파이썬
1.isinstance(a,b) 함수

인스턴스가 어떤 클래스, 데이터 타입인지 확인하는 함수isinstance(인스턴스, 클래스/데이터타입)
2.파이썬 소수점 출력 3가지 방법(.format/ f-string /round)
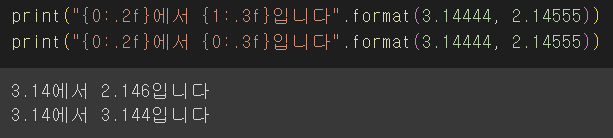
파이썬 소수점 관리 방법"{:.2f}".format(실수)
3.리스트 요소 추가 및 삭제하기

list 요소 추가, 삭제1) append리스트명.append(추가할 값)리스트 내 맨 뒤로 추가되며 출력은 되지 않음추가 시 한가지 값만 입력할 수 있음2) insert리스트명.insert(추가할 위치, 추가할 값)내가 지정한 위치에 원하는 값을 추가할 수 있음
4.파이썬 return과 print의 차이점
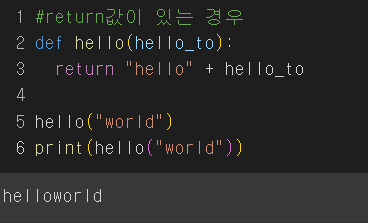
return값이 print와 헷갈리는 경우가 많아 작성해보겠습니다여러 개의 retrurn을 하나의 변수로 받는 경우 튜플로 표현됨말그대로 출력값을 확인할 수 있는 함수를 말함def hello(hello_to): print("hello" + hello_to)hello(
5.파이썬 람다함수(lambda)와 if문
람다lambda함수lambda 매개변수 : 표현식람다는 간단한 표현식으로 이 표현식을 일회성으로 간편하게 사용하기 위해 쓰입니다.람다는 표현식 하나만 사용할 수 있으며, 복잡한 로직을 구현하기 어렵습니다1) 더하기위의 plus식을 람다를 사용해 나타내게 되면이렇게 사용
6.버블정렬
n-i-1의 의미는 주로 정렬 알고리즘, 특히 버블 정렬(Bubble Sort)에서 나타납니다. 버블 정렬을 이해하기 위해 해당 코드의 문맥을 간단히 설명하겠습니다.버블 정렬은 다음과 같은 방식으로 동작합니다:리스트의 첫 번째 요소와 두 번째 요소를 비교합니다. 만약
7.파이썬 itertools 라이브러리 내장함수(accumulate, batched)

파이썬 itertools의 함수를 확인해보겠습니다파이썬 라이브러리 중 itertools 는 알고리즘 조합, 순열 개념에 자주 사용되는데요라이브러리 내 함수에 대해 알아봅시당1)accumulate함수accumulate(리스트)accumulate : 축적하다축적한다의 뜻을
8.파이썬 assert함수
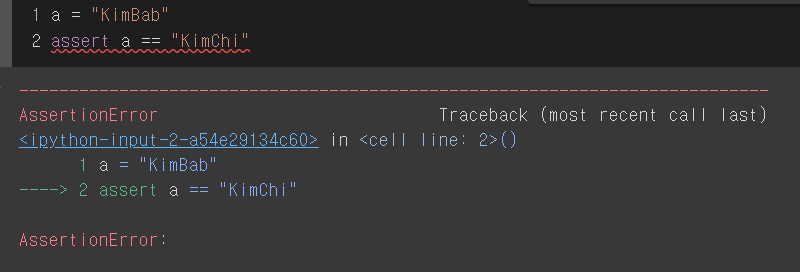
assert 조건, 오류메세지(오류메세지 생략가능)assert 뒤로 오는 조건들이 모두 True인지 확인하는 함수로, True가 아닌 경우, AssertionError를 발생시킴.디버깅할 때 주로 사용함!예시True인 경우위에서 True가 출력되는 이유는 만약 asse
9.List와 문자열(split, join, index)
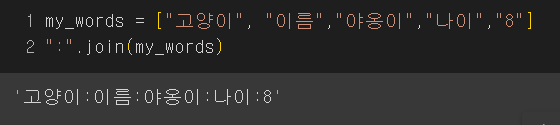
프로그래머스로 List와 문자열을 공부해봅시다리스트와 문자열은 비슷하며, 서로 변환이 가능하다문자열 > 리스트로 변환 : list = str.spilt()리스트 > 문자열로 변환 : " ".join(list)split은 문자열을 괄호 내 문자로 쪼개어, 리스트화 시켜줍
10.파이썬 슬라이싱(del함수, 인덱스로 리스트 수정하기)
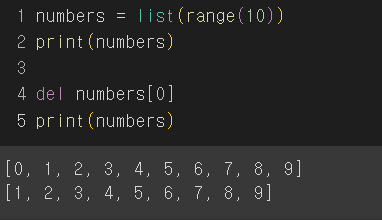
슬라이싱 : 리스트 내에서 여러 개의 인덱스를 호출하는 장치lst1 = 44,6954,79,383lst2 = lst1: \`\`\`위처럼 손쉽게 리스트를 복사할 수도 있습니다del 리스트이름\[인덱스]del 함수는 취소가 불가능하니 주의해서 사용해야 합니다리스트명\[시
11.인스턴스

