파이토치 개요
- 파이토치는 2017년 초에 공개된 딥러닝 프레임워크
- 루아 언어로 토치를 페이스북에서 파이썬 버전으로 내놓은 것
대상
- 넘파이를 대체하면서 GPU를 이용한 연산이 필요한 경우
- 최대한 유연성과 속도를 딥러닝 연구 플랫폼이 필요한 경우
- 텐서는 행렬의 다차원 표현
- 같은 크기의 행렬이 여러개 묶여 있는 것
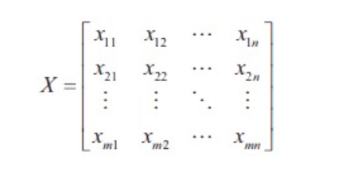
import torch
torch.tensor([[1., -1.], [1., -1.]])연산 그래프
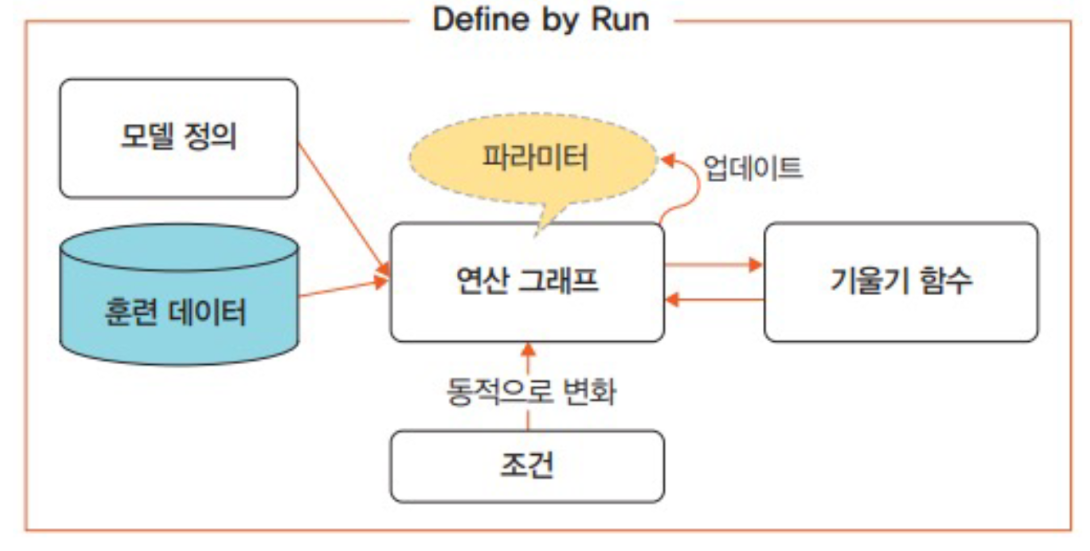
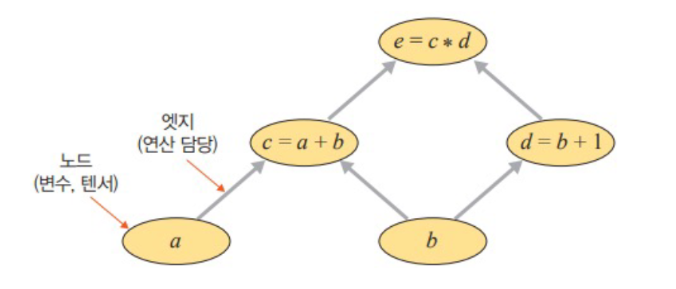
- 방향성이 있으며 변수(예: 텐서)를 의미하는 노드와 연산(예: 곱하기, 더하기)을 담당하는 엣지로 구성
-
신경망은 연산 그래프를 이용하여 계산 수행
-
네트워크가 학습될때 손실 함수의 기울기가 가중치의 바이어스를 기반으로 계산되며, 이후 경사하강법을 사용하여 가중치 업데이트
-
학습 및 추론 속도가 빠르고 다루기 쉬움
-
직관적인 인터페이스라 배우기 쉬움
아키텍처
torch : GPU를 지원하는 텐서 패키지
- 다차원 텐서를 기반으로 다양한 수학적 연산이 가능
torch.autograd : 자동 미분 패키지
- 텐서플로, CNTK같은 다른 딥러닝 프레임워크와 가장 차별되는 패키지
- 자동미분이라고 하는 기술을 채택하여 미분 계산을 효율적으로 처리
- 즉 연산 그래프가 즉시 계산되기 때문에 다양한 신경망을 적용가능
torch.nn : 신경망 구축 및 훈련 패키지
- 합성곱 신경망, 순환 신경망, 정규화 등이 포함되어 손쉽게 신경망 구축 가능
torch.multiprocessing : 파이썬 멀티프로세싱 패키지
- 프로세스 전반에 걸쳐 텐서의 메모리 공유가 가능
- 서로 다른 프로세스에서 동일한 데이터에 대한 접근 및 사용이 가능
torch.utils : DataLoader 및 기타 유틸리티를 제공하는 패키지
- 모델에 데이터를 제공하기 위한 torch.urtils.data.DataLoader 모듈을 주로 사용
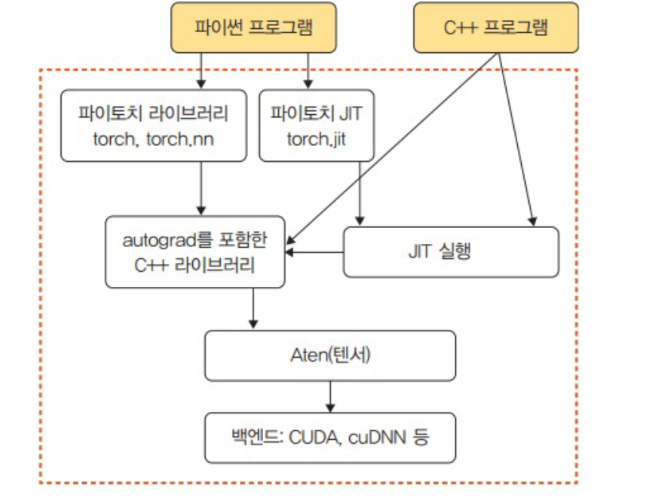
엔진
- Autograd C++, Aten C++, JIT C++, Python API로 구성
연산처리
- 가장 아래 계층에 속하는 C 또는 CUDA 패키지는 상위의 API에서 할당된 거의 모든 계산을 수행
- 여기에서 제공되는 패키지는 CPU와 GPU등을 이용하여 연산 처리
텐서를 메모리에 저장하기
-
텐서는 그것이 1차원이든 N차원이든 메모리에 저장할때는 1차원 배열 형태가 됨
-
즉 1차원 배열 형태여야만 메모리에 저장
-
변환된 1차원 배열을 Storage라고 함
-
offset : 텐서에서 첫번째 요소가 스토리지에 저장된 인덱스
-
stride : 각 차원에 따라 다음 요소를 얻기 위해 건너뛰기가 필요한 스토리지의 요소 개수
와 를 1차원 배열로 바꾸어서 메모리에 저장시키 위해 텐서의 값들을 연속적으로 배치해보자
