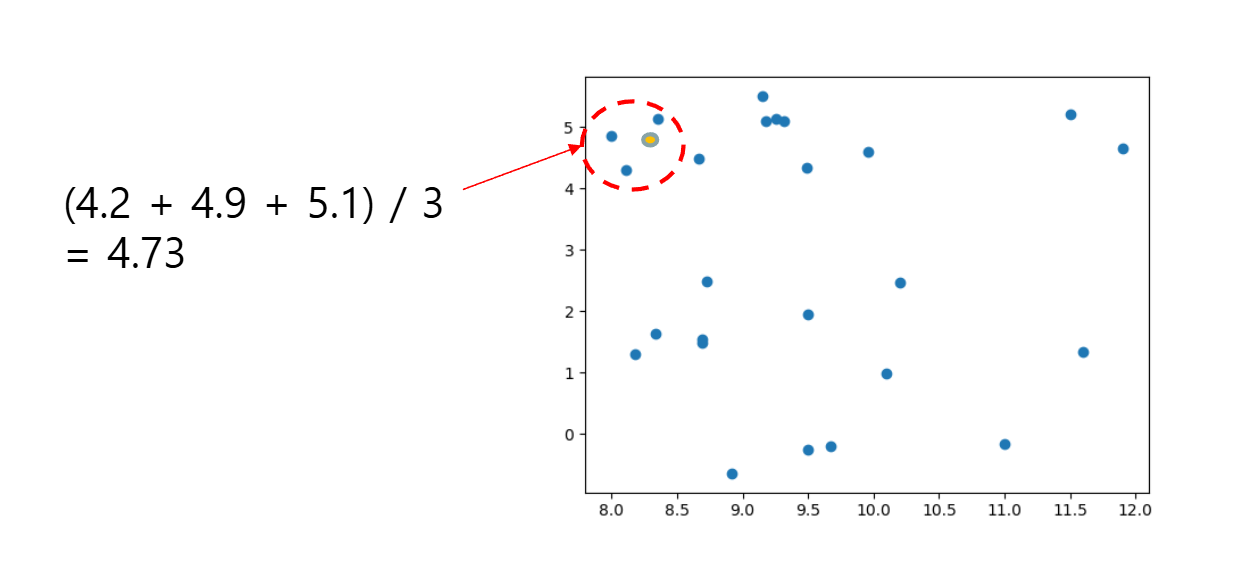
모델훈련
# 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y)
# k=3로 모델 훈련
from sklearn.neighbors import KNeighborsRegressor
reg = KNeighborsRegressor(n_neighbors = 3)
rig.fit(X_train, y_train)R^2 score
-
R sqaure 점수는 회귀 모델이 자료를 얼마나 잘 설명하는 말한다
-
SST는 기본 차이값(분산) 이고, SSE는 예측의 차이값
- 편차를 기본 차이값으로 간주하여 분모에 놓는다
- 그리고 예측값의 차이를 분자로 놓으면 전체 차이값에서 모델이 실제로 갖는 차이값을 표현하게 된다
- 이 값을 1에서 빼면, 모델의 정확도를 표현
-
Residual(잔차)은 실제 관측값과 모델이 예측한 값의 차이를 의미한다
-
Residual = 실제값(y) - 예측값(ŷ)
-
SSE는 이 residual의 제곱합으로, Σ(y - ŷ)² = Σ(residual)²
-
Residual이 작을수록 모델의 예측이 정확하다는 의미이다

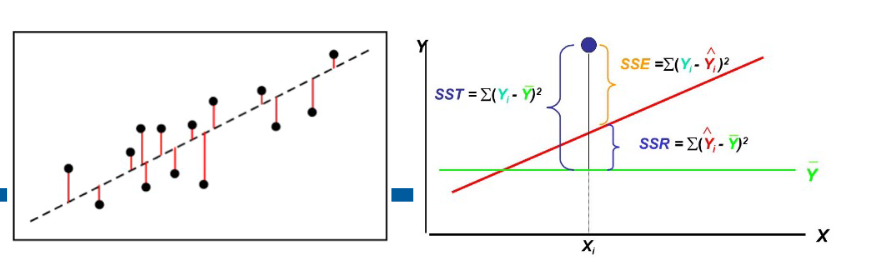
-
이 그림은 회귀 분석에서 중요한 개념인 SST, SSE, SSR의 관계를 시각적으로 보여주고 있다
-
왼쪽 그래프: 데이터 포인트(검은 점)와 회귀선(점선)을 보여준다. 각 데이터 포인트에서 회귀선까지의 수직 거리를 빨간색 선으로 표시하고 있으며, 이는 residual을 나타낸다
-
오른쪽 그래프: 분산 분해 개념을 설명하며 다음을 보여준다:
- SST(Total Sum of Squares): Σ(Yi - Ȳ)² - 각 관측값과 평균의 차이 제곱합
- SSE(Sum of Squared Errors): Σ(Yi - Ŷi)² - 각 관측값과 예측값의 차이 제곱합(residual의 제곱합)
- SSR(Regression Sum of Squares): Σ(Ŷi - Ȳ)² - 예측값과 평균의 차이 제곱합
이 세 값의 관계는 SST = SSR + SSE이며, R-square = SSR/SST = 1 - SSE/SST 이다

인공지능.관심 있습니다.