
오늘 세션은 Database!!!!
별로 이해는 못했지만 재밌당🤣
아무튼 아직은 어려운 개념이 많아서 부족한 내용은 더 공부하고 보충하겠습니당!!!!
틀린 내용은 언제든지 댓글/메일🥰!!!
암튼간에 Database 뿌셔!!!

Database (DB)
Database 란?
- 통합하여 관리되는 데이터의 집합체를 의미한다.
- 여러 사람에 의해 공유되어 사용될 목적으로 중복된 데이터를 없애고, 자료를 구조화하여, 효율적인 처리를 할 수 있도록 관리된다.
- Application에서는 데이터가 메모리 상에서 존재한다.
그러나, 메모리에 존재하는 데이터는 보존이 되지 않는다. 해당 애플리케이션이 종료하면 메모리에 있던 데이터들은 다시 읽어 들일 수 없다.
메모리는 휘발성이다. 데이터를 메모리에 저장하게 되면, 프로그램이 종료될 때 저장됐던 메모리가 모두 날아간다.
하지만, 그만큼 가볍고 속도가 빠르다!
그래서 보통은 데이터를 장기 기간동안 저장 및 보존 하기 위해서 데이터베이스를 사용하고,
저장된 데이터를 메모리에서 읽어들여서 가공 처리를 진행한다.
- 데이터베이스는 응용 프로그램과 다른 별도의 미들웨어에 의해 관리되며, 이러한 미들웨어를 데이터베이스 관리 시스템 ( DBMS : Database Management System )이라고 한다.
이 DBMS 안에서도 또 여러개로 나뉠 수 있는데, 크게 관계형 데이터베이스(RDBMS)와 "NoSQL"로 명칭되는 비관계형(Non-relational) database가 있다.
Database 왜 씀?
프로그램을 만들다 보면 프로그램 사용자들에 의해 생성된 데이터, 프로그래머가 필요에 의해 프로그램에 넣어놓은 데이터 등 필연적으로 많은 데이터들이 생성되어지게 된다.
그런데 데이터베이스를 사용하지 않으면?? 이 데이터들은 프로그램을 종료하는 순간 전부 날아간다........

이런 현상을 방지하기 위해 데이터들을 데이터베이스에 넣고 보관한다!
Database 의 특징
-
사용자의 질의에 대하여 즉각적인 처리와 응답이 이루어진다.
-
생성, 수정, 삭제를 통하여 항상 최신의 데이터를 유지한다.
-
사용자들이 원하는 데이터를 동시에 공유할 수 있다.
-
사용자가 원하는 데이터를 주소가 아닌 내용에 따라 참조 할 수 있다.
-
응용프로그램과 데이터베이스는 독립되어 있으므로, 데이터의 논리적 구조와 응용프로그램은 별개로 동작한다.
Database 용어
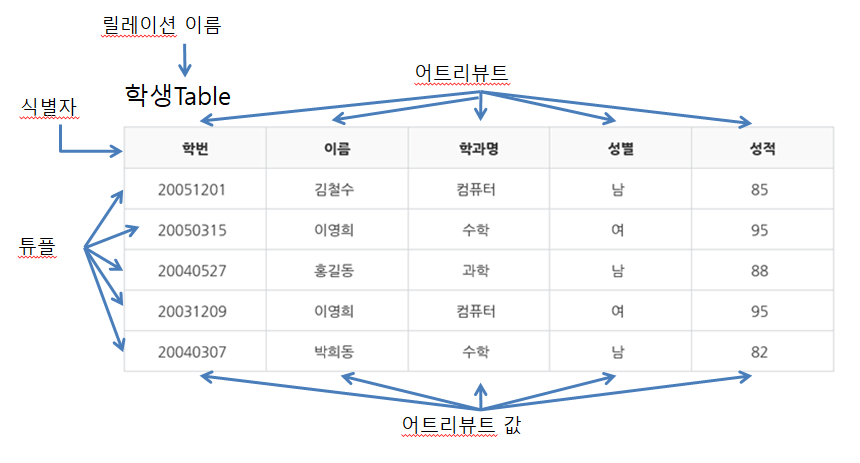
식별자(identifier) : 여러개의 집합체를 담고있는 관계형 데이터베이스에서 각각의 구분할 수 있는 논리적인 개념
식별자의 특성!
