JAVA 웹개발과 Spring의 역사
한국에서는 1995년에 JAVA가 출시되고, 2000년도에 들어서서는 PC 보급율이 높아지면서 웹 사용자도 크게 증가하고, Web도 폭발적으로 성장하는 시기가 온다. 이때까지는 웹개발을 CGI를 이용해서 개발했었는데 멀티 쓰레드가 안되서 요청이 올때마다 프로세서를 생성하는 방식으로 작동하기 때문에, 처리 속도와 확장성 면에서 한계가 있었고, 멀티쓰레드를 지원하는 자바 서블릿을 기반으로한 EJB(Enterprise Java Beans)웹개발방식이 도입되었다.
EJB는 분산도 되고 트랜잭션도 선언적으로 되고 서버 분산도 되고 많은 장점이 있었기에 당시 많이 사용되었는데 설정이 매우 복잡해서 사용하기 어려웠다. 그리고 가격도 비쌌다. EJB가 제공하는 인터페이스를 구현하고 의존하며 개발해야 하는데 코드로 지저분하고 라이프 사이클도 알기 어렵고 컨테이너 띄우는 데도 오래걸리게 되므로 순수하게 옛날자바로 돌아가자는 POJO(Plain Old Java Object)가 등장했다.

무겁고 복잡한 EJB지옥에 불타던 개발자 '로드 존슨'은 EJB에 분노하여 비판하는 책을 쓰고(2002년) 내가 만들어도 이거보다 낫겠다며 퇴근하고 오픈소스를 만들기 시작하여 Hibernate을 만드는데 이것이 인기를 끌고
모두가 Hibernate을 쓰기 시작하자 java 표준 진영에서도 EJB는 망했다고 인정하며 개빈킹을 영입하며 자바 표준 인터페이스인 JPA를 만들게 된다.
(JPA는 표준 인터페이스로서 구현체는 따로 만들어야 하는데, 현재도 그 구현체로 Hibernate를 쓰고 있다.)
책 출간 직후 유겐 휠러(Juergen Hoeller)가 로드 존슨에게 오픈소스 프로젝트를 제안하는데 겨울을 넘어 새로운 시작이라는 뜻으로 '스프링'프로젝트가 시작된다. 스프링의 핵심 코드의 상당수는 유겐 휠러가 지금도 개발하고 있다.(매우 천재적인 개발자라고 볼 수 있다.)
국내에서도 JAVA 개발자의 수요가 증가했고, 지금까지도 JAVA는 인기있는 언어로 대규모 엔터프라이즈 시스템 및 웹 어플리케이션 개발에 많이 사용되고 있다.
2004년 'Spring 1.0'이 출시되면서 훨씬 심플해진 개발 방식을 느끼고 큰 인기를 받게 된다.
그런데 웹 사이트의 수는 급증했지만 개발자가 개발을 마치고 회사를 떠나면 유지보수의 어려움이 생겨났다. 사람마다 개발하는 방식이 다르기 때문에 파악하기가 쉽지 않았기 때문이다. 그래서 이때 프레임워크가 등장하게 된다. 프레임워크를 이용하면 같은 방식으로 정형화 된 방식으로 개발하기 때문에 다른 개발자가 봐도 이해하기가 쉬우니 유지보수가 쉬워지고 기본 구조가 만들어져 있는 상황에서 코드를 작성하므로 생산성도 증가한다.
이후 스프링 프레임워크는 계속 개발되어 새로운 버전이 출시되었고,
2014년에는 설정이 간편한 'Spring Boot 1.0'이 출시되었다.
2017년에는 프레임워크5.0, 스프링부터 2.0 이 출시되어 리액티브 프로그래밍을 지원하게 되었다.
2024년 현재는 스프링은 6버전, 스프링부트는 3.3버전까지 나왔다.
