Machine Learning
1.1. 기계학습에 대하여
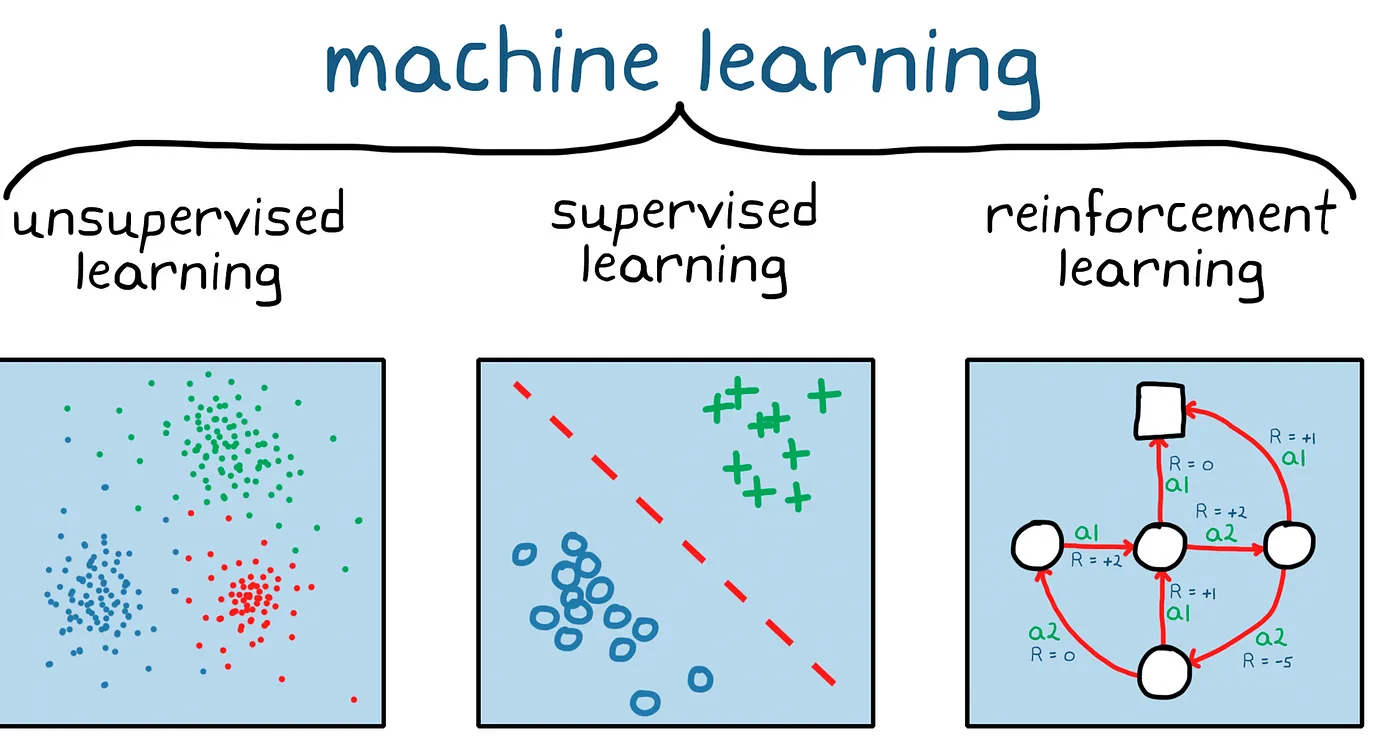
https://medium.com/@Khuranasoils/machine-learning-basics-f58678cf9c15https://www.dataversity.net/getting-back-basics-machine-learning/모델은 주어
2.2. 선형 회귀(Linear Regression)
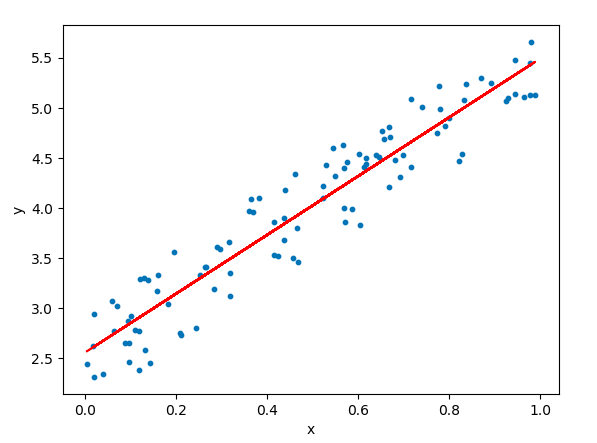
하나의 독립 변수만 있을 경우 사용됨https://www.kdnuggets.com/2020/05/5-concepts-gradient-descent-cost-function.htmlhttps://www.linkedin.com/pulse/understan