유일성 : 하나의 릴레이션에서 모든 행은 서로 다른 key 값을 가져야 한다.
최소성 : 꼭 필요한 최소한의 속성들로만 key를 구성해야 한다.
튜플(Tuple) : 테이블에서 행을 의미
같은 말로 레코드(Record) 혹은 로우(Row)라고도 부른다. 튜플은 릴레이션에서 같은 값을 가질 수 없다.
튜플의 수는 카디날리티(Cardinality) 라고 합니다.
어트리뷰트(Attribute) : 테이블에서 열을 의미
같은 말로 칼럼(Columm)이라고도 부르며, 어트리뷰트(Attribute)의 수를 의미하는 단어는 디그리(Degree)라고 한다.
관계형 데이터베이스
( RDBMS, Relational DataBase Management System )
-
이름 그대로, 관계형 데이터 모델에 기초를 둔 데이터베이스 시스템이다.
이 때, 관계형 데이터란 데이터를 서로 상호관련성을 가진 형태로 표현한 데이터를 말한다. (마치 엑셀같이 생겼음...)
- 모든 데이터들을 2차원 테이블(table)들로 표현
- 각각의 테이블은 컬럼(column)과 로우(row)로 구성된다.
- 컬럼은 행을 의미하며, 테이블의 각 항목을 말한다.
- 로우는 열을 의미하며, 각 항목들의 실제 값들을 이야기 한다.
- 각 로우는 저만의 고유 키(Primary Key)가 있다. 주로 이 primary key를 통해서 해당 로우를 찾거나 인용(reference)한다.
-
각각의 테이블들은 서로 상호관련성을 가지고 서로 연결될 수 있다.
-
테이블끼리의 연결에는 크게 3가지 종류가 있다. 요녀석들에 대한 설명은 아래에서!!!!
- one to one
- one to many
- many to many
대표적인 관계형 데이터베이스 : MySQL, PostgreSQL(줄여서 Postgres) 등
One To One (1 : 1)
테이블 A의 로우와 테이블 B의 로우가 정확히 1:1 매칭이 되는 관계
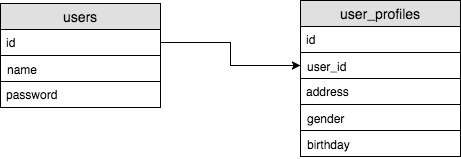
ex : User 테이블과 User의 부가적인 정보를 저장하고 있는 User_profiles 테이블이 있다.
하나의 User 정보의 단 하나의 User_profile 을 가리킨다.
예를 들어서, solmi 라는 user가 있다면, 이 user의 id password 등은 하나밖에 없다.
One To Many (1 : n)
테이블 A의 로우가 테이블 B의 여러 로우와 연결이 되는 관계
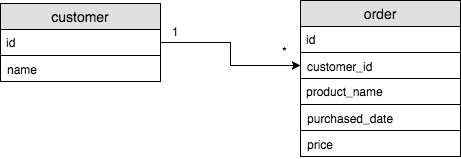
예를 들어서, 쇼핑몰의 food 라는 category에 fruit vegetable meat 등의 item이 담겨 있다면, food 카테고리는 여러개의 상태값을 가지지만, 각각의 fruit vegetable meat 들은 food 라는 하나의 카테고리만 가진다.
한 카테고리 안에 여러 메뉴가 속한것도 1:n 이고, 한명의 user가 여러개의 주문을 했다 도 1:n으로 표현
Many To Many (n : m)
테이블 A의 여러 로우가 테이블 B의 여러 로우와 연결이 되는 관계

예를 들어서, book1 과 book2 책을 author1 과 author2 가 공동으로 썼다면, 그림의 중간에 있는 authors_books 테이블에서 각각 books 테이블과 authors 테이블을 참조하여 n : m으로 연결할 수 있다.
