
Association Rule Mining

Amazon은 유저가 책을 구매할 때, 해당 책을 본 다른 유저들은 어떤 책을 또 함께 봤는지 추천해주는 추천 시스템을 통해 유명해졌다.
이때 사용되는 개념 중에 하나가 바로 연관 분석(Association Rule Mining)인 것이다.
Market Basket Analysis
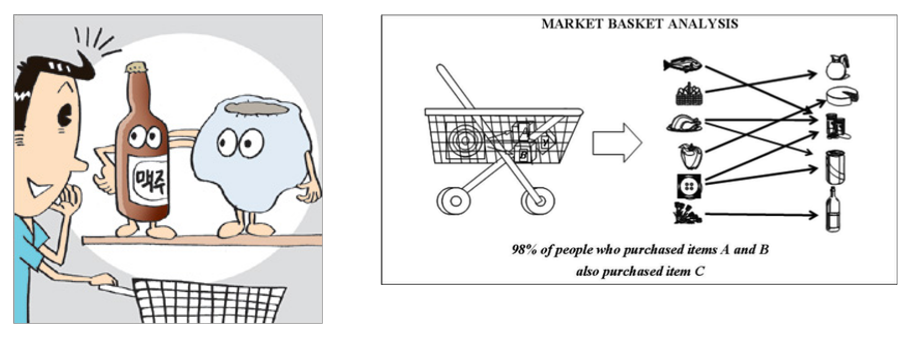
이 연관 분석은 또 다르게 Market Basket Analysis라고 일컫기도 한다. 장바구니 분석(Market Basket Analysis)이란, 데이터를 활용하여 상품과 상품 간의 연관된 규칙을 도출하는 과정을 의미한다.
이에 대한 예시로 월마트에서 진행한 장바구니 분석 사례가 있는데, 퇴근길에 아내의 부탁으로 기저귀를 사러 마트에 들렀다가 함께 맥주를 구입하는 남자가 많다는 것에 착안해 월마트가 두 제품을 함께 진열하자 매출이 늘었다는 것이다.

또한, 연관성 분석을 통해 시리얼을 사면 우유를 사는 고객이 많아 이를 이용하는 사례를 만나볼 수 있다. 시리얼 바로 옆에 우유를 진열시켜 둔다거나, 아니면 오히려 시리얼과 우유를 아예 반대로 위치시켜 시리얼을 사고 우유를 사러가는 과정에서 새로운 물건들을 보게 하는 마케팅 전략을 진행할 수 있다.
Association Rule Mining
-
대규모 데이터 세트에 숨겨진 흥미로운 관계를 발견하기 위한 방법
-
구매이력 set(일련의 트랜잭션)이 주어지면, 구매이력(트랜잭션)에서 다른 항목의 발생을 기반으로 항목의 발생을 예측하는 규칙을 찾는 것
-
예를 들어, 슈퍼마켓의 판매 데이터에서 발견된 {onion, potatoes} → {burger meat} 규칙은 고객이 양파와 감자를 함께 구매할 경우 햄버거 고기도 구매할 가능성이 높음을 나타내는 것!
-
이러한 정보는 프로모션 가격 또는 제품 배치와 같은 마케팅 활동에 대한 결정의 기초로 사용될 수 있음
-
Goal?
- “what goes with what”
- 만약 X를 구매했다면, Y도 구매를 했다!
-
Features
- 행은 transaction을 의미
- 추천시스템에서 사용됨
- “You bought X, thus you may also like Y”
- also called “affinity analysis” or “market basket analysis”
Data
- dataset for association rule mining
- 각 transaction는 record로 표시
- 두 가지 방식으로 표현됨
- item list
- item matrix
Terminology
- itemset
- 트랜잭션으로 구성된 dataset
- 각 트랜잭션에는 의 하위 집합이 포함되어 있음
- rule
- , where
- antecedent(선행) - “IF” part
- consequent(후행) - “THEN” part
- antecedent과 consequent은 일치하지 않음! (have no items in common)