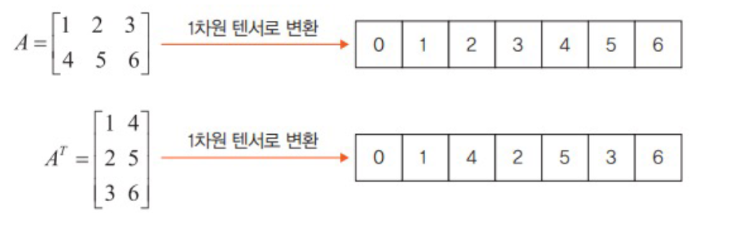
- 다른 shape을 갖지만 storage 값들은 서로 같음
- 와 를 구분하는 용도로 오프셋과 스트라이드를 사용
- 위에 그림의 스토리지에서 2를 얻기 위해서는 1에서 1칸을 뛰어 넘어야 하고, 4를 얻기 위해서는 3을 뛰어 넘어야함
- 텐서에 대한 스토리지의 스트라이드는 (3,1)
반면 A의 전치 행렬은 다름
- 위에 그림의 스토리지에서 4를 얻기 위해서는 1에서 1칸을 뛰어넘어야 하고, 2를 얻기 위해서는 2를 뛰어넘어야함
- 텐서에 대한 스토리지의 스트라이드는 (2,1)
파이토치 기초 문법
텐서 다루기
- 넘파이의 ndarray와 비슷하며 GPU에서의 연산도 가능
import torch
print(torch.tensor([[1,2], [3,4]])) # 2차원 형태의 텐서 생성
print(torch.tensor([[1,2], [3,4]], device = "cuda:0") ) # GPU에 텐서 생성
- 텐서를 ndarray로 변환
temp = torch.tensor([[1,2],[3,4]])
print(temp.numpy())
데이터 준비
- 파이썬 라이브러리 pandas를 이용하는 방법과 파이토리에서 제공하는 데이터를 이용하는 방법
- 데이터가 이미지일 경우, 분산된 파일에서 데이터를 읽은 후 전처리하고 배치 단위로 분할하여 처리
- 데이터가 텍스트일 경우, 임베딩 과정을 거쳐 서로 다른 길이의 시퀀스를 배치 단위로 분할하여 처리
import pandas as pd
import torch
data = pd.read_csv('../class2.csv')
x = torch.from_numpy(data['x'].values).unsqueeze(dim=1).float()
y = torch.from_numpy(data['y'].values).unsqueeze(dim=1).float()- csv파일의 x,y칼럼 값을 넘파이 배열로 받아 tensor로 바꾸기
custom dataset을 만들어서 사용
- 딥러닝은 기본적으로 대량의 데이터를 이용하여 모델 학습
- 데이터를 한 번에 불러와서 훈련시키면 시간과 비용 측면에서 효율적이지 않음
- 데이터를 한번에 다 부르지 않고 조금씩 나누어 불러서 사용하는 방식이 커스텀 데이터셋
class CustomDataset(torch.utils.data.Dataset):
def __init__(self): # 필요한 변수 선언, 데이터셋의 전처리를 함
def __len__(self): # 데이터셋의 길이. 즉 총 샘플의 수를 가져오는 함수
def __getitem__(self, index): # 데이터셋에서 특정 데이터를 가져오는 함수예시
import pandas as pd
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class CustomDataset(Dataset):
def __init__(self,csv_file):
self.label = pd.read_csv(csv_file)
def __len__(self):
