
What is Data Structure?
:: Data Structure(자료 구조)란?
-
데이터에 편리하게 접근하고 조작하기 위해, 데이터를 저장하거나 그룹핑하는 방법
-
자료 구조의 종류에는 여러가지가 있다! 각각의 자료구조가 갖는 장점과 한계를 잘 이해하고 상황에 맞게 올바른 자료 구조를 선택하고 사용해야 함
-
자료구조는 언어별로(ex. JavaScript, Python...) 지원하는 양상이 다르다.
각 언어가 가진 자료구조의 종류와 그것에 대한 사용 방법을 익히는 것이 중요하지만, 무엇보다 각 자료구조의 본질과 컨셉을 이해하고 상황에 맞는 적절한 자료 구조를 선택하는 것이 중요하다.
 데이터에 맞는 적절한 자료 구조를 사용하는 것은 전체 개발 시스템에 굉장히 큰 영향을 끼치므로, 자료 구조에 대해 빠싹하게 정리해보기로 한다!!!!
데이터에 맞는 적절한 자료 구조를 사용하는 것은 전체 개발 시스템에 굉장히 큰 영향을 끼치므로, 자료 구조에 대해 빠싹하게 정리해보기로 한다!!!!
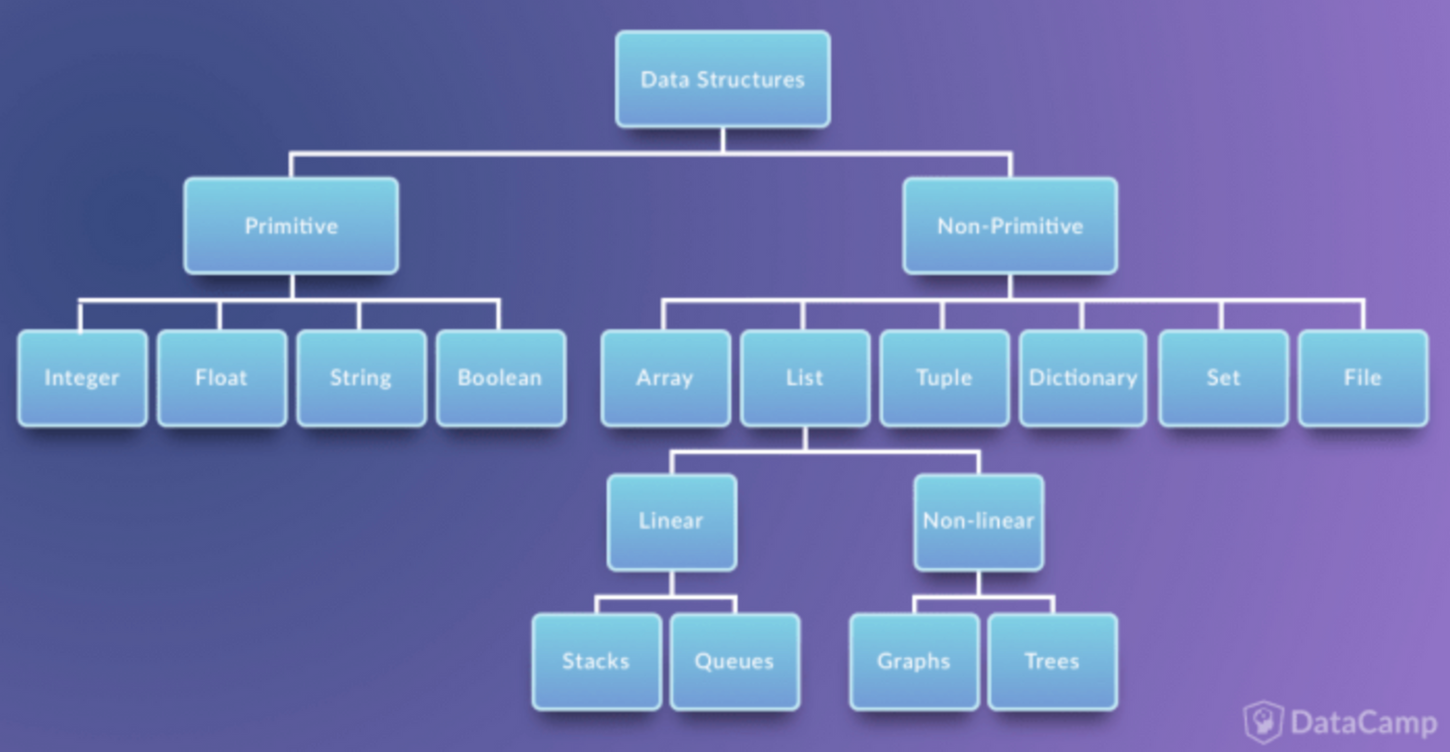
:: Data Structure의 분류
-
Primitive Data Structure(단순 구조)
: 프로그래밍에서 사용되는 기본 데이터 타입 -
None-Primitive Data Structure(비단순 구조)
: 단순한 데이터를 저장하는 구조가 아니라 여러 데이터를 목적에 맞게 효과적으로 저장하는 자료 구조
- Linear Data Structure(선형 구조)
: 저장되는 자료의 전후 관계가 1:1 (ex. List, Stacks, Queues)
- Non-Linear Data Structure(비선형 구조)
: 데이터 항목 사이의 관계가 1:n 또는 n:m (ex. Graphs, Trees )
자주 사용되는 Data Structure
- Array (List)
- Tuple (JavaScript에는 없당...)
