https://medium.com/@Khuranasoils/machine-learning-basics-f58678cf9c15
https://www.dataversity.net/getting-back-basics-machine-learning/
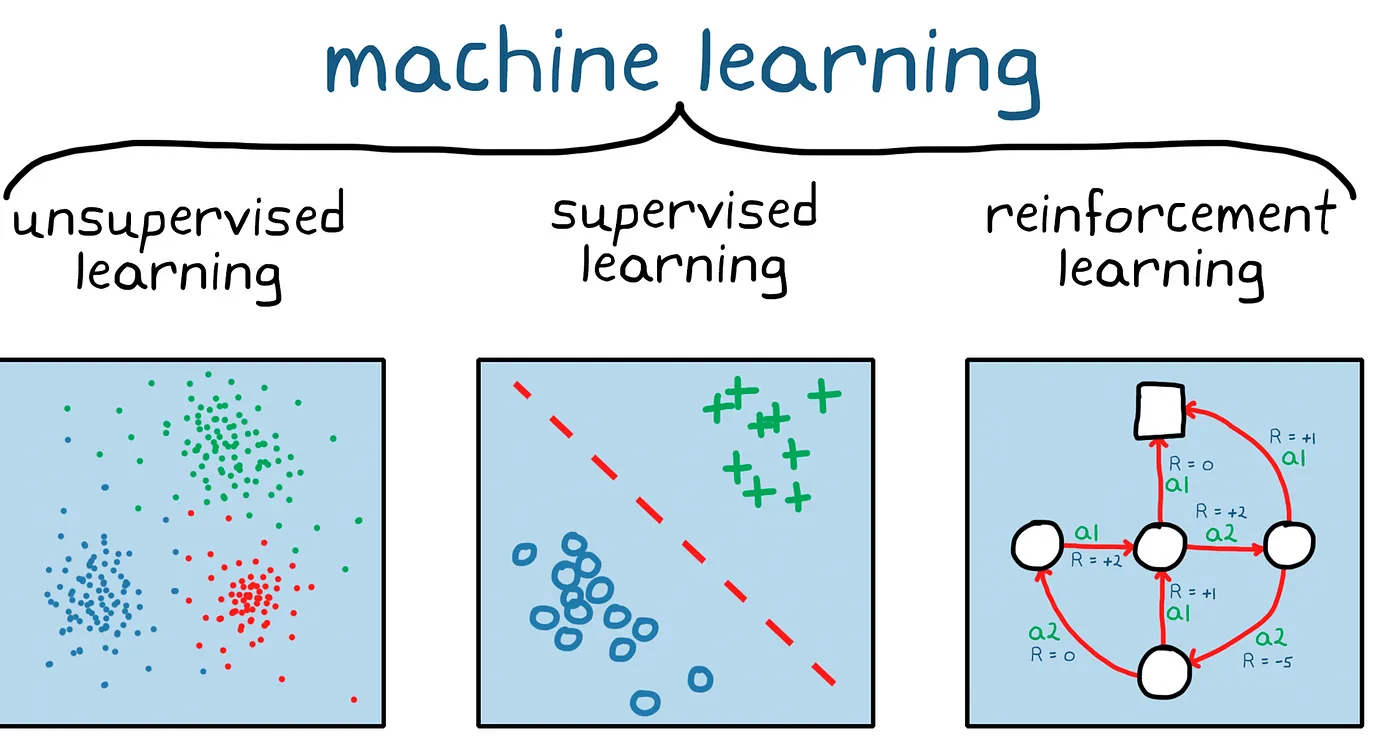
1. 기계학습의 분류
1) 지도학습 (Supervised Learning)
: Label이 달린 데이터를 사용하여 모델을 학습시키는 방법
모델은 주어진 데이터를 바탕으로 정답을 예측하는 방법을 학습함
ex) 정답에 해당하는 객체(개, 고양이 등)가 있는 이미지 데이터셋을 학습시켜서 새로운 이미지가 주어졌을 때 어떤 객체인지 예측하는 모델을 만드는 것!
