Association Rule Mining
전 주에 다뤘던 Apriori Algorithm에서 조금 더 발전된 형태의 알고리즘을 FP-Growth Algorithm이라고 할 수 있다.
그래서 FP-Growth를 다루기 전, Apriori에 대해서 다루어보고, 왜 FP-Growth가 나오게 됐는지부터 차근차근 정리하고자 한다.
Apriori Algorithm
사실 이 Apriori 알고리즘의 경우, 이전 글에서 좀 더 자세하게 다뤄놨다.
https://velog.io/@sohtks/Recommendation-System-Association-Rule-Mining-%EC%97%B0%EA%B4%80-%EA%B7%9C%EC%B9%99
여기서 더 참고하면 좋을듯하다.
정의
- idataset에서 충분히 자주 표시되는 개별의 item을 찾아서 식별하고, 더 큰 itemset으로 확장하여 진행함
- "frequent itemset"만 고려함
장단점
-
장점
- 원리가 간단해서 쉽게 이해할 수 있고 이 의미를 쉽게 파악해
- 또한 유의한 연관성을 갖는 구매패턴을 다양하게 찾아줌
-
단점
- 문제는 데이터가 커질 때 발생
- 데이터가 크다면 속도가 느리고 연산량이 많아짐
- 실제 알고리즘을 사용하게 될 때, 너무 많은 연관상품들이 나타나는 문제가 발생!
- 연관 상품들이 상관관계는 의미하지만 그것이 인과를 의미하진 않음.
- 결과만을 본다면 어떤 것이 원인인지 파악하기 힘듦
- 우리의 경험에 의한 지식으로 당연히 어떤 요인이 원인이라는 것을 단번에 알 수는 있지만, 복잡한 패턴이 나오면 판단하기 쉽지 않음
FP-Growth
정의
Apriori처럼 연관 규칙 생성 알고리즘 중에 하나이며, Apriori와의 차이는 FP-Tree를 생성한 후에 최소 support 이상의 패턴만을 추출한다는 것이다.
- candidate itemset 생성하지 않고 frequent itemset을 찾는다는 것!
접근법
- 1단계: FP-Tree라는 호환 데이터 구조를 구축함
- 데이터 세트 위에 2 Passes를 사용하여 제작됨
- 트리 형태의 데이터 구조
- 2단계: FP-트리에서 직접 frequent itemsets 추출
단계별 프로세스
<1단계. FP-Tree 데이터 구축>
Pass 1.
- 데이터를 스캔하고 각 항목에 대한 지원을 찾음
- infrequent item은 폐기
- frequent item을 support에 따라 내림차순으로 정렬함
- 공통된 prefix (= 부모노드와 비슷한 개념) 를 공유할 수 있도록 FP-Tree를 작성할 때 이 순서를 사용함
Pass 2
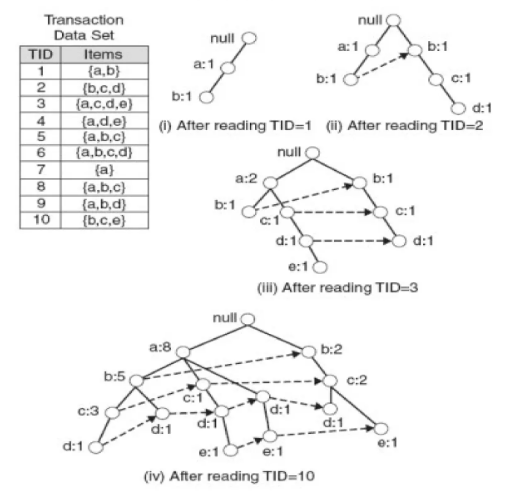
해당 트리의 Node는 item에 해당하며 counter가 존재함
- FP-Growth는 한 번에 하나의 트랜잭션을 읽고, 이를 경로에 매핑함
- 고정된 순서(Fixed order)가 사용되므로 트랜잭션이 항목을 공유할 때(동일한 prefix를 가진 경우) 경로가 겹칠 수 있음
- 이 경우 카운터가 증분됨
- 포인터는 동일한 항목을 포함하는 노드 간에 유지되며, 단순 연결 리스트(점선)를 만듦
- 경로가 겹칠수록 압축률이 높아짐
- FP-tree는 메모리에 들어갈 수 있음!
- FP-Growth 알고리즘에서의 Frequent itemsets은 FP-Tree에서 추출한 것임!
FP-트리 크기
FP-Tree는 일반적으로 압축되지 않은 데이터보다 작은 크기를 가짐
- 일반적으로 많은 트랜잭션이 항목(따라서 접두사)을 공유함
- Best 시나리오: 모든 트랜잭션에는 동일한 itemset이 포함됨
- FP-트리가 1경로로만 이루어짐
- Worst 경우: 모든 트랜잭션에는 고유한 항목 집합이 있음 (= 공통적인 항목 없음)
- FP-트리의 크기는 적어도 원본 데이터만큼 큼
- FP-트리의 저장 요구 사항이 더 높아짐
- 노드와 카운터 사이의 포인터를 저장해야 함
- FP-트리의 크기는 항목의 순서에 따라 달라짐
일반적으로 support를 감소시켜 순서를 정하는 것이 사용되지만, 항상 가장 작은 트리로 이어지는 것은 아님(heuristic).