간략하지만 java 개발의 역사를 배우니 유지보수의 중요성이 절실히 느껴진다. 과거에 XML로 스프링을 설정해야 할 때는 설정이 프로젝트의 절반이다라는 우스갯소리도 있었는데 스프링 부트가 나와서 얼마나 간편한지 모른다. 스프링부트로 개발에 입문하게 되어 행운이라는 생각이 들었다. 나도 미래의 개발자에게 도움을 주는 개발자가 되어야지.
Spring
- 스프링은 자바 언어 기반의 프레임워크
- 자바 언어의 가장 큰 특징 - 객체 지향 언어
- 스프링은 객체 지향언어가 가진 강력한 특징을 살려내는 프레임 워크
- 스프링은 좋은 객체 지향 애플리케이션을 개발할 수 있게 도와주는 프레임 워크
Spring boot
스프링부트(Spring Boot)는 스프링 프레임워크의 설정을 간소화하여 쉽게 웹 애플리케이션을 개발할 수 있게 도와주는 도구이다.
- 단독으로 실행 가능 하다
- Tomcat, Jetty, Undertow와 같은 웹 서버를 내장하고 있다.(WAR 파일을 배포할 필요가 없다)
- 손쉬운 빌드 구성을 위한 starter종속성을 제공하고, 외부 라이브러리를 자동으로 구성해준다.
(스프링이 필요한 버전을 챙겨주고 조합이 잘 맞는지 테스트하여 알려준다.) - 메트릭 모니터링, 상태 검사, 외부화된 구성과 같은 프로덕션에 적합한 기능을 제공한다.
- 코드 생성이 전혀 없고 XML 구성이 필요하지 않다.
Spring Framework의 핵심기술
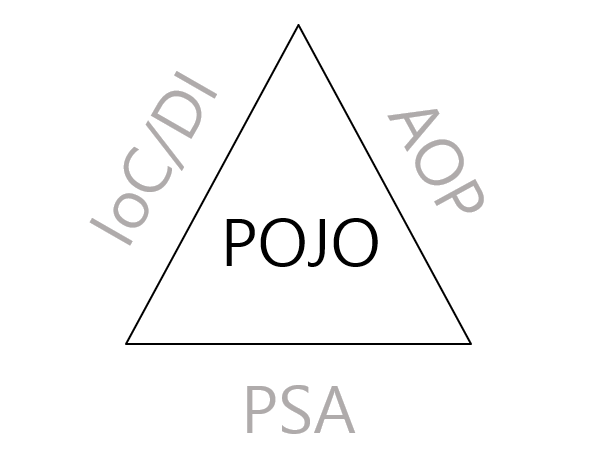
이 그림에서 POJO는 Spring에서 사용하는 핵심 개념들에 둘러 싸여져 있는 모습이다. 이는 POJO라는 것을 IoC/DI, AOP, PSA를 통해서 달성할 수 있다는 것을 의미한다.
POJO (Plain Old Java Object)
POJO란 Plain Old Java Object의 약자로, 이를 직역하면 순수하고 오래된 자바 객체이다.
POJO는 자바가 가진 객체 지향적인 원리에 충실하면서 환경과 기술에 종속되지 않고, 필요에 따라 재활용될 수 있는 방식으로 설계된 오브젝트를 의미한다.
- Java나 Java의 스펙에 정의된 것 이외에는 다른 기술이나 규약에 얽매이지 않아야 한다.
- 특정 환경에 종속적이지 않아야 한다.
- 특정 환경이나 기술에 종속적이지 않으면 재사용이 가능하고, 확장 가능한 유연한 코드를 작성할 수 있다.
- 저수준 레벨의 기술과 환경에 종속적인 코드를 제거하여 코드를 간결해지며 디버깅하기에도 상대적으로 쉬워진다.
- 특정 기술이나 환경에 종속적이지 않기 때문에 테스트가 단순해진다.
- 객체지향적인 설계를 제한 없이 적용할 수 있다. (가장 중요한 이유)
IoC (제어의 역전)
기존의 자바 개발 방식에서는 객체를 생성하고 언제 사용할지, 언제 소멸시킬지를 개발자가 직접(new 키워드로) 결정했다. 즉, 프로그램의 제어 흐름을 개발자가 모두 가지고 있었다.