3.3. Linear Regression with multiple variables
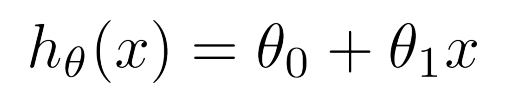
Feature = 1일때 가설함수< Multiple Variables>Feature = 4일때 가설함수 (n = 4)\-> 계산 편의를 위해 x0 = 1을 추가함normalization하지 않으면 각 변수마다 범위가 달라서 특정 변수에 민감해짐이상적인 범위: -1
4.4. Logistic Regression, Classification
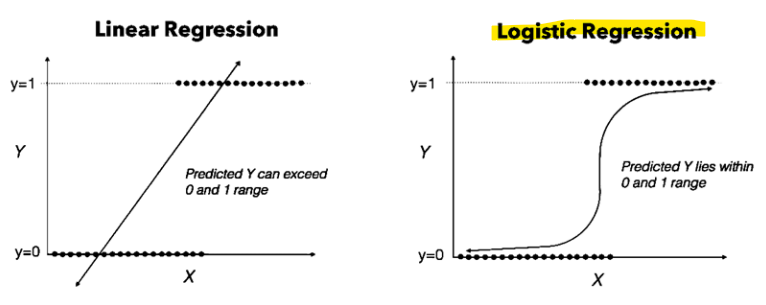