return len(self.label)
def __get__item(self,idx):
sample = torch.tensor(self.label.iloc[idx,0:3]).int()
label = torch.tensor(self.label.iloc[idx,3]).int()
return sample, labeltensor_dataset = CustomDataset('../covtype.csv')
dataset = DataLoader(tensor_dataset, batch_size = 4,shuffle=True)torch.utils.data.DataLoader
- 데이터로더 객체는 학습에 사용될 데이터 전체를 보관했다가 모델 학습을 할때 배치 크기만큼 데이터를 꺼내서 사용
- 데이터를 미리 잘라 놓는 것이 아닌 내부적으로 반복자(iterator)에 포함된 인덱스를 이요하여 배치 크기만큼 데이터를 반환한다는 것
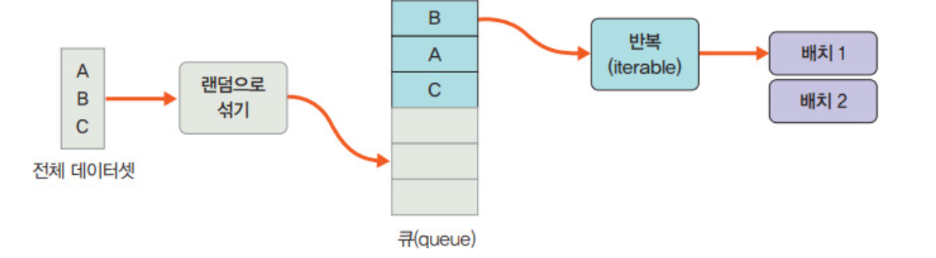
데이터로더는 for문을 이용하여 구문을 반복 실행하는 것과 같음
for i, data in enumerate(dataset,0):
print(i, end='')
batch=data[0]
print(batch.size())
TorchVision
- 파이토치에서 제공하는 데이터셋들이 모여 있는 패키지
- MNIST, ImageNet을 포함한 유명한 데이터셋들을 제공
예.. ye
import torchvision.transforms as transforms
mnist_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (1.0,))
]) # 평균이 0.5, 표준편차가 1.0 되도록 데이터의 분포 조정
from torchvision.datasets import MNIST
import requests
download_root = '../data/MNIST_DATASET' # 내려받을 경로
train_dataset = MNIST(download_root, transforms=mnist_transform, train=True,download=True) # 훈련
valid_dataset = MNIST(download_root, transforms=mnist_transform, train=False,download=True) # 검증
test_dataset = MNIST(download_root, transforms=mnist_transform, train=False,download=True) # 테스트모델 정의
단순 신경망 정의
- nn.Module을 상속받지 않는 매우 단순한 모델을 만들때 사용
model = nn.Linear(in_features=1, out_features=1, bias=True)nn.Module()을 상속하여 정의하는 방법
- 파이토치에서 nn.Module을 상속받는 모델은 기본적으로 init, forward함수를 포함
__init__(): 모델에서 사용될 모듈(nn.Linear, nn.Conv2d), 활성화 함수 정의forward(): 모델에서 실행되어야 하는 연산 정의
class MLP(module):