하지만 스프링에서는 이러한 제어권이 개발자 → 스프링 컨테이너로 역전된다.
객체(Bean)의 생성, 의존 관계 설정, 생명주기 관리 등을 프레임워크가 대신 관리해주는 것이다.
개발자는 이제 객체를 직접 만드는 대신 "필요한 객체를 달라"고 요청만 하면 된다.
예를 들어 new UserService()처럼 직접 생성하지 않고, 스프링 컨테이너가 미리 만들어둔 UserService 빈을 주입받아 사용한다.
➡ 이것이 바로 제어의 역전(IoC) 이다.
➡ 개발자는 객체 조립이 아니라 핵심 비즈니스 로직에 집중할 수 있게 된다.
DI (의존관계 주입)
IoC는 “제어권을 넘긴다”는 큰 개념이고, DI는 IoC를 실천하는 가장 구체적인 방법이다.
어떤 객체가 다른 객체를 필요로 할 때, 기존에는 내부에서 직접 new로 만들었다.
Car car = new Car();
car.engine = new Engine(); // Car가 Engine을 직접 생성 → 강한 결합하지만 DI에서는 필요한 객체를 외부에서 주입해준다.
Car car = new Car(new GasEngine()); // 생성자를 통해 의존성 주입이렇게 했을 때 얻는 이점은 매우 크다.
Car는 더 이상 구체적인 GasEngine 클래스에 의존하지 않고, Engine 인터페이스만 알면 됨
나중에 ElectricEngine으로 바꿔도 Car 코드를 수정할 필요 없음
테스트에서는 MockEngine을 넣어서 쉽게 단위 테스트 가능
확장성과 유지보수성이 크게 향상됨
➡ 즉, DI를 통해 클래스 간 결합도를 낮추고, 다형성을 극대화하며, 변경에 유연한 설계를 만들 수 있다.
➡ 스프링에서는 생성자 주입, setter 주입, @Autowired 등을 통해 DI를 자동화해준다.
AOP (Aspect Oriented Programming)
관점 지향 프로그래밍이라고 번역하기도 하지만 결국 목적은 공통 관심 사항(cross-cutting concern)과 핵심 관심 사항(core concern)을 분리하는 것 이다.
만약 모든 메소드의 호출 시간을 측정하고 싶다면?
1000개의 메소드의 시작과 끝에 모두 코드를 추가해야 한다.
그러나 시간을 측정하는 로직은 핵심 관심사항이 아니라 공통 관심사항임에도
메소드안에 로직이 섞이게 되어 유지보수가 어렵게 되는 문제도 발생한다.
그러나 시간을 측정하는 로직을 공통로직으로 만들기가 매우 어렵고,
시간측정로직이 변경시에 모든 메소드를 일일히 수정해야 한다.
AOP 적용
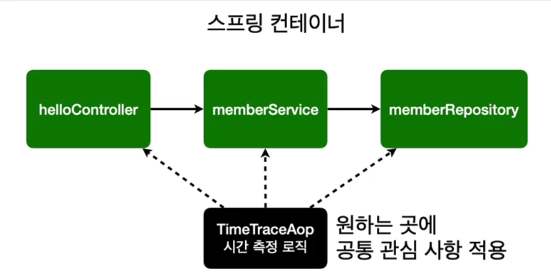
스프링에서는 AOP를 편하게 사용할 수 있게 도와주는데 코드를 통해서 살펴보자.
@Around를 통해서 AOP를 적용할 부분을 지정할 수 있다.
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
@Component // 또는 config에 빈으로 등록해도됨.
