Data Mining
1.1. Data Mining Preliminaries
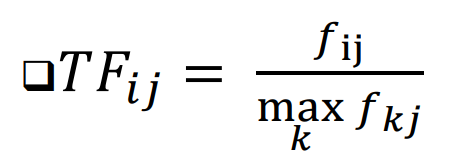
Search Engine에서 특정 검색어를 기준으로 14억 7천만 개의 문서의 순위를 어떻게 매길까?가장 유명한 measure(측정 방법) : TF.IDF\-> TF : 단어가 자주 등장할수록 그 단어는 문서에 중요\-> IDF : 특정 문서에만 등장하는 단어일수록 그
2.2. Distributed Computing for Data Mining, MapReduce
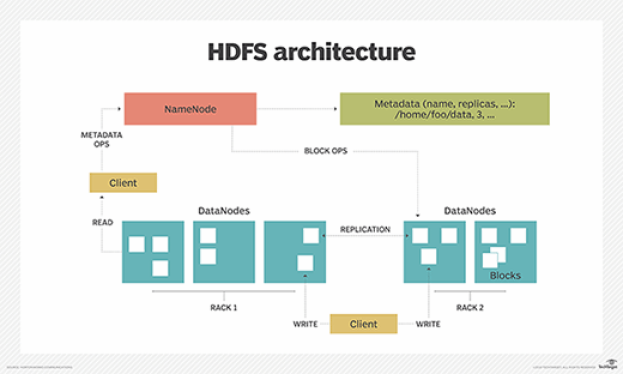
대규모 컴퓨팅을 일반 하드웨어로 데이터 마이닝 문제에 어떻게 적용할까?계산을 어떻게 분산시킬까: 하나의 서버는 약 3년동안 정상 작동: 1000개의 서버가 있다면, 하루에 1대가 고장남문제 : 네트워크를 통해 데이터를 복사하는 데 시간이 소요됨 (노드의 지속성 및 가용
3.3. Spark Tutorial, PySpark
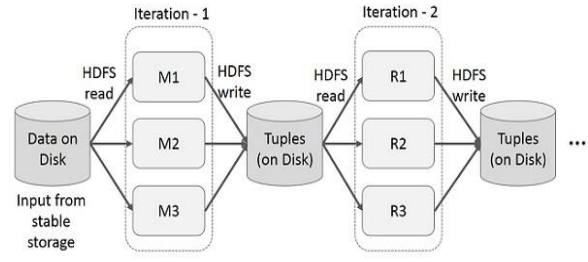
: MapReduce는 데이터 복제, 디스크 I/O, 직렬화로 인해 상당한 오버헤드가 발생함\-> Mapper M의 출력은 디스크에 저장되고 정렬된 후, 다시 Reducer R가 이를 읽음 (HDFS read, HDFS write)MapReduce로 직접 프로그래밍하기
4.4. Data Preparation
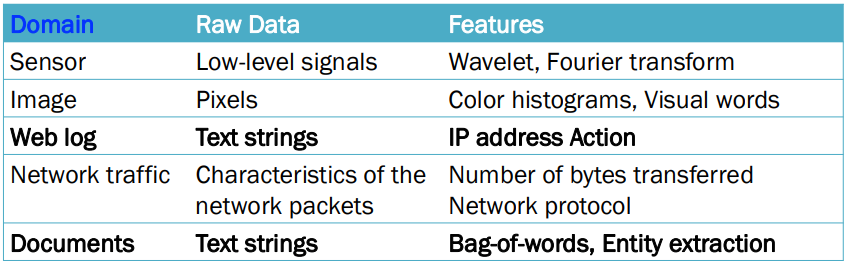
\-> 데이터 내에 다양한 유형의 데이터가 섞여 있음ex) 인구 통계 데이터 셋은 숫자(numeric) 및 혼합 속성(mixed attributes)을 모두 포함할 수 O가능한 해결책: 다양한 데이터 유형의 임의 조합을 처리할 수 있는 알고리즘 설계\-> 시간 소모가
5.5. Frequent Itemsets & Association Rules

- The Market-Basket Model items의 large set ex) 마켓에서 판매하는 상품들 baskets의 large set : 각각의 basket은 items의 작은 subset 두 가지 종류의 항목들 간의 일반적인 many-to-many m