def __init__(self, inputs):
super(MLP, self).__init__()
self.layer = Linear(inputs , 1) # 계층 정의
self.activation = Sigmoid() # 활성화 함수 정의
def forward(self, X):
X = self.layer(X)
X = self.activation(X)
return X- nn.Sequential을 사용하면
__init__()에서 사용할 네트워크 모델들을 정의해 줄 뿐만 아니라 forward() 함수에서 모델에서 실행되어야 할 계산을 좀 더 가독성이 뛰어나게 코드로 작성 가능 - Sequential 객체는 그 안에 포함된 각 모듈을 순차적으로 실행해줌
MLP(nn.Module) 클래스 정의
- PyTorch에서 모델을 정의할 때는 반드시
nn.Module을 상속받아야 함. __init__()에서는 모델의 레이어(구조)를 정의.forward()에서는 입력이 레이어를 거쳐 출력으로 가는 계산 흐름을 정의.
__init__() 내 layer 정의
self.layer1
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)- 입력: RGB 이미지 (채널 3)
Conv2d: 5x5 필터 64개로 convolution 적용.ReLU: 비선형 활성화 함수로, 음수를 0으로 바꿈.MaxPool2d(2): 2x2 영역에서 최댓값만 추출하여 다운샘플링.
self.layer2
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=30, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)- 앞 단계 출력 64채널을 입력으로 받아 5x5 필터 30개로 convolution.
- 이후 ReLU, MaxPool로 처리.
self.layer3
self.layer3 = nn.Sequential(
nn.Linear(in_features=30*5*5, out_features=10, bias=True),
nn.ReLU(inplace=True)
)- 합성곱 결과를 평탄화(flatten)한 후, 전결합층(FC)을 통해 10차원 출력으로 변환.
- ReLU로 비선형성 유지.
📌 주의: 30*5*5는 입력 이미지 크기(예: 32x32)일 때 convolution과 pooling을 거친 후의 크기에 맞춘 값. 다른 입력 크기를 사용할 경우 이 숫자를 조정해야 함
forward(self, x)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.shape[0], -1) # Flatten
x = self.layer3(x)
return x- 입력
x를 순서대로 각 layer에 통과시킴. x.view(x.shape[0], -1): 배치 차원을 유지하면서 나머지를 1차원으로 평탄화함.- 최종 출력은 10차원 벡터 (예: 10개의 클래스에 대한 예측 확률 등).
