1. Feature Extraction and Portability
- Feature Extraction
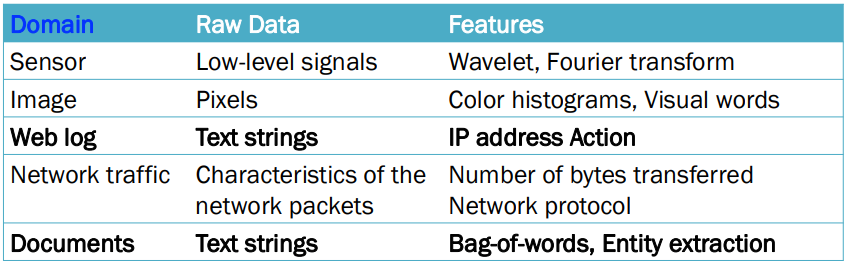
- Data Type Portability (데이터 유형 이식성)
- 데이터는 종종 heterogeneous(이질적)임
-> 데이터 내에 다양한 유형의 데이터가 섞여 있음
ex) 인구 통계 데이터 셋은 숫자(numeric) 및 혼합 속성(mixed attributes)을 모두 포함할 수 O
- 가능한 해결책
: 다양한 데이터 유형의 임의 조합을 처리할 수 있는 알고리즘 설계
-> 시간 소모가 크가 비현실적임
: 다양한 데이터 유형 간의 변환
-> 기존 도구를 활용한 처리
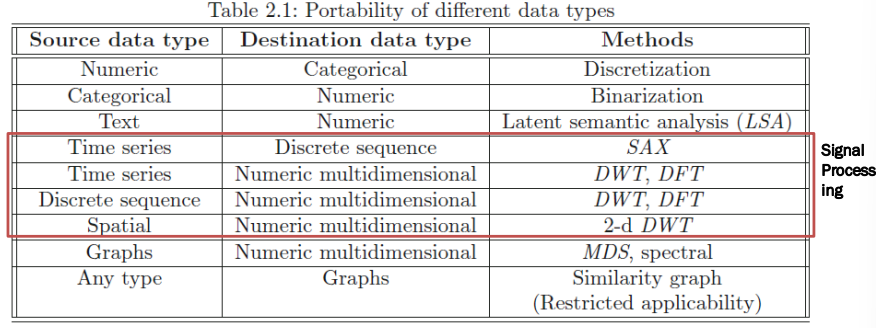
- Discrete Wavelet Transform (DWT)
- Discrete Fourier transform (DFT)
- Multidimensional Scaling (MDS)
- Numeric to Categorical Data: Discretization(구간화), 숫자형 -> 범주형
: 숫자 데이터가 포함된 범위를 𝜙개의 구간으로 나눔 (𝜙: 나눌 구간의 개수)
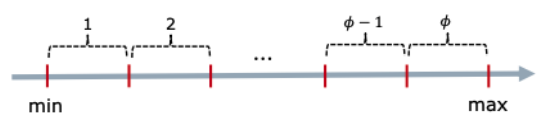
ex)
- Age Attribute
[0, 10], [21, 20], [21, 30] , ... - Salary
[0, 10000], [10001, 20000], [20001, 30000], ...
* Equi-width Ranges (동폭 구간)
-> 각 구간 [𝑎, 𝑏]는 𝑏 − 𝑎가 일정한 상수가 되도록 선택
-> 속성이 균일하게 분포되어 있다고 가정
-> 데이터가 균일하게 분포할 때 적합
* Equi-log Ranges (동로그 구간)
-> 각 구간 [𝑎, 𝑏]는 log 𝑏 − log 𝑎가 일정한 상수가 되도록 선택
-> 예를 들어, [1, 𝑎], [𝑎, 𝑎²], [𝑎², 𝑎³],...
