- The Market-Basket Model
-
items의 large set
ex) 마켓에서 판매하는 상품들 -
baskets의 large set
: 각각의 basket은 items의 작은 subset

-
두 가지 종류의 항목들 간의 일반적인 many-to-many mapping (association)
-
items와 baskets는 abstract(추상적 개념)
ex)
items = products, words, drugs
baskets = shopping basket,documents, patients
- Applications
1)
- Baskets: 한 번의 매장에서 구매한 제품들의 집합
- Items: 제품들
2)
-
Baskets: sentences
-
Items: 그 문장들을 포함하는 documents
-> 너무 자주 함께 나타나는 아이템들은 표절을 나타낼 수 있음 -
Baskets: 환자들
-
Items: 약물 및 부작용
-> 특정 부작용을 일으키는 약물의 조합을 감지하는 데 사용된 적 있음
- Frequent Itemsets
* Support(지지도) for itemset I
: I의 모든 items를 포함하는 baskets의 수
-> 보통 전체 baskets의 수에 대한 비율(fraction)로 표현함
- Frequent itemsets : Support threshold s가 주어졌을 때, 최소 s개의 baskets에 나타나는 아이템 집합


-> 3번(support threshold) 이상 등장하면 Frequent itemsets
- Association Rules
- 정의 : baskets의 내용에 대한 if-then 규칙
{i1, i2, …, ik} → j
-> "basket에 i1, ... ik가 모두 있으면 j도 있을 가능성이 높다"라는 의미
* Confidence(신뢰도) of this association
: I = {i1, i2, …, ik} 일 때 j가 나올 확률
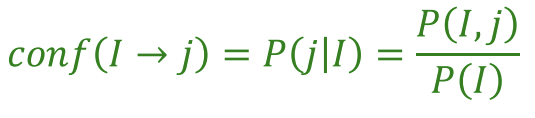
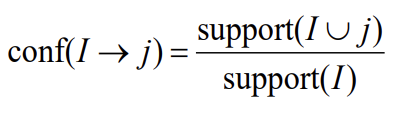
- 모든 높은 신뢰도의 규칙이 흥미로운 것은 아님
-> 우유는 많은 아이템 집합 X에 대해 높은 신뢰도를 가질 수 있는데, 이는 우유가 그 자체로 매우 자주 구매되기 때문에(X와 무관하게) 신뢰도가 높게 나올 수 있음
* Interest(흥미도) of an association rule

-> 절댓값을 사용하는 이유: 아이템 집합과 아이템 간의 긍정적 및 부정적 연관성을 모두 포착하기 위해서
- Interesting rules : Interest values(흥미도 값)가 높은 규칙 (보통 0.5 이상)

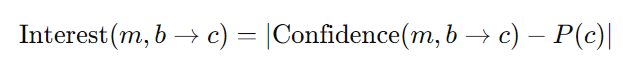
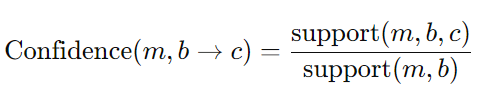
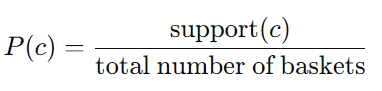
- Finding Association Rules
- 문제: support(지지도) >= s, confidence(신뢰도) >= c 인 모든 association rule 찾기
-> Support는 왼쪽 항목 집합의 지지도를 나타냄

- 어려운 부분: Frequent itemsets를 찾는 것!
-> 만약 {i1, i2,..., ik} -> j 의 support와 confidence값이 높다면,
{i1, i2,..., ik}와 {i1, i2,..., ik, j} 둘 다 Frequent일 것!
<모든 Association Rules을 찾는 레시피>
-> support s, confidence c
1) support가 최소한 s인 모든 집합 찾기
2) support가 최소한 s/c인 모든 집합 찾기
3) {i1, i2,..., ik, j}가 최소한 s인 support를 가진다면, j가 빠진 모든 부분집합의 support가 최소한 s/c인지 확인
{i1, i2,..., ik}가 s1 >= s/c 이면서
{i1, i2,..., ik, j}가 s2 >= s 이면서
s2/s1(=confidence)이 최소한 c 이상이면
=> {i1, i2,..., ik, j}는 유효한 association rule!
Step 1: 모든 frequent itemsets I를 찾기
Step 2: Rule 생성
-> I의 모든 부분집합 A에 대해, rule A -> I|A(I에서 A를 제외)를 생성하기
-> I가 frequent이므로, A도 frequent
- 변형 1: rule confidence를 계산하는 단일 패스 방법

- 변형 2: Observation: 만약 A,B,C -> D가 confidence 기준을 넘지 못하면, A,B -> C,D도 그럴 것
-> 생성한 rule 중에서 confidence threshold를 넘는 rule만 출력하기

< rule 출력 축소하기 >
- rule 수를 줄이기 위해 post-process를 진행하고 다음만 출력 가능함
- Maximal frequent itemsets
: 그 집합의 즉시 상위집합(하나 더한 상위집합)은 frequent하지 않은 항목 집합
-> 가지치기됨
- Closed itemsets
: 그 항목 집합과 같은 지지도(support)를 가지는 즉시 상위 집합이 없는 항목 집합(>0)
-> frequent 정보뿐만 아니라 정확한 항목의 개수(빈도, support)를 저장하는 것

- Finding Frequent Itemsets
- Itemsets: 계산 모델
-
data -> flat files에 저장(db 말고)
-
disk에 저장됨 (memory에 저장하기에는 너무 큼)
-
basket별로 저장됨
-
basket을 읽을 때 항목들을 pairs, triples등으로 확장하라
-
크기가 k인 모든 항목 집합을 생성하려면 k개의 중첩 반복문 사용하라
-
디스크에 상주하는 데이터를 탐색 시 실제 비용 : 디스크 입출력(I/O) 횟수
-> 데이터에 대해 수행하는 pass 횟수로 비용 측정 -
association-rule algorithms은 데이터를 여러 번 읽는데, 이는 모든 basket을 순차적으로 읽는 방식
- 메인 메모리 병목현상(Bottleneck)
- 많은 frequent itemset 알고리즘에서 주요 자원: main-memory
- Frequent 쌍 찾기
-
frequent pairs는 흔하지만 frequent triples는 적음
-
frequent할 확률은 크기와 함께 exponentially 감소함
-
집합의 수는 크기와 함께 더 천천히 증가함
-
잠재적으로 frequent할 수 있는 itemset만 기록하고 싶음(공간 절약을 위해)
- Frequent pairs를 찾는 Naive(단순한) 접근법
-
n개의 basket에서 n(n-1)/2개의 pairs를 만들 수 있음(중첩 루프 사용)
-
(#items)^2가 메인 메모리를 초과하면 실패
ex) 10^5 items가 있고, count는 4-byte 정수이므로
10^5(10^5 - 1)/2 = 5 * 10^9
= 20GB가 필요함
- 메모리에서 항목 쌍을 세는 2가지 방법
- 각 항목 쌍 (i,j)의 발생 횟수 count
- 접근법 1: (삼각형)행렬을 사용하여 모든 쌍을 센다
- 접근법 2: 삼중항 [i, j, c]
