pandas 사용하기
파일 읽기
파일의 형태를 확인해 각각에 맞는 읽기방법을 사용하면 됩니다.
- csv : pd.read_csv("파일경로csv")
- xlsx : sns.read_xlsx("파일경로.xlsx")
- sns 내장 데이터셋 : sns.load_dataset("데이터명")
- sns 내장 데이터셋 확인방법 : sns.get_dataset_names()
DataFrame 속성 메서드
-
데이터프레임의 상위 5번째 행까지 확인
데이터프레임 명. head() -
데이터프레임의 하위 5번째 행까지 확인
데이터프레임 명. tail() -
데이터프레임 간략 정보 확인
데이터프레임 명. info()
자료에 대한 정보 확인
자료 인덱스, 크기, 데이터 타입, 변수명
- 인덱스
데이터프레임 명.index - 크기
데이터프레임 명.shape - 데이터 타입
데이터프레임 명.dtypes - 변수명(컬럼명)
데이터프레임 명.columns - x차 데이터
데이터프레임 명.ndim
데이터 한눈에 보는 방법
데이터프레임 명.describe()
*주의 : 여기서 object는 str타입을 말함
데이터프레임 생성
기본적으로 열의 갯수가 같아야하며, key는 문자열이 일반적임
- 딕셔너리로 데이터프레임 생성
data = {
"name" : ["홍길동","임꺽정","이순신"],
"algol" : ["A","A+","B"],
"basic" : ["C","B,"B+"],
"python" : ["B+","C","C+"]}
my_df = pandas.aDataFrame(data) #DB의 형태로 변환- 리스트로 데이터프레임 생성(참고)
리스트는 리스트 내 데이터가 row방향으로 들어감
lst = [[15, "남자", "덕영중"],
[17,"여자","수리중"]]
lst_df = pandas.DataFrame(lst, columns = ["나이","성별","학교"])연속형 자료
- 평균
데이터명["컬럼명"].mean() - 중간값
데이터명["컬럼명"].median()
-분산
데이터명["컬럼명"].var() - 표준편차
데이터명["컬럼명"].std() - 평균의 분산
데이터명["컬럼명"].sem() - 최댓값
데이터명["컬럼명"].max() - 최솟값
데이터명["컬럼명"].min()
연장선
-
여러 개의 컬럼의 평균 구하기
데이터명[["컬럼명1","컬럼명2"]].mean() -
반올림
데이터명.round() -
분위수
데이터명[["컬럼명1","컬럼명2"]].quantile(0.25)
데이터명[["컬럼명1","컬럼명2"]].quantile(0.75) -
표준 오차
: 표본 평균이 모집단 평균을 얼마나 잘 추정하는지 보여주는 척도, 표본의 표준편차를 표본 크기의 제곱근으로 나눈 값
데이터명[["컬럼명1","컬럼명2"]].sem()
이산형 자료
- 해당 컬럼을 각 그룹별 갯수를 나타냄
데이터명["컬럼명"].value_counts()
데이터의 상관성
correlation
데이터명[["컬럼명","컬럼명"]].corr()
그래프 그리기
Matplotlib as plt
- 간단한 산점도 그리기
plt.scatter(x = "컬럼명", y = "컬럼명", data = 사용할 데이터프레임명)
- 더 정교한 산점도를 그리려면 sns.scatterplot()을 이용하세요
scatter(s : 산점의 사이즈)
-
그래프 제목
plt.title("제목명") -
x축 이름
plt.xlabel("x축명") -
y축 이름
-
plt.ylabel("y축명")
-
그래프 보기
plt.show()
데이터프레임 수정 및 삭제하기
df의 컬럼명, 인덱스 수정
- 컬럼명 수정
df.rename(columns = {"기존 컬럼명1" : "수정된 컬럼명1,
"기존 컬럼명2" : "수정된 컬럼명2,
"기존 컬럼명3" : "수정된 컬럼명3,
"기존 컬럼명4" : "수정된 컬럼명4}, inplace = True)
*inplace : 기존 df를 수정하겠다는 의미, False라면 기본의 값을 반환함
- 인덱스 수정
df.rename(index = {0:1, 1:2, 2:3}, inplace = True)
삭제하기
- 삭제하기
df.drop(labels = ["컬럼명"], axis = 1, inplace = False)
axis가 1이라면 열, 0이라면 행을 삭제
labels = [0] 과 같이 인덱스로도 불러올 수 있음
결측값 - NaN
파이썬에서는 None, Pandas에서는 NaN으로 표기
결측값 할당
-
인덱스가 0인 행에 "성별"이라는 열의 값을 NaN으로 설정
df.loc[0, "성별"] = np.nan -
인덱스가 1인 행에 "수학", "영어"라는 열의 값을 None으로 설정
df.loc[1, "수학","영어"] = None
결측값 삭제
-
결측값이 있는 행을 삭제
df.dropna(axis = 0) -
결측값이 있는 열을 삭제
df.dropna(axis = 1)
특정 결측값 삭제
- 특정 열(수학)에서 결측값이 있는 행만 삭제, 나머지 열은 무시
df.dropna(axis = 0, subset = ["수학"])
NaN 값 대체
- 결측값을 특정값으로 대체합니다
df.fillna("특정값", inplace = False)
인덱싱
선택하기
-
컬럼으로 열 선택하기
df["컬럼명"]
df["컬럼명","컬럼명2"] -
인덱스로 행 선택하기
df[0:2]
loc
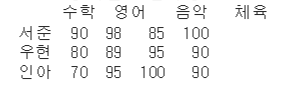
- loc 인덱스를 사용해 행 선택하기
df.loc["인덱스명"]
df.loc[[1,2]]
위의 데이터로 보여주자면
df.loc["서준"]
df.loc[["서준","인아"]]
- loc 인덱스로 행과 열 모두 선택하기
df.loc[:, :"컬럼명"]

행과 열 추가하기
-
새로운 열 추가 : 맨끝에 추가됨
df 내 없는 열을 지정해줌
df["추가할 컬럼명"] = [추가할 값,...] -
새로운 열 중간에 추가
df.insert(원하는 인덱스 위치, "추가할 컬럼명",[추가할 값,..]) -
새로운 행 추가
df.loc[원하는 인덱스] = [추가할 값,...]