다음 포스트인 class와 인스턴스 글과 함께 확인해보세요type(5)class'int'isintance(5,float)Falsecharacters = list"Hello"characters'H','e','l','l','o'isintance(chracters, list
12.class와 모델링
클래스에 함수를 넣을 수 있음: class로 현실의 개념을 표현
13.상속 클래스
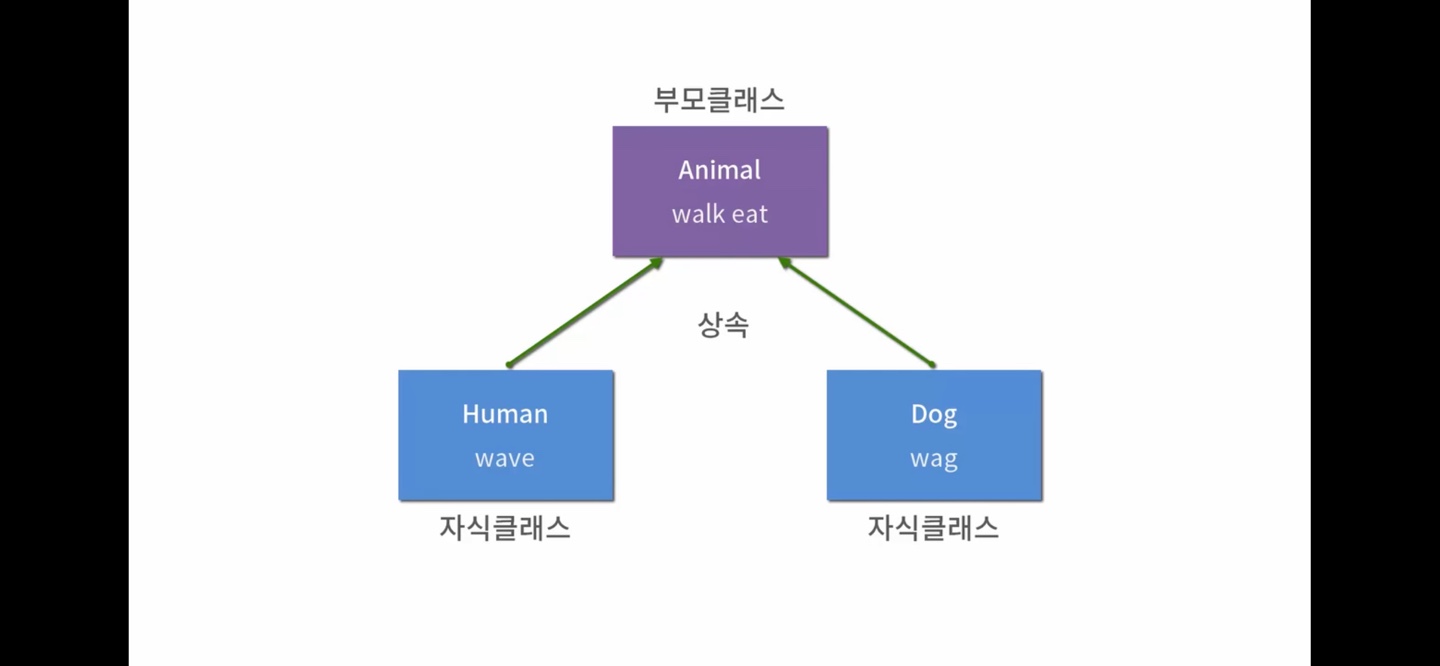
자식클래스 내에서 부모클래스의 함수들을 함께 사용할 수 있음
14.yield함수 - generator함수
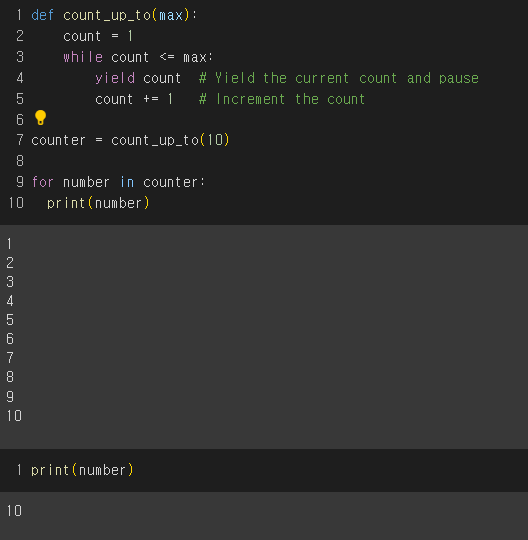
yield가 def함수 내에 위치해 있다면 파이썬은 이 함수로 generator를 만들려했다고 생각하고 취급그래서 yf = range_y(9)는 generator(9)가 됩니다yf를 실행시키려면 for문이 필요합니다이와 같은 def + yield의 사용 예시무한히 생성
15.03_Pandas plot종류(regplot, implot, barplot), describe()
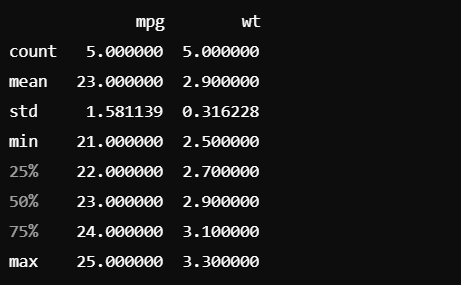
mpg이라는 데이터프레인을 cyl열을 기준으로 그룹화, "mpg"는 mpg에 해당되는 컬럼을 선택하여.agg() 괄호 내 함수를 적용함을 의미각 실린더 수 cyl에 따라 연비의 평균과 표준편차에 대한 데이터프라임을 만듦예제 2문제)cut = ideal, price vs
16.Mechine Learning_이론
