Prototype Rectification for Few-Shot Learning 리뷰

이 글을 보시기 읽기 전에, Few-shot learning에 대한 사전 이해가 있으면서, 그 중에서도 "Prototypical Networks for Few-Shot Learning" 논문을 읽고 오신다면 더 이해가 수월 할 것 같습니다.
안녕하세요, 오늘은 "Prototype Rectification for Few-Shot Learning"(2020 ECCV oral)논문을 소개드리겠습니다. 제목에서 유추가능하듯 Prototype을 조정하여 Few-Shot learning을 진행한 논문입니다. 기존 ProtoNet에서 제시한 Prototype은 Support sample들을 단순히 산술평균을 하여 만들어집니다. 이 때문에 Outlier에 민감하다는 단점이 있었는데요, 이 한계점을 타개하기 위하여 이 논문에서는 Prototype의 위치를 보다 좋은 위치로 수정하는 방법을 제안한 논문입니다.
Definition
이 논문에서는 Prototype의 성능을 제한하는 요인 2가지를 발견하고, 이를 intra-class bias, cross-class bias로 정의하였습니다.
intra-class bias : difference between the expected prototype and the actually computed prototype

cross-class bias : distance between the mean vectors of support and query datasets
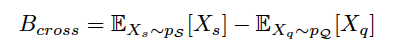
intra-class bias는 support set에 의해 계산된 Prototype의 위치(computed prototype)와 실제 dataset 내 해당 class의 모든 데이터로 계산한 Prototype(expected prototype)의 위치 차이를 말합니다. 쉽게 말해서, 데이터셋 내에 존재하는 호랑이 사진들을 모두 가져와서 prototype을 구해봅시다. 그 prototype은 이상적인 위치를 가진 expected prototype입니다. 그러나 샘플링된 호랑이 사진들로만 prototype을 구해봅시다. 이는 support set의 호랑이 사진들로 구한 computed prototype입니다. 만약 해당 class의 data 분포가 고르다면, computed prototype과 expected prototype의 차이(bias)는 적겠죠. 그러나 outlier가 많다면 그 차이(bias)는 커질 것입니다. 즉, 특정 class마다 prototype이 가지는 bias를 intra-class bias라고 말합니다.
cross-class bias는 support set의 mean vector와 query set의 mean vector의 차이를 말합니다. support set과 query set은 하나의 episode를 이루며 이는 동일한 domain distribution을 가지고 있습니다. 쉽게 말해서, 한 episode 내에서는 class의 구성이 동일하다는 것과 똑같은 말 입니다. 해당 episode가 호랑이, 사자로 구성된 2-way k-shot 구성의 task라면, support sample들은 호랑이, 사자 domain에서 sampling된 데이터일 것이며, query sample들도 마찬가지로 호랑이, 사자 domain에서 sampling된 데이터일 것입니다. 즉, support와 query는 동일한 domain에서 추출된 데이터들이기 때문에 중심 지점이 (이상적으로)동일해야한다는 점입니다. 그러나 실제 데이터들은 그렇지 않기 때문에, support set과 query set의 mean vector 사이의 거리는 distribution bias를 나타냅니다. 이 차이(bias)를 cross-class bias라고 말합니다.
Method
논문에서는 Prototype의 성능을 제한하는 각 요인들의 영향을 줄이기 위한 방법들을 제안하였습니다.
intra-class bias 줄이는 법 : Pseudo Labeling
intra-class bias를 줄이기 위해 pseudo labeling 기법을 사용했습니다.
