Decision Tree
-
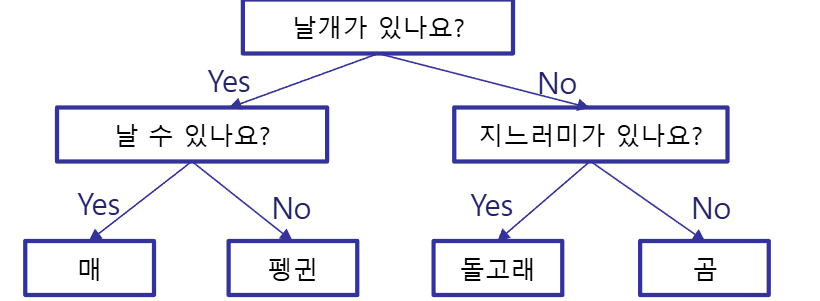
가능한 적은 질문으로 문제를 해결하는 것을 목표
-
기본적인 결정에 도달하기 위하여 Yes/No 질문을 이어나가며 학습
-
규칙의 기준은 순수도(purity)를 가장 높여줄 수 있는 쪽을 먼저 선택해 진행
-
순수도 측정에는 지니 척도 또는 정보 이익이 많이 사용
Decision Tree 구성요소
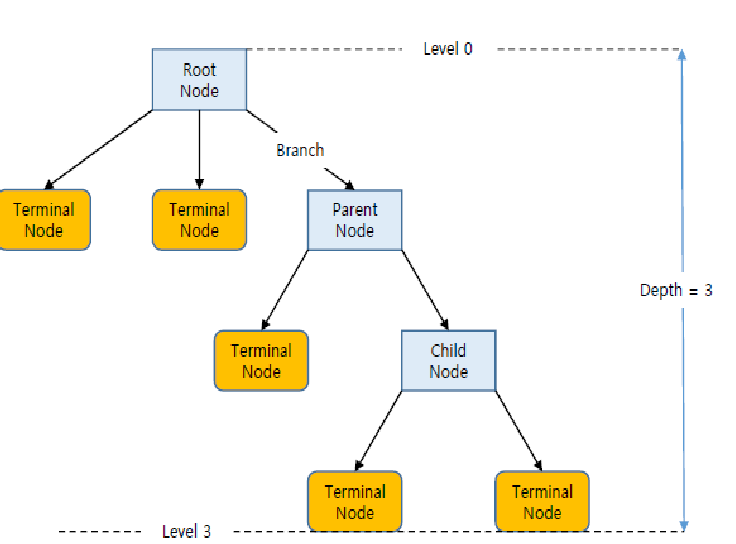
- Root Node : 트리 구조가 시작되는 마디
- Parent Node : 자식 마디의 상위 마디
- Child Node : 하나의 마디로부터 분리되어 나간 2개 이상의 마디들
- Leaf Node : 트리 줄기 끝에 위치하고 자식이 없는 마디
- Depth : 뿌리 마디로 부터 끝 마디를 이루는 층의 수
분석과정
- 성장(growing)
- 분석의 목적에 따라 각 마디에서 적절한 최적의 분리기준을 찾아 트리를 성장시키는 과정.
- 적절한 정지규칙을 통한 의사결정 트리 도출
- 가지치기(pruning)
- 오분류를 크게 할 위험이 높거나 부적절한 추론규칙을 가지는 불필요한 가지를 제거
- 타당성 평가
- 이익 도표(Gain Chart), 위험 도표(Risk Chart)또는 test data로 의사결정 트리 평가
- 해석 및 예측
- 의사결정 트리를 해석하고 예측모형 결정
범주형 목표변수 : 분류 트리
- 목표변수가 이산형
연속형 목표변수 : 회귀 트리
- 목표변수가 연속형
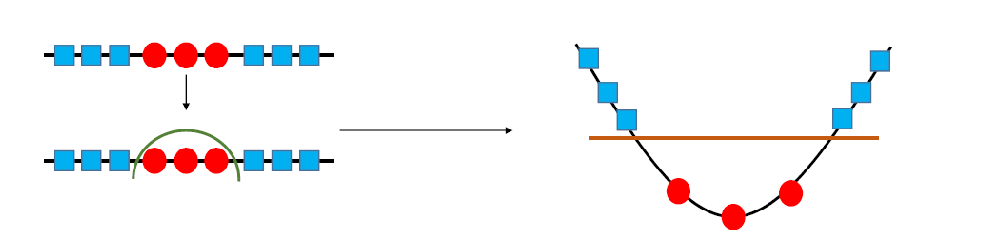
분리 기준
Gini Measure 지니 척도
목적
- 데이터셋을 두 그룹으로 나누는 기준(feature와 threshold)을 찾아
- 지니 지수를 가장 크게 줄이는 분기를 선택
Threshold : 한 feature에서 데이터를 분리할 기준값
- 두번을 복원 추출 했을때, 동일 범주 개체가 선택될 확률
- 순수도가 높을수록 1에, 균등할수록 0.5에 가까워짐
- 순수도가 높은 변수로 가지치기를 한다
- 순수도 = 1 - 불순도
Information gain 정보이익
- 엔트로피(Entropy)의 개념을 사용
SVM
Support Vector Machines
- 서포트 벡터 머신은 가장 정확도가 높은 것 중 하나이며, 다양한 분류 상황에서 좋은 성능을 보이고, 이상치의 영향도 적게 받음
- 기본 방법은 데이터를 나누는 최적의 경계를 만드는 방식

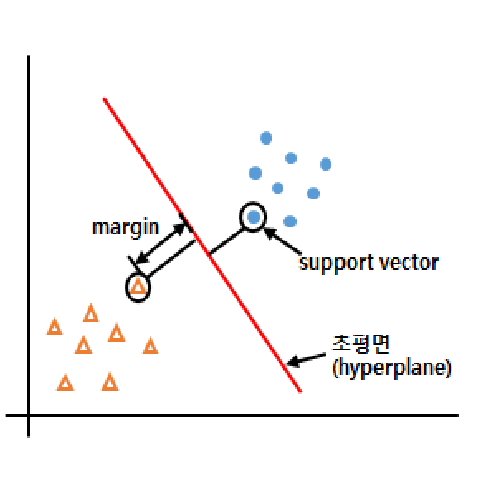
- 마진(Margin): 데이터와 경계 사이의 거리
- Support Vector: 마진에서 가장 가까운 데이터
- 초평면(Hyperplane) : support vector와 margin을 이용해서 그린 선의 최적의 경계
비선형 분류
- 비선형 분류를 하기 위해서는 주어진 데이터를 고차원 특직 공간으로 사상하는 작업이 필요
