예측 모델 성능 평가
데이터 셋 구성
-
Training set (훈련 데이터)
→ 모델을 학습시키는 데 사용 -
Validation set (검증 데이터)
→ 모델 훈련 중 성능을 확인하고, 과적합(overfitting) / 과소적합(underfitting) 을 방지
→ 언제 학습을 멈춰야 할지 판단하는 데 도움 -
Test set (테스트 데이터)
→ 훈련이 끝난 후, 모델이 실제로 잘 작동하는지 성능 평가에 사용
✅ 검증 방법
Holdout 방식
- 데이터를 일정 비율로 나누어 일부는 훈련용(train), 나머지는 테스트용(test) 으로 사용
- 비율 설정 예시: 80% train / 20% test
- 단점:
- train set이 작으면 → 모델 학습이 부족해져 성능 불안정 (분산 ↑)
- test set이 작으면 → 모델 성능 평가의 신뢰도 ↓
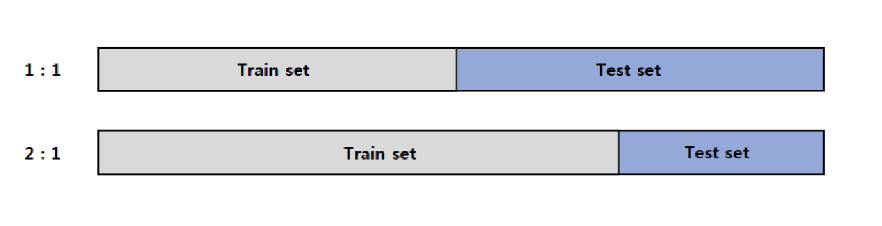
Random Subsampling
- Holdout 방식 반복
- 여러 번 데이터를 나누고 성능 평균을 냄
- 단점: 같은 데이터가 중복될 수 있음
Cross Validation (교차 검증)
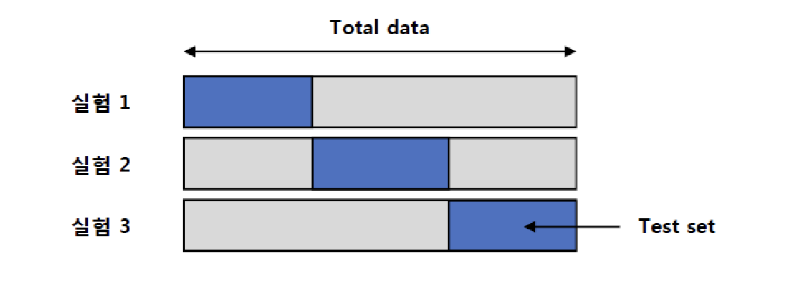
- 데이터를 k개의 부분(folds) 으로 나눔
- 총 k번 반복해서, 매번 하나의 fold는 테스트용, 나머지는 훈련용으로 사용
- 모든 데이터가 최소 한 번은 train과 test에 사용됨
- 장점:
- 데이터 낭비 없이 활용 가능
- 성능 평가의 일관성과 신뢰도 향상
Stratified Sampling (층화 추출)
- 데이터를 클래스(예: 남/여, A/B 등) 별로 나눈 뒤,
- 각 클래스에서 비율을 맞춰 무작위로 추출
- 대표성을 유지하며 데이터 쏠림 방지
- 예: 클래스 A 70%, 클래스 B 30% → 샘플도 A:70%, B:30% 비율 유지
Bootstrap (부트스트랩)
- 중복을 허용하면서 샘플을 여러 번 추출하는 방식
- 원래 데이터에서 같은 항목이 여러 번 뽑힐 수 있음
- 다양한 샘플을 통해 모델의 안정성 평가에 사용
파이썬에서 데이터셋 분리방법 관련 모듈 불러오기
# 데이터셋을 train,test로 분리
from sklearn.model_selection import train_test_split
# Stratified K fold cross validation을 사용.
from sklearn.model_selection import StratifiedKFold
# cross validation 결과의 정확도 측정
from sklearn.model_selection import cross_val_score모델 성능평가 척도
Confusion matrix
- 모델의 성능을 통계적인 수치로 시각화 하는 방법
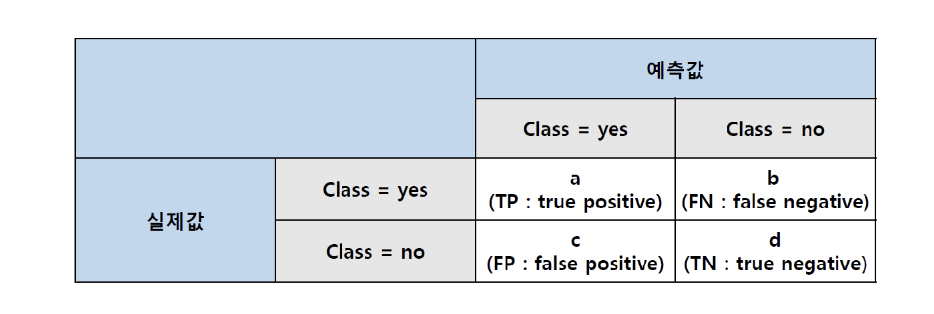
Accuracy
- 모델이 정확하게 분류 또는 예측하는 데이터의 비율
Precision
- 모델이 검출한 데이터중 올바르게 검출된 데이터의 비율
Recall
- 실제 해당 데이터 중 모델이 올바르게 검출된 데이터의 비율

인공지능.관심 있습니다.