- Set
- Dictionary
- Stack & Queue
- Tree
오늘은 Array랑 Tuple에 대해 정리!!! 나머지는 다음 이시간에.....😁
Array (List)
:: 정의 - Array(List)
- JavaScript 에서는
Array(배열)!! ( Python에서는List) Array는 가장 기초적이고 단순하면서도 가장 자주 사용 되는 자료 구조이다.
참고로 Python에는
Array도 있고,List도 있다고 한다!
일반적으로Array보다 일반List가 훨씬 더 많이 사용 된다.
사실 Python 에서는List가Array라고 생각하고 써도 무방하지만, 엄밀히 말하자면 다르긴 함...
기능적으로는 거의 동일하지만 메모리 효율면에서는Array가 유리하다.
다만 사용하기에는List가 훨씬 편하다고.... 그래서 대부분List를 사용하는 거구만?
(Python 에서 Array 를 사용하려면 import Array 모듈을 import 해서 사용해야 한다고 함...뭔말인지 모르겠지만 대충 복잡해보인다.)
:: Array 특징
-
Array의 가장 큰 특징은 순차적(ordered)으로 데이터를 저장한다는 점!!!!
( Array는 주로 데이터들을 순차적으로 저장할때 사용하지만, 순서가 상관 없는, 서로 연결된 데이터들을 저장할때도 일반적으로 Array를 사용) -
자료구조에 저장하는 데이터는 요소(element)라고 한다.
그 외에도...
- 삽입(insertion) 순서대로 저장된다.
(즉, 새로 삽입되는 요소는 Array의 제일 마지막에 위치하게 된다.) - 이미 생성된 Array도 수정 가능!!!
- 동일한 값도 여러번 삽입 가능하다.
- Multi-dimentional Array(다중차원 배열)이 이루어질 수 있다.
💁🏻♀️ Multi-dimentional Array(다중차원 배열)
Array의 요소가 array가 될 경우, 이를 다중차원 array라고 한다.
2차원(2D) array : 지뢰찾기를 떠올리면 바로 이해 가능!!
이렇게, 행과 열 개수만큼의 공간이 만들어진다.
예를 들어, 2x2 배열이면, 모두 4개의 배열 변수가 만들어진다.
물론 array이므로, index는 당연히 0부터 시작한다 헷갈리지 말것!!
그리고, 각 배열 변수의 이름은 두 개의 index 조합a[i][j]형식으로 나타낸다.
요 그림이 바로 2차원 배열!!
3차원(3D) array : 3차원 배열은 큐브를 떠올리면 된다!
큐브처럼 x, y, z축으로 이루어진 공간을 생각하면 된다.
예를 들어, 2x2x2 배열이면 모두 8개의 배열 변수가 만들어진다.
각 배열 변수의 이름은 세 개의 index 조합a[i][j][k]형식으로 나타낸다.
:: Array 내부 구조
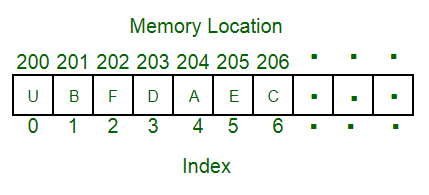
- Array는 데이터를 순차적으로 저장하고, index도 지정된다.
⇒ 그래서 데이터 위치만 알면 index로 바로 가져올 수 있기 때문에 조회 속도가 빠르다! - Index는 당연히 0부터 시작한다. 그런데 마이너스 index도 있다는 사실!
마이너스 index는 맨 마지막 요소 부터 시작한다. (예를 들어, -1 은 맨 마지막 요소)
🤔 Array는 왜 데이터를 순차적으로 저장할 수 밖에 없을까?
1. 그건 바로 실제 메모리 상에서 데이터가 순차적으로 저장되기 때문!