데이터 element 값 변경하기
- 인덱스를 데이터셋 내의 값으로 변경하기
df.set_index("인덱스로 사용할 컬럼명")ㄴ
df = pd.DataFrame({
'Date': pd.date_range(start='2023-01-01', periods=5),
'Product': ['A', 'B', 'C', 'A', 'B'],
'Price': [100, 200, 150, 120, 220],
'Quantity': [10, 15, 8, 12, 18]
})
df_single_index = df.set_index('Date', inplace = True)
print("1. 'Date' 열을 인덱스로 설정:")
print(df_single_index)
print("\n")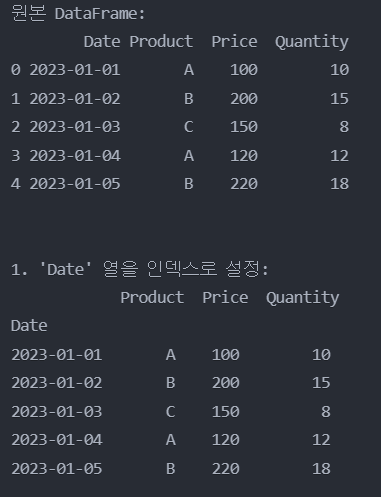
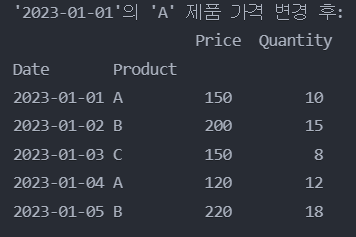
- 단일 값 변경:
'2023-01-01'의 'A' 제품의 'Price'를 150으로 변경
df.loc[('2023-01-01', 'A'), 'Price'] = 150
print("'2023-01-01'의 'A' 제품 가격 변경 후:")
print(df)
sprint('\n')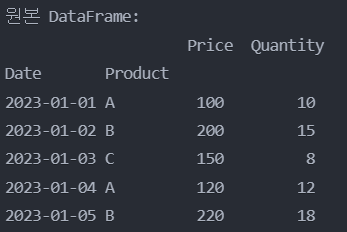
- 여러 값 변경
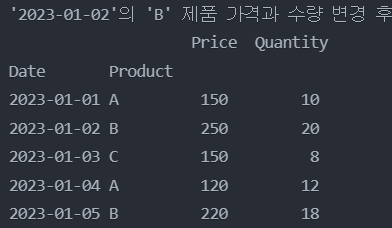
'2023-01-02'의 'B' 제품의 'Price'와 'Quantity'를 변경
df.loc[('2023-01-02', 'B'), ['Price', 'Quantity']] = 250, 20
print("'2023-01-02'의 'B' 제품 가격과 수량 변경 후:")
print(df)
print('\n')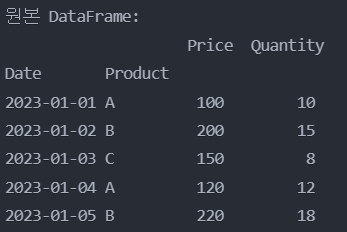
- 여러 값을 리스트로 한 번에 변경
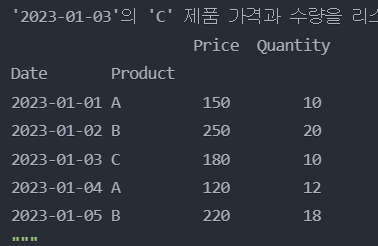
'2023-01-03'의 'C' 제품의 'Price'와 'Quantity'를 변경
df.loc[('2023-01-03', 'C'), ['Price', 'Quantity']] = [180, 10]
print("'2023-01-03'의 'C' 제품 가격과 수량을 리스트로 변경 후:")
print(df)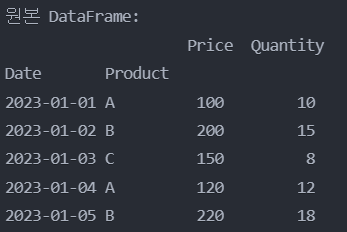
reindexing
set_index 진행 후 다시 원래의 인덱스 값으로 돌아가는 방법
df.reset_index()