- = {bread, milk, diapers, beer, eggs, coke}
- rules
- {diapers} → {beer}
- {milk, diapers} → {beer}
Measures
- rule A → B에 대한 성능 척도
Support
- 지지도: A와 B를 모두 포함하는 트랜잭션의 비율 (때로는 절대적인 숫자)
- itemset이 dataset에 등장하는 빈도를 보는 것!
- general하게 적용될 수 있는가?
- itemset이 dataset에 등장하는 빈도를 보는 것!
Confidence
- 신뢰도: A가 포함된 트랜잭션에서 항목 B가 나타나는 트랜잭션의 비율
- 의미 있는 규칙을 생성하는 데 사용됨, 규칙이 참인 것으로 밝혀진 빈도!
- 클수록 믿을만한 rule임
- A라는 상품이 주어졌을 때 B 상품이 등장할 조건부 확률
Lift
- 향상도: the ratio of the observed support to that expected if X and Y were independent
- 생성된 규칙이 얼마나 유용한지를 나타내기 위해 사용
- rule의 lift 값이 1이라면, antecedent(선행)의 발생확률과 consequent(후행)의 발생확률은 서로 독립적이라는 것을 의미
- lift 값이 1보다 크다면, 두 행이 종속되어있음을 알려줌
- lift 값이 1보다 작다면, the items are substitute to each other
How to find the rules?
-
효과적인 association rules를 생성하는 방법은?
- 이상적으로는, 모든 가능한 항목의 조합을 만들고 어떤 규칙이 효과적이고 어떤 규칙이 그렇지 않은지 확인함
- but, 항목 수가 증가함에 따라 계산 시간이 기하급수적으로 증가함
- association rules 생성 알고리즘이 필요!
brute-force approach
- 가능한 모든 연결 규칙 나열
- 각 규칙에 대한 지지도와 신뢰도를 계산
- minsup 및 minconf 임계치에 넘지 못하면 prune하는 규칙
- prune: 가지치기하듯 진행하는 heuristic
- minsup: support의 최소값 / misconf: confidence의 최소값
- 연산적으로 불가능한 알고리즘
a priori algorithm
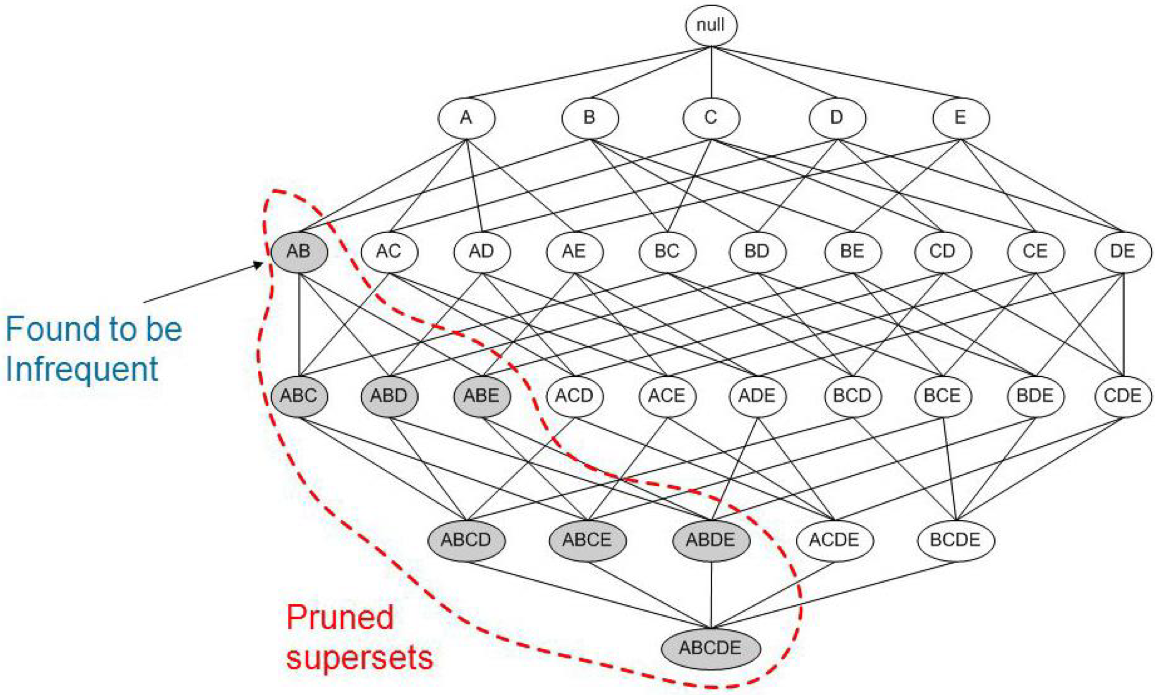
-
idataset에서 충분히 자주 표시되는 개별의 item을 찾아서 식별하고, 더 큰 itemset으로 확장하여 진행함
-
"frequent itemset"만 고려함
-
anti-monotone 속성의 support: itemset의 support는 하위 집합의 support를 초과하지 않음