\-> 활성화 함수 중 Sigmoid (= Logistic) function을 사용\-> y = 0일 확률 + y = 1일 확률의 합은 1\-> z가 0보다 크거나 같을 때 g(z)가 0.5보다 크거나 같음\-> x1 + x2 >= 3의 경우, y = 1\-> x1 +
5.5. Regularization, The problem of overfitting
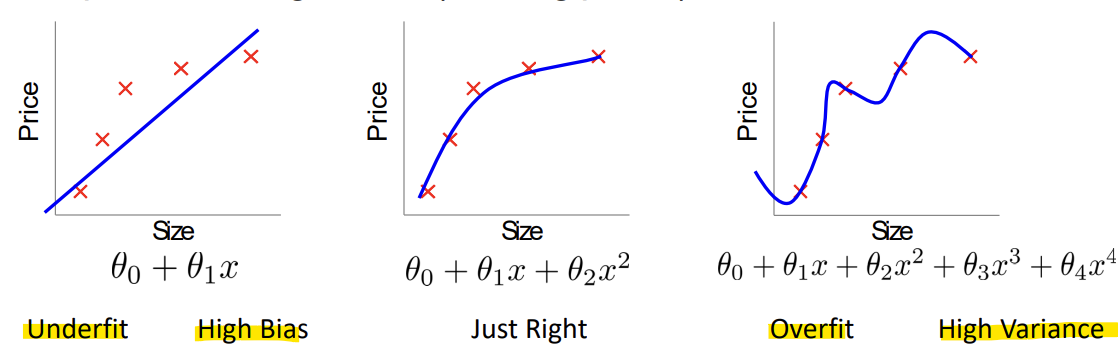
: 너무 많은 features를 가지게 되면, 학습된 가설이 training set에서는 매우 잘 맞을 수 있지만, 새로운 예시들에 대해서는 일반화하지 못할 수 있음Underfit (High Bias): 문제 복잡도보다 파라미터 수가 적음Overfit (High Var
6.6. Neural Networks: Representation