"Right Answers" given (Noise가 없다는 가정 하에)
* 사용 예시 : 이미지 분류, 음성 인식, 이메일 스팸 필터링
* 알고리즘 : 선형 회귀, 의사결정나무, 서포트 벡터 머신, 신경망 등
2) 비지도학습 (Unsupervised Learning)
: Label이 없는 데이터를 통해 패턴을 찾는 방법
-> 데이터 간의 유사성을 분석하여 데이터를 군집화거나, 이상치 탐지에 자주 사용됨
* 사용 예시 : 군집화(Clustering), 차원 축소(Dimensionality Reduction), 이상치 탐지(Anomaly Detection)
* 알고리즘 : K-평균 군집화, 주성분 분석(PCA), t-SNE, 오토인코더 등
3) 강화학습 (Reinforcement Learning)
: 에이전트가 환경과 상호작용하며 보상을 최대화하도록 학습하는 방법
-> 에이전트는 특정 행동을 할 때마다 보상 또는 벌칙을 받으며, 이를 통해 가장 좋은 행동을 찾아감
주로 순차적인 의사결정 문제에서 자주 사용됨
* 사용 예시 : 게임 플레이(알파고), 로봇 제어, 자율 주행차
* 알고리즘 : Q-learning, Deep Q-Network (DQN), 정책 경사법(Policy Gradient)
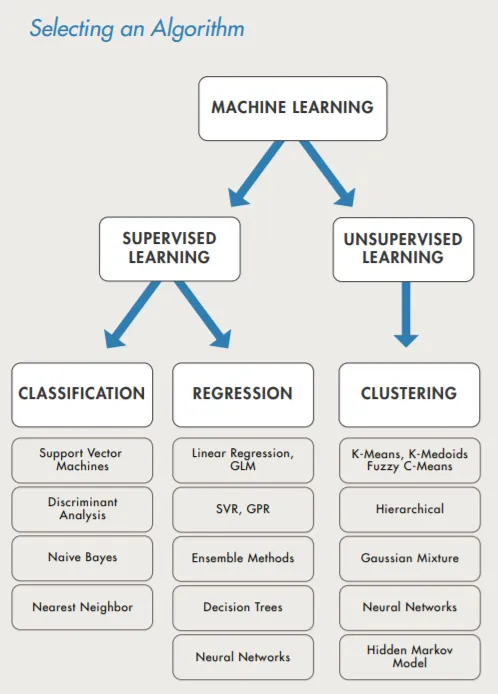
2. 지도학습의 종류
1. 분류 (Classification)
: 주어진 입력 데이터를 사전에 정의된 여러 클래스 중 하나로 분류하는 문제
출력값은 이산적인(Discrete) 범주!
<분류 문제의 알고리즘 종류>
- 로지스틱 회귀(Logistic Regression)
- K-최근접 이웃(K-Nearest Neighbors, KNN)
- 서포트 벡터 머신(Support Vector Machines, SVM)
- 결정 트리(Dicision Tree)
- 랜덤 포레스트(Random Forest)
- XGBoost(Extreme Gradient Boosting)
- 신경망(Neural Networks)
2. 회귀 (Regression)
: 주어진 입력에 대해 연속적인 출력값을 예측하는 문제
예측값과 실제값 사이의 오차를 줄이는 것이 목적
출력값은 연속적인(Continuous) 실수 값!
<회귀 문제의 알고리즘 종류>
- 선형 회귀(Linear Regression)
- 다중 선형 회귀(Multiple Linear Regression)
- 릿지 회귀(Ridge Regression)
- 라쏘 회귀(Lasso Regression)
- 다항 회귀(Polynomial Regression)
- 의사결정 트리 회귀(Decision Tree Regression)
- 랜덤 포레스트 회귀(Random Forest Regression)
- 신경망 회귀(Neural Network Regression)
3. 그 외
1) 다중 클래스 분류(Multi-Class Classification)
하나의 데이터가 여러 클래스 중 하나에 속하는 문제
2) 다중 레이블 분류(Multi-Label Classification)
하나의 데이터가 여러 개의 레이블에 동시에 속할 수 있는 문제
3) 순서형 회귀(Ordinal Regression)
범주형 변수 간의 순서가 존재하는 문제
4) 시계열 예측(Time Series Prediction)
특정 시간에 따른 데이터를 기반으로 미래 값을 예측하는 문제