<2단계. FP-Tree에서 직접 frequent itemset 추출>
Step 2: Frequent Itemset Generation
FP-Growth는 FP-tree에서 frequent itemsets 추출함.
-
Bottom-up algorithm - from the leaves towards the root (이파리 노드에서 뿌리 노드로)
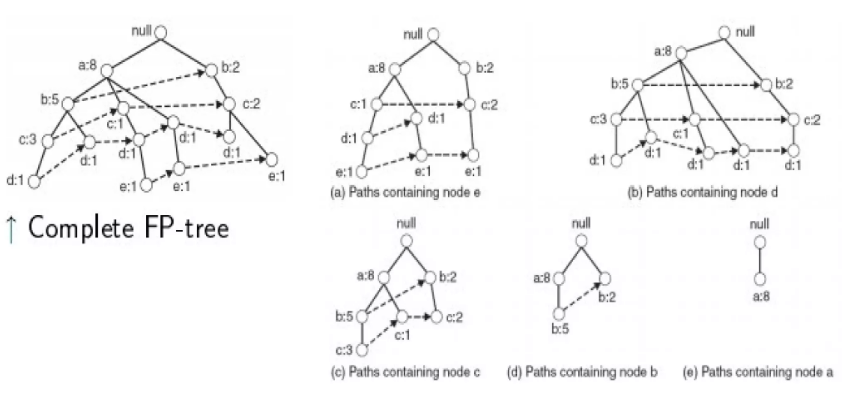
-
Divide and conquer: 먼저 e, de 등으로 끝나는 frequent itemsets 찾고, d, cd 등을 찾음
-
먼저, item(set)으로 끝나는 prefix 경로의 서브 트리를 추출함 (hint: use the linked lists)
-
각 prefix 경로의 서브 트리는 frequent itemset을 추출하기 위해 재귀적으로 처리, 솔루션들이 병합됨
e.g.) the prefix path sub-tree for e will be used to extract frequent itemsets ending in e, then de, ce, be, and ae, then in cde, bde, cde, etc.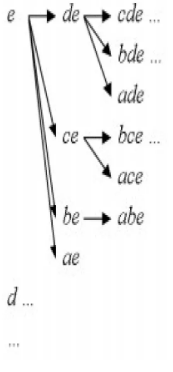
즉, frequent pattern을 recursion(재귀)을 통해 점진적으로 증가시키는 원리!
-
코드
기존에 가지고 있던 카페 매출 데이터를 불러와서 FP-growth 알고리즘을 돌려보고자 한다.
해당 데이터의 각 열은 특정 음료를 나타내며, 행은 한 시간당 주문에 대한 음료의 주문량을 나타내고 있다. FP-Growth 알고리즘을 적용하려면 주문당 구매한 음료 목록으로 변환해야하기 때문에,
이를 위해, 각 행에 대해 음료의 주문량이 0보다 큰 경우, 해당 음료의 이름을 주문량만큼 리스트에 추가하는 방식으로 데이터를 변환하는 코드로 변환을 진행했다.
[['아이스아메리카노', '아이스아메리카노', '아이스아메리카노', '아이스아이리쉬라떼', '카페라떼', '카페라떼', '카페라떼', '아이스연유라떼', '복숭아아이스티', '복숭아아이스티', '바닐라라떼', '아메리카노', '아메리카노', '아이스토피넛라떼', '아이스바닐라라떼'], …, ] 식의 데이터 형태로 바꾸고, 이를 데이터 변수 preprocessed_data에 넣어주었다.
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import fpgrowth
# 트랜잭션 인코딩
te = TransactionEncoder()
te_ary = te.fit(preprocessed_data).transform(preprocessed_data)
df = pd.DataFrame(te_ary, columns=te.columns_)
FP-growth를 사용할 수 있는 메서드는 mlxtend 라이브러리에 있기 때문에, 해당 라이브러리를 임포트하고 preprocessed_data를 트랜잭션 인코딩을 해주기 위해 TransactionEncoder()를 불러 One-Hot Encoding 처리를 했다.
# FP-Growth algorithm 적용
# support 임계치 설정, 애초에 FP-Growth는 Frequent Pattern이기 때문에 빈도수 보는거라 support 값만 처리
min_support = 0.35
frequent_itemsets = fpgrowth(df, min_support=min_support, use_colnames=True)
frequent_itemsets = frequent_itemsets.sort_values(by=['support'], ascending=False) # support값 내림차순 정렬
fpgrowth 메서드 안에 넣을 dataframe, minsupport값을 넣어주고 다음과 같은 값을 확인할 수 있었다.
Summary
-
FP-Growth의 장점
- dataset을 두 번만 훑음
- "compresses" dataset
- Candidate 생성이 없음
- Tree 만 구성하면 끝이기 때문에!
- Apriori보다 훨씬 빠르다
-
FP-Growth의 단점
- support의 계산은 무조건 FP-Tree가 만들어져야 가능함
- FP-Tree를 구축하는데 비용이 많이 듦
- 인과를 알기 어렵다는 한계가 발견
- Casual Inference라는 연구분야의 생성
- 다양한 추천시스템의 개발