2. 데이터에 순서가 있기 때문!
1)index가 존재하며
2)indexing= index를 사용해 특정 요소를 array(list)로 부터 읽어 들이는 것이 가능하고,
3)Slicing= 요소의 특정 부분, 즉 n번째 index부터 m번째 index까지 따로 분리해 조작하는 것이 가능
:: Array의 단점
Array는 순서뿐만 아니라, 메모리의 실제 주소도 순차적으로 되어있다.
순차적으로 저장되서 좋은 점도 있지만, 반대로 단점도 존재한다.
Removing or Adding Elements
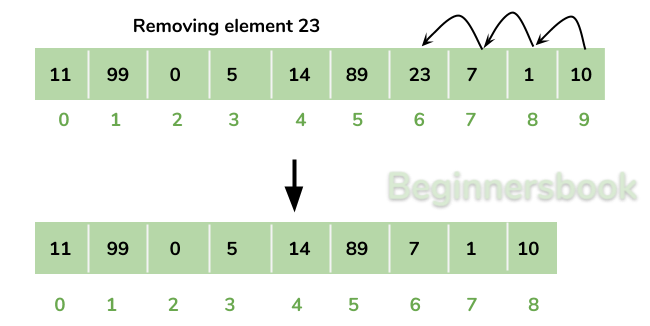
순차적으로 담겨있는 데이터 중 특정 위치에 있는 중간의 요소가 삭제 되는 경우가 있을 수 있는데....
메모리는 항상 순차적으로 이어져있어야 하기 때문에, 삭제된 요소로 부터 뒤에 있는 모든 요소들을 앞으로 한칸씩 이동시켜주어야 한다.
( 즉, 요소를 삭제하는 과정이 코드 상에서는 간단하지만 실제 메모리 상에서 이루어지는 작업(operation)은 훨씬 크기에, 다른 자료 구조에 비해 요소의 삭제가 느리다.... )
중간에 요소가 추가 되는 경우도 마찬가지!!!
특정 위치에 새롭게 요소가 추가되는 경우에는 그 뒤의 요소들을 하나씩 뒤로 밀어야 하므로 마찬가지로 메모리에서는 복잡한 작업이 이루어진다.
그렇기 때문에 Array 는 정보가 자주 삭제 되거나 추가되는 데이터를 담기에는 적절치 않다!!
Array Resizing
Resizing = 사이즈를 다시 조정
배열을 처음 생성할때, pre-allocation가 이루어진다.
pre-allocation란, 메모리가 순차적으로 채워지기 때문에, 배열이 처음 생성될 때 어느 정도 메모리를 미리 할당합니다.
메모리를 미리 할당하기 때문에, 새로 추가되는 요소들도 순차적으로 메모리에 저장될 수 있지만, 요소들이 처음 할당한 메모리 이상으로 많아진다면 resizing이 필요하다.
즉, Array Resizing이란, array에 메모리를 더 할당하는 것을 말한다.
( 추가적으로 할당된 메모리 또한 순차적이어야 함!!! )
ex) 100개의 메모리 공간이 다 차서 100개를 추가해야 되는 경우
200개 크기의 메모리를 새로 생성 후 → 기존 100개를 복사하고 → 그 다음 101번 부터 데이터를 순차적으로 추가해야 함.....