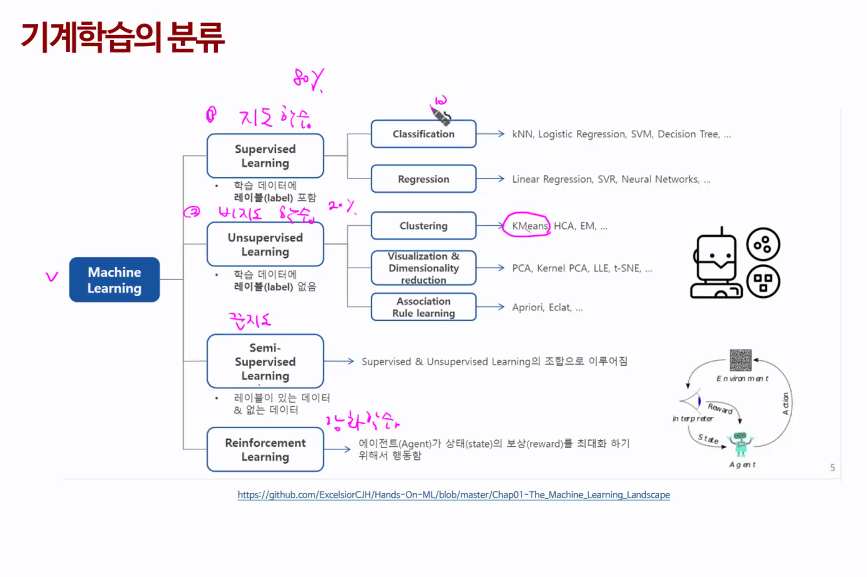
input - x1,x2.. (features)output - y (Target) : 범주형파이썬 (scikit-learn)⭐70% (Training set 70%, Validation set 30%), Test set 30%그러나 실제의 데이터는 충분하지 않음초매개변
17.01_pandas(파일읽기, df생성 및 수정, 삭제하기)
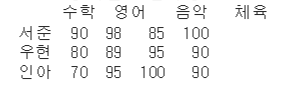
pandas 사용하기파일의 형태를 확인해 각각에 맞는 읽기방법을 사용하면 됩니다.csv : pd.read_csv("파일경로csv")xlsx : sns.read_xlsx("파일경로.xlsx")sns 내장 데이터셋 : sns.load_dataset("데이터명")sns 내장
18.02_pandas(sorting, join, groupby)

range(x,y)np.arange(1,4) :1,2,3index로 정렬컬럼으로 정렬!=, >, <, &, |andorconcatenation : 병합행 방향으로 병합<원본><병합 후>\*lsffix, rsuffix : 컬럼명이 충돌하는 경우, 컬럼명을
19.Decision Tree
각각을 node, 위에서 밑 방향으로 Root node, internal node, leaf node(terminal node)로 부름 여기서 Disease가 타겟, Hypertension, chestPain, Cholesterol이 피쳐가 됨 위의 3개로 나누