Query 샘플에 대해서 임의로 라벨을 부여(pseudo label)하여 prototype에 계산되는 support의 양을 늘려 이상적인 prototype(expected prototype) 위치에 가까워지도록 만들어줍니다. 다시 언급하자면, Expected Prototype은 해당 클래스의 모든 샘플의 평균을 말합니다. 따라서 Computed Prototype은 Prototype을 계산하기 위해 사용되는 샘플의 수가 많아질 수록 Expected prototype에 가까워진다고 할 수 있습니다. 즉, pseudo labeling을 통해 계산에 사용되는 샘플의 수를 늘리는 방식을 채택하여 expected prototype과 computed prototype의 차를 줄이고자 합니다.
자세한 과정은 다음과 같습니다.
1️⃣ 특정 클래스 당 prototype vector와 코사인 유사도가 높은 query sample z개(Top z)를 골라서 label을 부여(pseudo-label)하여 support set에 추가합니다.
2️⃣ 로 prototype을 재생성 합니다. 이때, 잘못 예측된 pseudo labeling의 영향을 줄이기 위해 산술평균(기존 평균)이 아닌 기존 prototype과 feautre가 얼마나 유사한지 가중치를 계산하여 가중평균을 이용하여 prototype을 만듭니다.
해당 과정은 결국 computed prototype을 계산하는데 사용되는 샘플의 수를 많게 하여 computed prototype을 expected prototype의 방향으로 이동하게끔 하여 intra-class bias를 줄이고자 하는 것이 목적입니다.
(참고로 이 과정은 "Meta-Learning for Semi-Supervised Few-Shot Classification" 논문에서 Unlabelled data를 이용하여 Prototype위치를 조정하는 방법과 거의 유사하다고 생각됩니다. 이 논문도 Prototypical Network 저자들이 후속으로 낸 논문이니 추가로 궁금하신 분들은 이 논문도 읽어보시길 추천드립니다.)
cross-class bias 줄이는 법 : shifting term
support set의 mean vector와 query set의 mean vector의 차이를 라 정의하고 이 크기 만큼 query sample들에게 shifting을 수행하여 distribution gap을 없앱니다.
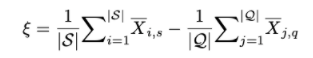
즉, 이 과정은 distribution gap을 줄이기 위해 query vector들을 support 방향으로 이동하게끔 조정하여 cross-class bias를 줄이고자 하는 것이 목적입니다.
전체 framework
bias를 줄이기 위해 앞서 제시한 pseudo labeling과 shifting term이 few-shot task 내에서 어디서, 어떻게 쓰이는지 전체 framework를 살펴봅시다.
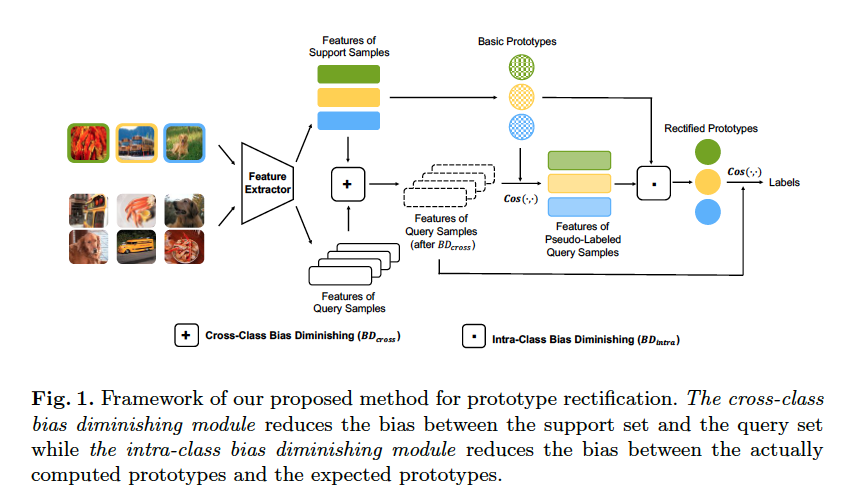
해당 그림은 하나의 few-shot task 내에서 일어나는 prediction 과정을 보여줍니다. 먼저, 동일한 class 구성을 가진 support와 query sample들이 sampling됩니다. 이 이미지들이 feature extractor를 통해 feature vector로 추출됩니다. 추출된 feature vector중 support vector들은 prototype을 생성합니다. 또한, query vector들에게는 shifting term을 구하여 각 vector에 빼줍니다. 이는 support 쪽으로 query를 이동시켜 distribution gap을 줄여 cross-class bias영향을 줄이기 위한 과정입니다. 그리고 query에 대해 computed prototype과 코사인 유사도를 통해 prediction score를 예측해줍니다. 각 클래스마다 높은 top z개의 score를 가진 query 샘플들에 대해 pseudo label을 생성해줍니다. 이를 서포트셋에 추가하여 수도쿼리가 추가된 새로운 support set으로 prototype을 재생성 해줍니다. 이 rectified prototype으로 최종 query에 대해 prediction 해줍니다.
위 과정을 다시 간단하게 정리하자면 아래처럼 요약할 수 있습니다.
- feature vector 추출
- Support : Prototype 생성
- Query : support 쪽으로 만큼 query 이동 (cross-class bias 줄임)
- query에 대해 기존 prototype들과 cos유사도로 prediction score 예측
- 각 class 마다 높은 score를 가진 query z개씩 pseudo label 생성하여 Support set에 추가 (intra-class bias 줄임)
- Support'() : 새로운 Prototype 생성 (가중평균 이용)
- Query Prediction
Result