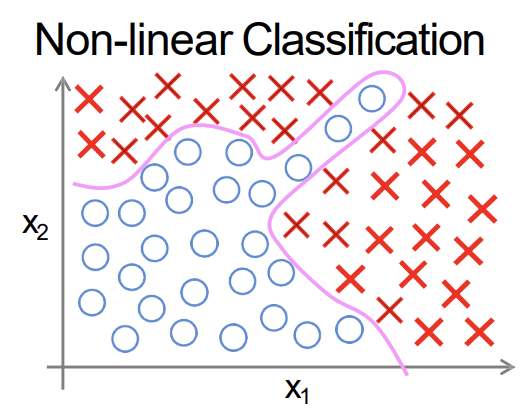
Non-linear classification -> Polynomial로 풀지 못함\-> feature 수가 너무 많아짐One learning algorithm: 뇌가 하나의 일반적인 학습 알고리즘을 사용해 다양한 종류의 학습을 수행한다는 아이디어를 제안함\-> 인간이
7.7. Neural Networks: Learning

- Cost function - Backpropagation algorithm
8.8. Advice for applying machine learning
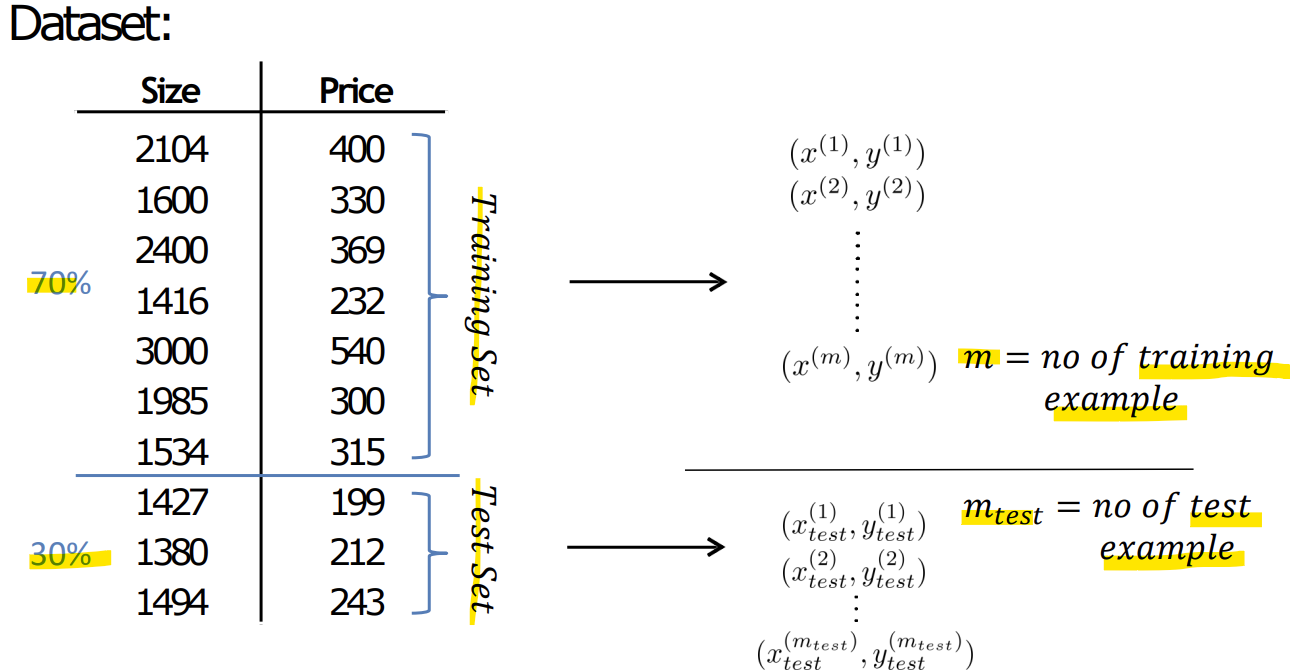