⇒ 하나의 book1 id에 author1 , author2 2개가 들어갈 수 있음
이때 이 중간 테이블을 join table 이라고 부른다.
오늘 세션 듣고 한번 해봤당!!!! 멘토님께 보여줬는데 완전 잘 이해했다고 하셔서 정리해서 올려본당👍🤣
예를 들어,
authors table
| id | name |
|---|---|
| 1 | 홍길동 |
| 2 | 성춘향 |
| 3 | 이몽룡 |
books table
| id | name |
|---|---|
| 1 | 별주부전 |
| 2 | 홍길동전 |
| 3 | 콩쥐팥쥐전 |
이렇게 2개의 테이블을 연결하려고 한다!!!
근데.... 책 한권을 작가 한명이 쓴게 아니라, 여러명이 공동으로 썼다면?
books table
| id | name | author_id |
|---|---|---|
| 1 | 별주부전 | 홍길동,성춘향 |
| 2 | 홍길동전 | 성춘향, 이몽룡 |
| 3 | 콩쥐팥쥐전 | 홍길동, 이몽룡 |
이렇게 쓰면 될 것 같지만....! 실제 Database 에서는 물리적으로 불가능하다.....
그래서 중간에 join table로 각각의 data를 연결해주는것!
| id | author_id | book_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 1 |
| 3 | 2 | 2 |
| 4 | 3 | 2 |
| 5 | 1 | 3 |
| 6 | 3 | 3 |
요렇게!!!!!
테이블끼리는 어떻게 연결할까?
- 주로 Foreign key(외부키)라는 개념을 사용하여 연결한다.
- 앞서 본 one to one 예에서
user_profiles테이블의user_id컬럼은 users 테이블에 걸려있는 Foreign key라고 지정한다. - 즉 데이터베이스에게
user_id의 값은 users 테이블의id값이며 그러므로 users 테이블의id컬럼에 존재하는 값만 생성될 수 있다.- 만일 users 테이블에 없는
id값이user_id에 지정되면 에러가 난다.
- 만일 users 테이블에 없는
테이블 연결은 근데 왜 하는 거지?
애초에 테이블 연결은 왜 하는 걸까? 그냥 하나의 테이블에 모든 정보를 다 때려 넣으면 어떻게 되지?
- 하나의 테이블에 모든 정보를 다 넣으면 동일한 정보들이 불필요하게 중복되어 저장된다.
- 더 많은 디스크를 사용하게 되고, 잘못된 데이터가 저장 될 가능성이 높아진다.
( ex : 고객의 아이디는 동일한데 이름이 틀린 로우들이 있다면 어떻게 해야 하는가? 어떤 이름이 정확한건가? )
- 더 많은 디스크를 사용하게 되고, 잘못된 데이터가 저장 될 가능성이 높아진다.
- 여러 테이블에 나누어서 저장한후 필요한 테이블 끼리 연결 시키면 위의 문제가 사라진다.
- 중복된 데이터를 저장하지 않음으로 디스크를 더 효율적으로 쓸 수 있다.
- 또한 서로 같은 데이터이지만 부분적으로 다른 데이터가 생기는 문제가 없어진다.
⇒ 이것을 normalization (정규화) 이라고 한다.
1,2,3 정규화라고 있긴 한데.... 너무 어려워서ㅠㅠㅠㅠ 일단 설명 잘되있는 블로그 주소 첨부함당....😱
누구 이해하신분 wecode 9기 강솔미한테 설명좀........
트랜잭션(Transaction)
트랜잭션이라는건, 한 번 질의가 실행되면 질의가 모두 수행되거나 모두 수행되지 않는 작업수행의 논리적 단위 이다.
한국말은 맞는데...읽을수가 없다.... 여기에 대해 쉽게 설명해준 블로그가 있어서 내용을 긁어 왔다!
트랜잭션이란 질의(query)를 하나의 묶음 처리해서 만약 중간에 실행이 중단됐을 경우,
처음부터 다시 실행하는 Rollback을 수행하고, 오류없이 실행을 마치면 commit을 하는 실행 단위를 의미합니다.