- 효율적으로 실행하기 위해 커널 트릭 사용
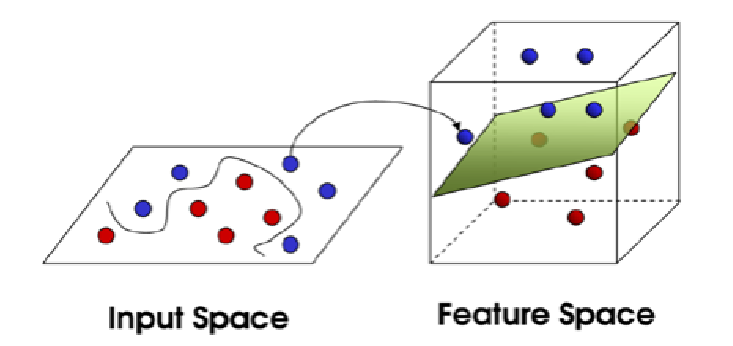
- kernel를 이용하여 차원을 변경하게 되면, 흩어져 있는 데이터에 대해서도 차원을 변경하여 간단하게 나눌 수 있음
- Linear Kernel, Polynomial Kernel, RBF(Radial Basis Function)이 있다
주요 파라미터
- Kernel
- 기본값으로 RBF를 설정(값은 특정 중심에서 거리에 의존하는 함수 값)
- C
- 과적합에 따른 비용
- 기본값으로 1.0 설정
- C값을 낮추면 초평면이 매끄러워지고, 값을 높이면 서포트 벡터들을 더 잘 분류
- Gamma
- 초평면과의 거리
- Gamma값을 낮추면 초평면에서 멀리 떨어진 서포트 벡터들의 영향이 낮고
- 값을 높이면 멀리 떨어진 요소들의 값이 영향이 큼
- 또한 값을 높일 경우 초평면에 인접한 서포트 벡터들의 영향이 커지기 때문에 초평면이 울퉁불퉁하게 됨
주의사항
- SVM은 데이터 스케일링을 잘 해주어야함
- 특성에 해당하는 각 컬럼 값의 범위가 비슷하도록 조정해야함
- 많이 사용하는 방법
- 평균을 0, 분산을 1로 변경하여 모든 특성이 같은 크기를 가지게 함 (StandardScaler)
- 각 컬럼의 값이 0~1 사이로 오도록 함(MinMaxScaler)
- gamma, cost 매개변수 값 조정 잘 하기!
- gamma 기본값 auto 추천
- cost : 기본값 : 1.0
모델 훈련
from sklearn.svm import SVC
svc = SVC()
svc.fit(X_train,y_train)훈련데이터 스케일링
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train) # 훈련 데이터 있는 최솟값과 최댓값을 계산
X_train_scaled = scaler.transform(X_train) # 스케일링 적용
svc = SVC()
svc.fit(X_train_scaled,y_train)
#테스트 데이터 스케일링
X_test_scaled = scaler.transform(X_test)
svc.score(X_test_scaled, y_test)Cost 매개변수 조정
from sklearn.svm import SVC
svc = SVC(C=1000)
svc.fit(X_train_scaled,y_train)
X_test_scaled = scaler.transform(X_test)Gamma 매개변수 조정
from sklearn.svm import SVC
svc = SVC(C=1000,gamma=0.03)
svc.fit(X_train_scaled,y_train)
x_test_scaled = scaler.transform(X_test)- 현재 gamma 매개변수 기본값은 auto로서 1/특성수
- cancer 데이터 경우 특성이 30개라서 1/30 = 0.03

인공지능.관심 있습니다.