모델 객체 생성
model = MLP()- 모델 클래스를 인스턴스화 하여
model객체로 생성. - 이후 학습이나 추론 등에 사용 가능.
왜 레이어가 3개인가?
-
기본적인 CNN 구조 구성
-
보통 CNN은 다음과 같은 구조 구성:
Conv + ReLU + Pool→Conv + ReLU + Pool→Flatten + FC -
위 구조는 이미지의 공간적 특징 추출 → 요약 및 분류 단계를 밟음
-
따라서 현재 코드의
layer1,layer2는 합성곱 특징 추출기,layer3은 분류기 역할을 함
-
-
모델이 너무 복잡하면 오버피팅 위험
- 너무 많은 레이어는 작은 데이터셋에선 과적합(overfitting)을 유발함.
- 반면 너무 적으면 표현력이 부족함.
- 현재 구조는 학습 속도, 성능, 복잡도 간 균형을 고려한 설계
-
초보자나 중간 단계 학습자에게 적절한 구조
- 레이어가 3개 정도면 구조 이해나 디버깅이 쉬움.
왜 인/아웃 크기를 그렇게 정했는가?
-
첫 Conv 레이어:
in_channels=3,out_channels=64-
3: RGB 이미지 입력 -
64: 필터 개수. 많을수록 다양한 특징을 잡을 수 있음.- 32~64는 보통 첫 레이어에 많이 쓰이는 값.
-
-
두 번째 Conv 레이어:
in_channels=64,out_channels=30- 앞 레이어의 출력 채널(64)을 입력 채널로 받음.
- 30은 약간 줄인 형태 → 채널 수를 점점 줄이면서 정보 요약.
-
FC (Linear) 레이어:
in_features=30*5*5-
여기서 중요한 건 이 값이 합성곱+풀링을 거친 후의 feature map 크기에 맞춰져 있어야 한다는 점.
-
예를 들어 입력 이미지가
32x32면:- Conv(5x5, stride=1) → 28x28
- MaxPool(2) → 14x14
- Conv(5x5) → 10x10
- MaxPool(2) → 5x5
-
따라서 마지막 출력 크기 =
30 x 5 x 5
-
-
out_features=10- 출력이 10개인 이유: 보통 10개의 클래스 분류 문제를 가정 (예: CIFAR-10, MNIST 등).
요약
| 항목 | 이유 |
|---|---|
| 레이어 수 3개 | Conv2 + FC 구성은 CNN의 기본 구조 |
| Conv 채널 수 | 표현력(64) → 요약(30) |
| FC 입력 크기 | Conv + Pool을 거친 후의 결과 크기 |
| FC 출력 크기 | 10 클래스 분류 문제라고 가정했기 때문 |
다음처럼 정리함:
파라미터 정의
1. 손실 함수 (Loss Function)
-
모델이 예측한 값과 실제 값 사이의 오차를 계산함
-
손실 값을 줄이는 방향으로 모델을 학습시킴
-
종류:
- MSELoss: 회귀(regression) 문제에 사용함 (
(y - ŷ)^2형태) - BCELoss: 이진 분류(binary classification)에 사용함
- CrossEntropyLoss: 다중 클래스 분류(multi-class classification)에 사용함
- MSELoss: 회귀(regression) 문제에 사용함 (
2. 옵티마이저 (Optimizer)
-
손실 함수로부터 계산된 **기울기(gradient)**를 바탕으로 파라미터를 업데이트함
-
주요 기능:
step(): 파라미터 업데이트zero_grad(): 이전 기울기 초기화params,defaults: 옵티마이저에 들어가는 기본 요소
-
다양한 옵티마이저 종류:
optim.SGD: 가장 기본적인 경사하강법optim.Adam: 학습률 자동 조절 + 모멘텀 포함optim.Adamax,optim.Adagrad,optim.RMSProp,optim.Rprop,optim.SparseAdam등
3. 학습률 스케쥴러 (Learning Rate Scheduler)