즉, 한 번 질의가 실행되면 질의가 모두 수행되거나 모두 수행되지 않는 작업수행의 논리적 단위입니다.
예를 들어, 친구에게 인터넷 뱅킹으로 10,000원을 송금하는 상황을 가정해보겠습니다.
제가 친구에게 송금을 한다면, 저의 계좌에서 10,000원을 차감하고 친구의 계좌에 10,000원을 증가시켜야 하는데,
알 수 없는 오류로 인해 저의 계좌에서는 10,000원이 줄었지만 친구 계좌에는 10,000원이 증가되지 않는다면 어떻게 될까요?
저의 10,000원은 그냥 공중으로 증발해버리는 문제가 발생합니다.
이러한 경우가 생기지 않도록 중간에 오류가 발생하면 다시 처음부터 송금을 하도록 하는 것이 rollback입니다.
오류 없이 정상적으로 송금이 됐다면 정상적으로 실행이 끝났으므로 commit을 합니다.
즉, 송금 과정을 하나의 트랜잭션이라 볼 수 있습니다.
참고로 트랜잭션을 작업수행의 논리적 단위라고 했는데요, 때문에 DBMS의 성능은 초당 트랜잭션의 실행 수( TPS : Transaction per second )로 측정합니다.
< 출처 : https://victorydntmd.tistory.com/129 >
아하!! 그러니까 중간에 오휴가 나면, 처음부터 다시 실행되고, 오류없이 실행을 마치면 그때서야 commit을 하는 하나의 실행 과정 단위를 트랜잭션이라고 부르는구만~
ACID(Atomicity, Consistency, Isolation, Durability)
-
원자성 (Atomicity) 은 트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 능력이다.
예를 들어, 자금 이체는 성공할 수도 실패할 수도 있지만 보내는 쪽에서 돈을 빼 오는 작업만 성공하고 받는 쪽에 돈을 넣는 작업을 실패해서는 안된다.
원자성은 이와 같이 중간 단계까지 실행되고 실패하는 일이 없도록 하는 것이다. -
일관성 (Consistency) 은 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다.
무결성 제약이 "모든 계좌는 잔고가 있어야 한다" 라면, 이를 위반하는 트랜잭션은 중단된다. -
고립성/격리성 (Isolation) 은 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것을 의미한다.
이것은 트랜잭션 밖에 있는 어떤 연산도 중간 단계의 데이터를 볼 수 없음을 의미한다.
예를 들어, 은행 관리자는 이체 작업을 하는 도중에 쿼리를 실행하더라도 특정 계좌간 이체하는 양쪽을 볼 수 없다. 공식적으로 고립성은 트랜잭션 실행내역은 연속적이어야 함을 의미한다. -
지속성 (Durability) 은 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미한다.
DB 일관성 체크나 시스템 문제 등이 발생 하더라도 유지되어야 함을 의미한다.
전형적으로 모든 트랜잭션은 로그로 남고 시스템 장애 발생 전 상태로 되돌릴 수 있다.
트랜잭션은 로그에 모든 것이 저장된 후에만 commit 상태로 간주될 수 있다. (commit을 하면 현재 상태는 영원이 보장)
비관계형 데이터베이스 (NoSQL)
-
비관계형 타입의 데이터를 저장할때 주로 사용되는 데이터베이스 시스템
-
관계형 데이터베이스와 다르게 비관계형 이기 때문에 데이터들을 저장하기 전에 정의 할 필요가 없다.
( 관계형 데이터베이스는 데이터들을 저장하기 전에 어디에 어떻게 저장할것인지를 정의,
즉 테이블을 정의해야한다. (테이블 이름, 테이블과 다른 테이블의 관계, 각 컬럼의 타입 등등 )) -
대표적으로 MongoDB, Redis, Cassandra 등이 있다.
