sorting
- range(x,y)
np.arange(1,4) :1,2,3
- index로 정렬
df.sort_index(ascending = False, inplace = True)
*ascending = True : 오름차순- 컬럼으로 정렬
df.sort_values(by = "기준 컬럼명", ascending = True, inplace = True)컬럼 추가
df.insert(인덱스, 설정할 컬럼명,원하는 데이터)연결자
!=, >, <, &, |
- and
df[(idx1) & (idx2) & df.loc[:,"컬럼명"] == 1)]- or
df[(idx1) | (idx2)]Merge
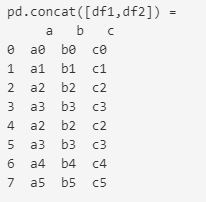
concat으로 병합하기
concatenation : 병합
- 행 방향으로 병합
df.concat([df1,df2], join = "inner", ignore_index = True)<원본>

<병합 후>
join으로 병합하기
df1.join(df2, lsffix = "x", rsuffix = "y", how = "inner")*lsffix, rsuffix : 컬럼명이 충돌하는 경우, 컬럼명을 [기존컬럼명x], [기존컬럼명y]와 같이 수정됨
import pandas as pd
# DataFrame 1
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
# DataFrame 2
df2 = pd.DataFrame({'B': [5, 6], 'C': [7, 8]})
# DataFrame을 합치기 (join) -> 열 이름 충돌 방지
result = df1.join(df2, lsuffix='_left', rsuffix='_right')
print(result)<결과>
A B_left B_right C
0 1 3 5 7
1 2 4 6 8
Merge로 병합하기
df.merge(df1, df2, how = "outer", on = "id")- how = inner(교집합) or outer(합집합),
on = "컬럼명" : 기준을 정함
데이터프레임 합치기 - 왼쪽 데이터프레임 기준
df.merge(df1, df2, how = "left", left_on = "컬럼명", right_on = "컬럼명")데이터프레임 합치기 - 오른쪽 데이터프레임 기준
df.merge(df1, df2, how = "right", left_on = "컬럼명", right_on = "컬럼명")concat, join, merge의 차이
- concat과 join은 인덱스를 가지고 조인함
- marge는 on을 사용해서 해당 컬럼을 활용해 조인함 : 자의도가 높음
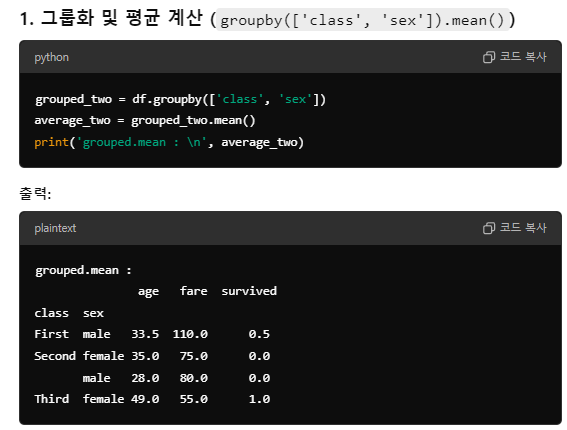
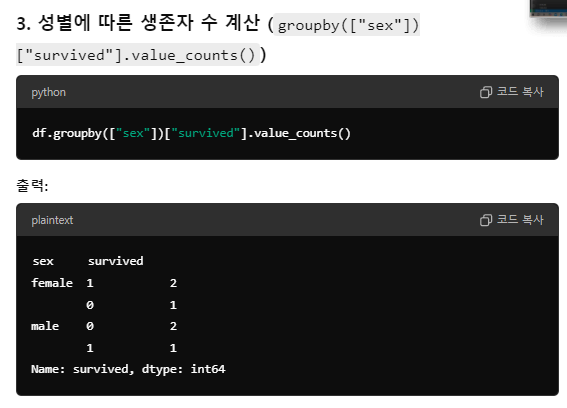
Groupby()
- 열을 기준으로 분할
grouped = df.groupby(["컬럼명"])- 연산 메소드 적용
grouped["다른 컬럼명"].mean()여러 조건으로 분할하기
- 그룹화 및 평균계산하기

서현이의 코드 생활 ദ്ദി ( ᵔ ᗜ ᵔ )