-
학습률을 에포크에 따라 조절함
-
초반에는 빠르게 학습하다가 점점 학습률을 줄여 세밀한 수렴 유도
-
종류:
optim.lr_scheduler.StepLR: 일정 에포크마다 학습률을 일정 비율로 감소optim.lr_scheduler.MultiStepLR: 정해진 에포크들에서만 감소optim.lr_scheduler.LambdaLR: 사용자 정의 방식으로 조절 가능
전역 최소점과 최적점
-
손실함수는 실제값과 예측값 차이를 수치화 해주는 함수
-
이 오차값이 클수록 손실 함수의 값이 크고, 오차 값이 작을수록 손실 함수의 값이 작아짐
-
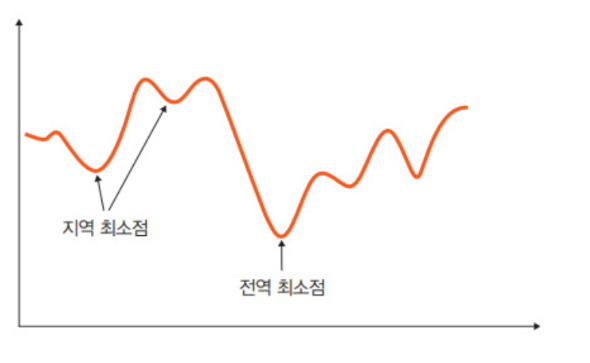
전역 최소점: 오차가 가장 작을때의 값. 우리가 최종적으로 찾고자 하는 최적점
-
지역 최소점: 전역 최소점을 찾아가는 과정에서 만나는 홀과 같은 것. 옵티마이저가 지역 최소점에서 학습을 멈추면 최솟값을 갖는 오차를 찾을 수 없는 문제가 발생
모델의 파라미터 정의
from torch.optim import optimizer
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer=optimizer,lr_lambda=lambda epoch: 0.95 ** epoch)
for epoch in range(1, 100+1):
for x,y in dataloader:
optimizer.zero_grad()
loss_fn(model(x),y).backward()
optimizer.step()
scheduler.step()criterion = torch.nn.MSELoss()
- 손실 함수(Loss function)를 평균 제곱 오차(MSE) 로 설정.
- 회귀(regression) 문제에서 자주 사용됨.
- 모델 출력과 정답
y의 차이를 제곱해서 평균을 낸 값.
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
- 옵티마이저를 확률적 경사 하강법(SGD) 으로 설정.
model.parameters(): 학습할 파라미터 목록을 전달.lr=0.01: 학습률(learning rate) 설정.momentum=0.9: 이전 gradient를 일부 기억해서 빠르게 수렴하도록 도움.
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer=optimizer, lr_lambda=lambda epoch: 0.95 ** epoch)
-
러닝레이트 스케줄러 설정.
-
LambdaLR: 사용자 정의 함수(lr_lambda)를 통해 학습률을 조절. -
lambda epoch: 0.95 ** epoch: 학습이 진행될수록 학습률을 0.95씩 곱해 감소시킴.- 예: epoch 1 → 0.0095, epoch 2 → 약 0.009025 ...
학습 루프
for epoch in range(1, 100+1):- 에폭(epoch)을 1부터 100까지 반복.
- 모델을 전체 데이터셋에 대해 총 100번 학습시킴.
for x, y in dataloader:dataloader를 통해 배치 단위로 데이터와 정답 레이블을 가져옴.x: 입력 데이터,y: 타겟 값.
optimizer.zero_grad()- 이전 배치에서 계산된 gradient 초기화 (초기화하지 않으면 gradient가 누적됨).
loss_fn(model(x), y).backward()- 현재 모델 출력과 정답
y를 비교하여 손실(loss)을 계산. backward()를 호출하면 각 파라미터에 대한 gradient가 계산됨.
optimizer.step()- 계산된 gradient를 바탕으로 파라미터를 업데이트.
scheduler.step()- 매 epoch마다 학습률을 갱신.