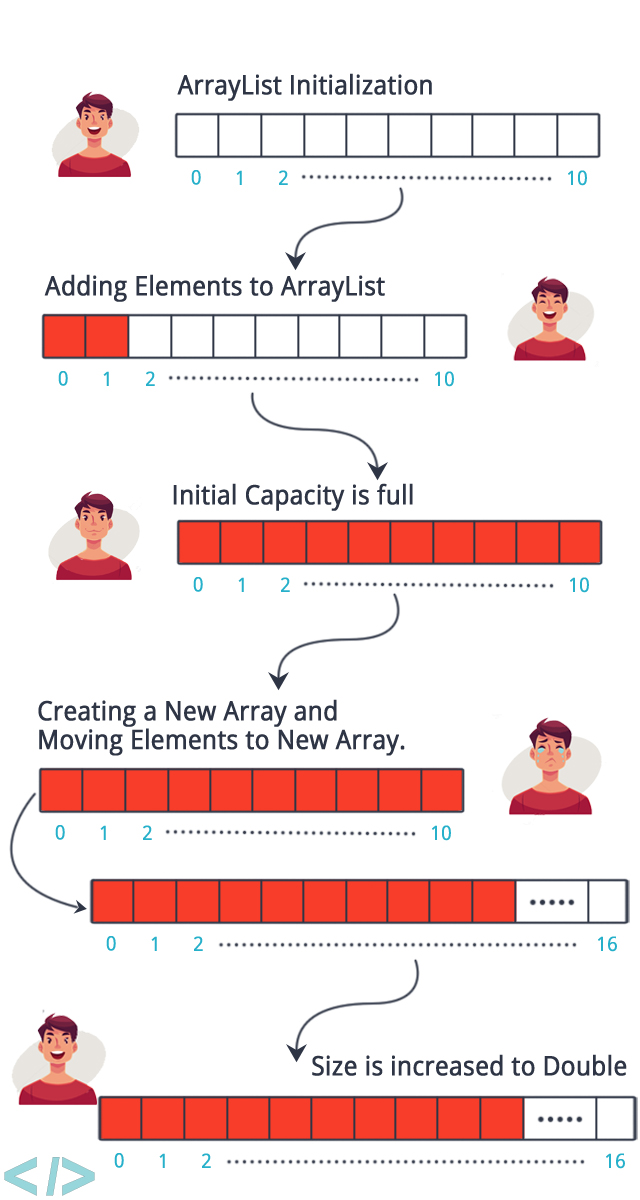
- 그렇기 때문에 Array 는 사이즈 예측이 잘 안 되는 데이터를 다루기에는 적절치 않다.
- 다행히도, 대부분의 언어에서는 배열 메모리의 pre-allocation과 resizing을 자동으로 실행하긴 하지만, 사이즈가 급격하게 자주 늘어날 확률이 있는 데이터는 array 말고 더 적합한 자료구조를 선택하는것이 좋다.
:: 그럼 Array는 언제 씀?
-
값보다는 순서가 더 중요한 순차열적인 데이터를 저장할 때
ex) 주식 가격 (어제, 오늘의 주가가 다름 ⇒ 값보다는 순서가 중요)
-
다중 차원 데이터(Multi-dimensional Array)를 다룰 때
-
어떠한 특정 요소를 빠르게 읽어야 할 때 = 데이터의 위치만 알면, index를 통해 바로 읽을 수 있기 때문에
-
데이터의 사이즈가 자주 변하지 않을 때
-
요소가 자주 삭제 되거나 중간에 추가되지 않을 때
Tuple
Tuple은 Python 에는 있지만 JavaScript 에는 없다!!
Tuple은 Array, List와 너무 비슷하기 때문에 굳이 제공하지 않는 언어도 많다고 한다....JavaScript도 그중 하나
JavaScript에서는 그냥 array를 사용하는걸로ㅎ!!
:: Tuple의 정의
- Array(List)와 마찬가지로 데이터를 순차적으로 저장할 수 있는 순열 자료구조!
- 하지만 list와 다르게 한 번 정의되고 나면 수정할 수 없다. (immutable)
- 2-3개 정도의 적은 수의 소규모 데이터를 저장할 때 많이 사용합니다.
- 함수에서 return 값을 한 개 이상 return하고 싶을 때 자주 쓰인다. (ex. 지도 좌표)
:: Tuple의 장점
-
Tuple은 간단한 값을 빨리 표현하고 싶을 때 많이 사용
-
예를 들면 함수에서 return 값을 한 개 이상 return하고 싶을 경우에 사용(ex. 지도 좌표)
Tuple을 사용하는 경우 vs class/object 를 사용하는 경우
// Tuple을 사용하는 경우... 한줄 컷!
[(1,2), (2,4)] // Array(List) 안의 Tuple
// Tuple을 안 쓰는 경우에는 class를 생성해야함
class cord:
def __init__(self, x, y):
self.x = x
self.y = y:: Tuple의 단점
-
Tuple의 단점은 데이터가 무슨 의미인지 명확하지 않다는 것....
그래서 데이터의 의미를 문맥을 보고 가정해야 한다.
(예를 들면 object의 경우
key-value쌍으로 이루어진 데이터이기 때문에 무슨 데이터인지 파악이 쉽지만, Tuple의 경우 괄호 안에 데이터만 담겨있기 때문에 문맥에 맞게 의미를 추측해야 함...) -
그렇기 때문에 Tuple은 소규모 데이터를 다루기에 적합!!
이러한 단점을 극복하기 위해 Python에서는 Named Tuple 이란 것도 존재한다고 함
:: 그래서 Tuple은 언제 씀?
- Tuple이 Array(List) 보다 더 가볍고 메모리도 적게 차지한다.
- ex) 좌표 데이터를 표현하고자 할 때, 아래와같이 3~4줄 컷 가능!
coordinations = [
(1, 2),
(3, 4),
(5, 6)
]