-
“frequent itemset”의 생성
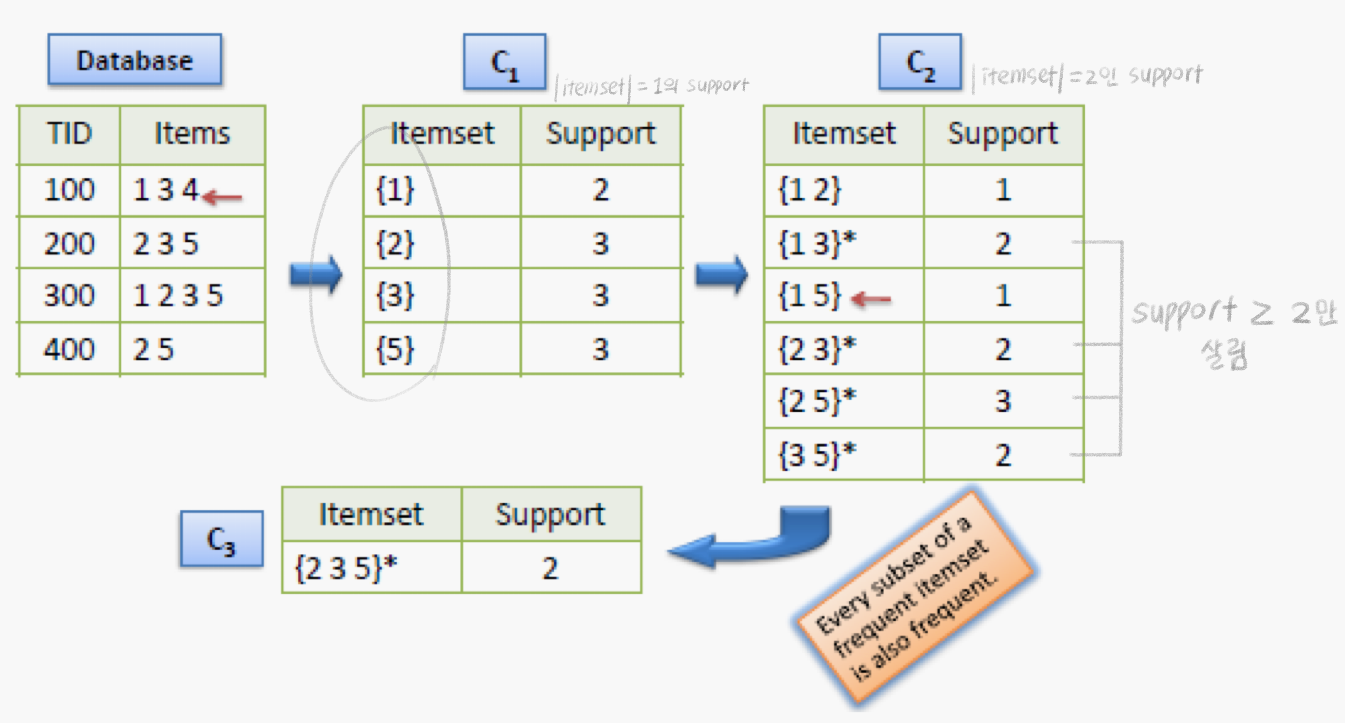
- 지원 기준을 충족하는 단일 항목 집합 목록 생성
- 단일 항목 집합을 사용하여 지원 기준을 충족하는 두 항목 집합의 목록을 생성
- 두 항목 집합의 목록을 사용하여 세 항목 집합을 생성
- k-항목 세트를 계속 진행
-
Code
-
Python Library: Apyori
- pip install apyori → from apyori import apriorifrom apyori import apriori transactions = [ ['beer', 'nuts'], ['beer', 'cheese'], ['beer', 'cheese', 'milk'], ['milk', 'cheese'], ['milk', 'cheese', 'nuts'] ] # support가 0.3 이상, confidence가 0.5 이상인 rule 찾기 results = list(apriori(transactions, min_support=0.3, min_confidence=0.5)) for res in results: print(res) # 룰을 하나씩 출력 -
결과값

-
Summary
- association rule mining produce rules on associations between items from a dataset of transactions
- 추천시스템에서 널리 쓰임
- most popular method is a priori algorithm
- 계산량을 줄이려면, “frequent” item sets만 고려해야함 (= support)
- 성능은 confidence와 lift로 평가됨