요약
| 코드 | 기능 |
|---|---|
MSELoss | 회귀용 손실 함수 |
SGD | 기본 옵티마이저, 모멘텀 추가 |
LambdaLR | 학습률 점차 감소 |
optimizer.zero_grad() | gradient 초기화 |
loss.backward() | gradient 계산 |
optimizer.step() | 파라미터 업데이트 |
scheduler.step() | 학습률 갱신 |
모델 훈련
- 가장 먼저 필요한 절차는
optimizer.zero_grad()메서드를 이용하여 기울기를 초기화하는 것 - PyTorch는 기울기 값을 계산하기 위해
loss.backward()메서드를 사용 - 이때 새로운 기울기 값이 이전 기울기 값에 누적되어 계산됨
- 이 방식은 RNN처럼 시간에 따른 gradient 누적이 필요한 경우에 효과적
- 하지만 누적 계산이 필요 없는 일반적인 모델에서는 매번
optimizer.zero_grad()를 호출해 미분값을 초기화해야 함
for epoch in range(100):
yhat = model(x_train)
loss = criterion(yhat, y_train)
optimizer.zero_grad() # 기울기 초기화
loss.backward() # 기울기 자동 계산
optimizer.step() # 파라미터 업데이트모델 평가
함수 방식
import torch
import torchmetrics
preds = torch.randn(10, 5).softmax(dim=-1)
target = torch.randint(5, (10,))
acc = torchmetrics.functional.accuracy(preds, target)torchmetrics.functional.accuracy: 함수 방식으로 정확도 평가preds: 소프트맥스를 적용한 예측값target: 실제 정답 레이블- 이 방식은 단순하고 빠르게 한 번의 평가 결과를 구할 때 유용
모듈 방식
import torch
import torchmetrics
metric = torchmetrics.Accuracy() # 정확도 평가기 초기화
n_batches = 10
for i in range(n_batches):
preds = torch.randn(10, 5).softmax(dim=-1)
target = torch.randint(5, (10,))
acc = metric(preds, target)
print(f"Accuracy on batch {i}: {acc}") # 현재 배치 정확도
acc = metric.compute()
print(f"Accuracy on all data: {acc}") # 전체 데이터 정확도torchmetrics.Accuracy()객체를 만들어 여러 배치에 걸쳐 누적된 정확도 계산 가능metric.compute()를 사용하면 모든 배치의 누적 평균 정확도를 구할 수 있음
훈련 과정 모니터링 (TensorBoard 사용)
import torch
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("../chap02/tensorboard") # 로그 저장 디렉터리
for epoch in range(num_epochs):
model.train() # 훈련 모드 설정
batch_loss = 0.0
for i, (x, y) in enumerate(dataloader):
x, y = x.to(device).float(), y.to(device).float()
outputs = model(x)
loss = criterion(outputs, y)
writer.add_scalar("Loss", loss, epoch) # 오차 기록
optimizer.zero_grad()
loss.backward()
optimizer.step()
writer.close()SummaryWriter: TensorBoard에 로그를 저장하는 객체writer.add_scalar("Loss", loss, epoch): 에폭마다 손실값 기록- 저장된 로그는 터미널에서
tensorboard --logdir=../chap02/tensorboard명령어로 시각화 가능
학습/평가 모드 전환
model.train(): 드롭아웃, 배치 정규화 등을 훈련용 설정으로 활성화model.eval(): 평가용 설정으로 전환, 모든 노드를 그대로 사용- 정확한 성능 평가를 위해 반드시
eval()로 전환 후with torch.no_grad()로 gradient 계산 방지
model.eval()
with torch.no_grad():
valid_loss = 0
y_hat = []
for x, y in valid_dataloader:
outputs = model(x)
loss = F.cross_entropy(outputs, y.long().squeeze())
valid_loss += float(loss)
y_hat += [outputs]
valid_loss = valid_loss / len(valid_dataloader)