더 많은 훈련 데이터 얻기더 작은 feature 집합 사용 시도추가적인 feature 얻기 시도다항식(polynomial) feature 추가 시도lambda (정규화 항) 줄이기lambda 늘리기learning rate 늘리기, 줄이기iteration 수 늘리기, 줄
9.11. Evaluation
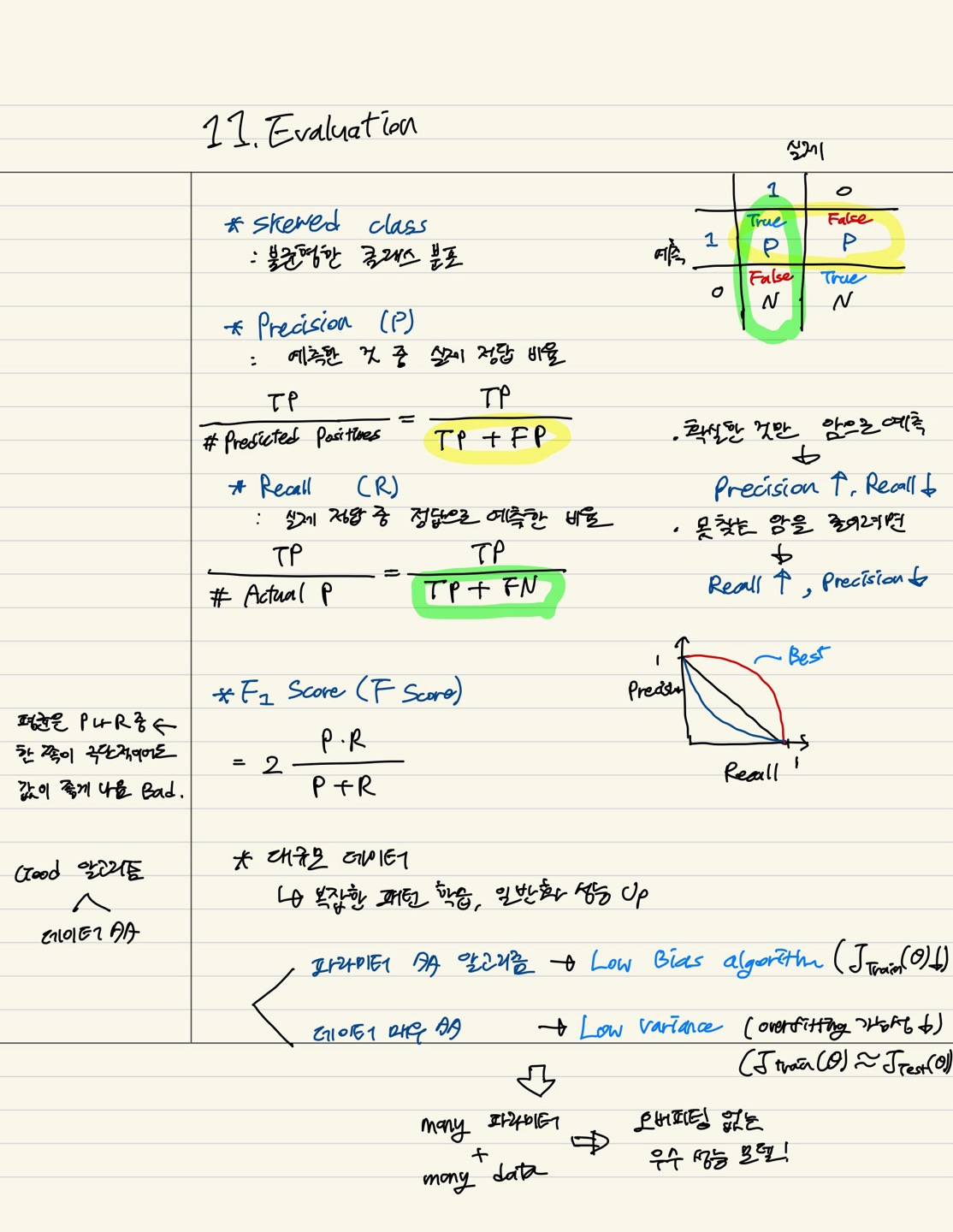
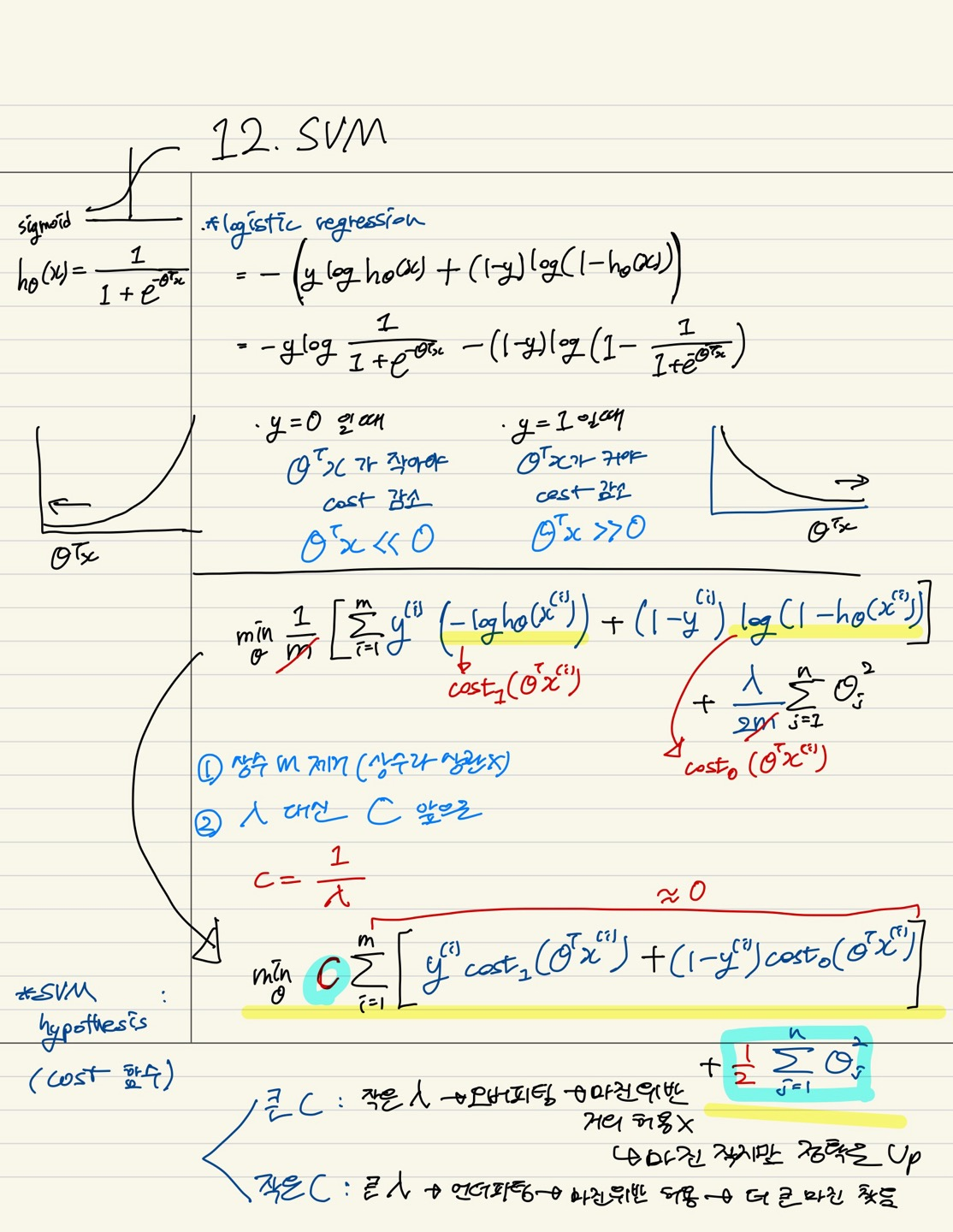
10.12. SVM(Support Vector Machine)
11.13. K-means

12.14. PCA(Principal Component Analysis)

13.15. PCA vs LDA

14.16. Bayesian Decision

15.17. Anomaly Detection