각각의 방법들이 bias의 영향을 줄여주었음을 T-sne를 통해 분석결과를 보여줍니다.
(a)는 intra class bias에 대한 시각화 결과입니다. rectified prototype이 expected prototype방향으로 이동하였음을 볼 수 있습니다.
(b)는 cross class bias에 대한 시각화 결과입니다. query sample들이 support set 중심 방향으로 이동하였음을 볼 수 있습니다.

tabel 1은 miniImageNet에 대한 classification 결과입니다. 5-shot의 경우, 기존 ProtoNet(63.11%)에 비해, rectified Prototype은 18%가량 향상된 81.89%의 결과를 보여주네요. table 2는 miniImageNet보다 조금 더 크고, 다양한 데이터 셋인 tieried ImageNet에 대한 결과입니다. 마찬가지로 좋은 성능을 보여줍니다.
각 데이터셋에 대한 설명은 아래 표로 간단하게 소개드리겠습니다.

이 논문의 컨셉은 query 데이터가 inference과정에도 참여하기 때문에(pseudo labeling 과정에 참여) transductive 셋팅을 가집니다. 이와 비교를 하기 위해서도 transductive setting을 가진 이전 논문들 TPN, EGNN과 비교 결과를 보여주는데요, 앞선 논문들에 비해서도 훨씬 간단한 알고리즘이면서 좋은 성능을 보이는 것이 신기합니다.
Semi-Supervised 컨셉 중 이 논문과 유사한 컨셉 논문인 ML[26]논문에 대해서도 차이가 많이 나는 것이 조금 의아했는데요, ML 논문에서도 unlabelled data에 대해 수도 라벨링 방법을 사용하여 prototype 재정의하는데 가중평균을 사용하는 방식도 동일하다는 점이 매우 유사하다고 느꼈으나 결과에서 큰 차이를 보이는 것이 의아하다고 느껴졌던 부분입니다. 아마도 두가지 이유에서 큰 차이가 난다고 생각합니다. 1. 수도라벨링을 하는 대상이 서포트 셋이냐 쿼리셋이냐의 차이 - 이는 transductive 세팅으로도 연관됨. 2. shifting term - distribution gap 감소. 아마 이 두가지의 요인이 큰 차이로 생각되는데, 둘 중 어느 요소가 더 크게 차지 하는지도 궁금했습니다. 🤔
결론
오늘 소개 드린 "Prototype Rectification for Few-Shot Learning" 논문은 Prototype의 성능을 제한하는 요인(intra-class bias, cross-class bias)들을 제시하였습니다. 그리고 제한 요인들의 영향을 줄이기 위한 방법들을 제안하였습니다. 본 글에서는 설명하지 않았지만, 각 요인들과 방법에 대한 이론적 분석까지 수행하였습니다. 단순히 prototype의 위치만 조정하여 똑같은 실험을 수행하였는데, 결과가 이렇게나 좋아질 수 있다는게 신기했습니다. pseudo labeling 자체는 "Meta-Learning for Semi-Supervised Few-Shot Classification" 논문과 유사하다고 생각되어 Novel하지는 않은 것 같고, query shifting 부분이 조금 더 novel 하다고 느꼈습니다. 심플한 아이디어와 방법론임에도 직관적인 전개 방식과 원인과 결과에 대한 명확한 분석, 전달하고자 하는 메시지의 명확함 덕분에 논문도 쉽게 읽히고 좋은 학회에 accept이 되지 않았나 싶습니다. 그러나 아쉬웠던 점은, 코드도 살펴보고 싶었으나, 따로 공개된 코드가 없었습니다..🥲
긴 글 읽어주셔서 감사합니다 :)