@Aspect
public class TimeTraceAop {
@Around("execution(* hello.hellospring..*(..))")
public Object execute(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
System.out.println("START: " + joinPoint.toString());
try {
return joinPoint.proceed();
} finally {
long finish = System.currentTimeMillis();
long timeMs = finish - start;
System.out.println("END: " + joinPoint.toString() + " " + timeMs + "ms");
}
}
}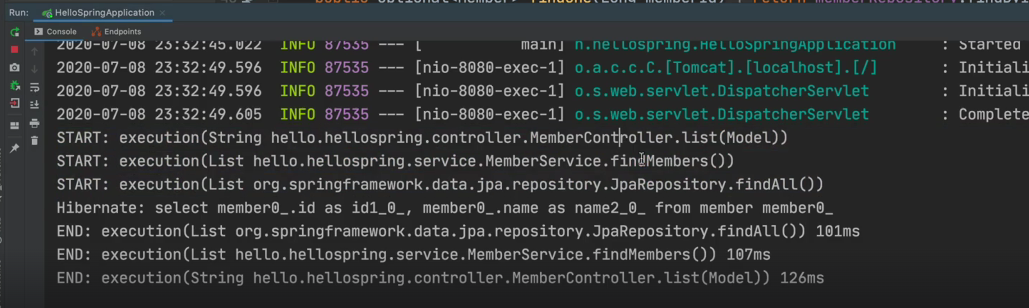
이런식으로 병목이 발생하는 부분을 찾을 수 있는 코드를 만들어보았다.
중간에 인터셉팅해서 '이런조건이면 다음으로 넘어가지마.' 처럼 원하는 대로 코드를 변경하면 된다.
이제 핵심관심사항을 깔끔하게 유지할 수 있고 시간측정 로직을 변경하는 것도 중복이 없기에 편리하다.
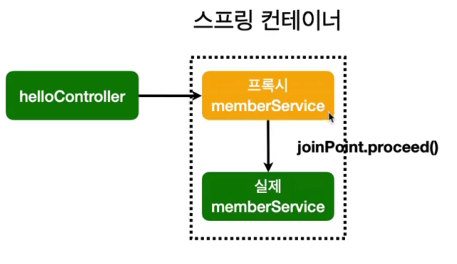
실제 동작 방식은 스프링컨테이너 안에서 AOP가 있으면 프록시(가짜)서비스 빈을 등록한 다음 프록시에서 AOP작업을 하고, 작업이 끝나면 joinPoint.proceed() 를 통해 내부적으로 이것저것 타고가서 진짜 서비스 빈을 호출한다.
PSA (일관된 서비스 추상화)
PSA는 스프링이 제공하는 “통합 인터페이스” 개념이다.
쉽게 말해, 구현 방식이나 환경이 달라도 개발자는 항상 같은 방식으로 사용할 수 있게 해주는 추상화 계층이다.
예를 들어, HTTP 요청을 처리할 때는 과거에는 Servlet, Filter, HttpServletRequest 등을 직접 다뤄야 했다.
하지만 스프링은 이런 복잡한 내부를 모두 추상화해서 개발자가 단순히 아래처럼만 작성하면 된다.
@GetMapping("/hello")
public String hello() { ... }이 한 줄 뒤에는 아래와 같은 수많은 기술이 자동으로 동작하지만, 개발자는 전혀 신경 쓸 필요가 없다.
- DispatcherServlet
- HandlerMapping
- HandlerAdapter
- Interceptor
- ArgumentResolver
- ViewResolver
Spring MVC : 웹 요청 처리 추상화 (@RequestMapping, @GetMapping)
Spring Data JPA : JPA / Hibernate 등을 감싸서 CRUD를 쉽게 추상화 (findAll(), save())
JdbcTemplate : JDBC의 반복 코드를 추상화
TransactionManager : 어느 DB를 사용하든 @Transactional 한 줄로 트랜잭션 처리
➡ PSA 덕분에 개발자는 “어떤 기술을 쓰는지”보다 “무엇을 할지”에 집중할 수 있다.
➡ 스프링이 내부 구현체를 적절히 연결해주며, 나중에 다른 기술로 바꿔도 코드 변경이 최소화된다.