SQL(RDBMS) vs NoSQL
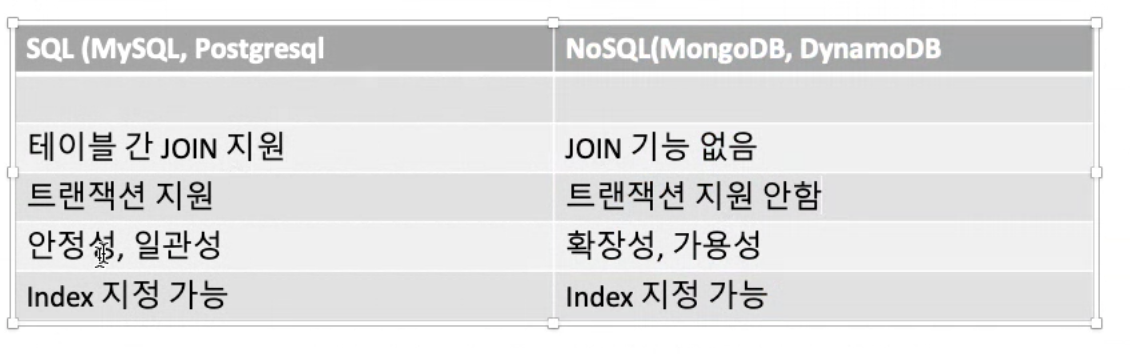
SQL(RDBMS)
정형화된 데이터들, 데이터의 완전성이 중요한 데이터들을 저장하는데 유리하다.
( ex : 전자상거래 정보. 은행 계좌 정보, 거래 정보 등등 )
장점
-
관계형 데이터베이스는 데이터를 더 효율적으로 그리고 체계적으로 저장할 수 있고 관리 할 수 있다.
-
미리 저장하는 데이터들의 구조 (테이블 스키마) 를 정의 함으로 데이터의 완전성이 보장된다.
-
트랜잭션(transaction)을 통해 데이터를 처리하는 과정에서 발생할 수 있는 실수를 막을 수 있다.
단점
-
테이블을 미리 정의해야 함으로 테이블 구조 변화 등에 덜 유연한다.
-
확장성이 쉽지 않다.
- 역시 테이블 구조가 미리 정의 되어 있다보니 단순히 서버를 늘리는것 만으로 확장하기가 쉽지 않고 서버의 성능 자체도 높여야 한다.
- 서버를 늘려서 분산 저장 하는것도 쉽지 않다.
- Scale up 으로 확장이 가능하긴 하다.
NoSQL
주로 비정형화 데이터, 완전성이 상대적으로 덜 유리한 데이터를 저장하는데 유리하다.
( ex : 로그 데이타 )
장점
-
테이터 구조를 미리 정의하지 않아도 됨으로 저장하는 데이터의 구조 변화에 유연하다.
-
확장하기가 비교적 쉽다. scale out 으로 서버 수를 늘리기만 하면 끝!
-
확장하기가 쉽고 테이터의 구조도 유연하다 보니 방대한 양의 데이터를 저장하는데 유리하다.
단점
-
데이터의 완전성이 덜 보장된다.
-
트랜잭션이 안되거나 비교적 불안정하다.
Scale Up vs Scale Out
Scale up 이란, 서버 그 자체를 증강하는 것을 말한다.
즉, 리소스를 붙여서 물리적인 용량을 키워서 처리 능력을 향상시키는 것이다.
고성능 프로세서 모델을 이용한다거나, 고가의 장비로 옮긴다거나 해서 서버를 증강하는 것을 의미한다.
다른 말로는 수직 스케일이라고도 부른다.( 나는 현질 스케일 업 이라고 부르고싶다... )
Scale Out 이란, 접속된 서버의 대수를 늘려서 처리 능력을 향상시키는 것을 말한다.
쉽게 말하면 서버의 가상화 기능을 이용하여 하나의 케이스 내에서 가상적으로 복수 서버를 구축하는 것이다.
수평 스케일, 가상 스케일 아웃 이라고도 부른다.
 개발 왕초보 코린이입니다!
개발 왕초보 코린이입니다!
이 내용은 혼자 동영상 강의&구글링을 통해 배운 내용을 정리하는 것으로, 제가 이해하고 넘어간 개념이 틀렸거나 더 보충할 개념이 있다면 댓글 남겨주시면 정말 감사하겠습니다!!