-> 종종 지수 분포(exponential distribution)를 나타내는 속성에 사용됨
-> 지수적으로 증가하는 데이터에 적합
* Equi-depth Ranges (동심도 구간)
-> 각 구간에는 동일한 개수의 레코드가 포함됨
-> 각 구간에 동일한 수의 데이터 포인트가 들어가도록 구간을 설정하는 방법. 각 구간은 데이터의 개수를 기준으로 균등하게 나누어짐
-> Sorting(정렬) 및 선택 또는 분포를 가정
-> 데이터가 비균일하게 분포할 때 효과적
- Categorical to Numeric Data: Binarization(이진화), 범주형 -> 숫자형
1) 2개의 범주를 이진화하는 방법
-> 0,1 or -1, 1로 변환
2) 𝜙개의 범주를 이진화하는 방법
-> One-hot Encoding -> 각 범주는 𝜙차원의 지시 벡터(indecator vector)로 변환
-> 1의 위치가 해당 범주를 나타냄(나머지는 모두 0)
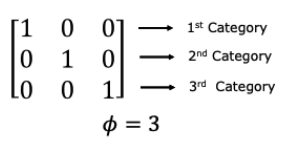
"빨강" → [1, 0, 0]
"파랑" → [0, 1, 0]
"초록" → [0, 0, 1]
- Text to Numeric Data
- 토큰화(Tokenization), 불용어 제거(Stop Word Removal), 어간 추출(Stemming), 가중치 부여(TF-IDF)
- 문서-단어 행렬(Document-Term Matrix)
- 차원 축소(Dimensionality Reduction)
- 잠재 의미 분석(Latent Semantic Analysis)
- Type X to Graphs for Similarity-Based Applications
- 점 집합 𝑂 = {𝑂1, … 𝑂𝑛}에 대한 이웃 그래프(neighborhood graph)
- 각 𝑂𝑖에 대해 하나의 노드가 정의됨
- 𝑂𝑖와 𝑂𝑗 사이의 거리 d(𝑂𝑖, 𝑂𝑗) ≤ 𝜖일 때, 𝑂𝑖와 𝑂𝑗 사이에 엣지가 존재함
-> 예: 엣지 𝑖,𝑗의 가중치 𝑤𝑖𝑗는 다음과 같이 정의될 수 있음

-> 가중치는 노드 간의 유사성 또는 거리를 나타냄 - 많은 변형이 존재함
2. Data Cleaning
- The Reason of Cleaning
- 데이터 수집 기술의 부정확성 (Inaccurate)
- 센서 – 수집 및 전송에서의 하드웨어 한계
- 광학 문자 인식 – 기술적 한계
- 음성 인식 데이터 – 기술적 한계
- 개인정보 보호 – 그로 인한 데이터 누락
- 수작업 오류 – 인간의 (타이핑) 오류
- 데이터 수집 비용이 비쌈 – 그로 인한 데이터 누락
- 의료 검사 – 모든 검사를 수행하지 않음
- Handling Missing Entries (누락된 항목 처리 방법)
- 누락된 항목이 있는 데이터 레코드를 삭제
-> 모든 데이터가 사라지면 어떻게 해야 할까? - 누락된 값을 추정하거나 대체(Impute)
-> 추가적인 오류가 발생할 수 있음
-> 특정 조건에서는 좋은 방법일 수 있음 (예: 행렬 완성) - 누락된 데이터를 처리할 수 있는 알고리즘 설계
- Handling Incorrect and Inconsistent Entries (잘못되고 일관되지 않은 항목 처리)
- Inconsistency detection, 일관성 감지
예: 전체 이름과 약어 - 도메인 지식
예: 나이는 800일 수 없음 - Data-centric methods, 데이터 중심 방법
- Scaling and Normalization
* Standardization, 표준화
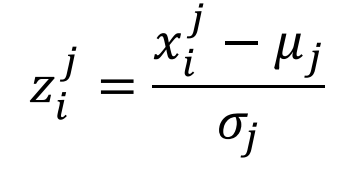
-> j번째 속성이 평균 𝜇𝑗와 표준편차 𝜎𝑗를 가질 때
* Min-Max Scaling
-> [0,1]로 매핑
-> 잡음에 민감
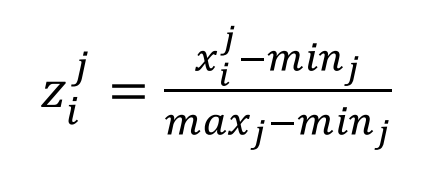
3. Data Reduction and Transformation, 데이터 축소와 변환
- Why do Reduction and Transformation?
<장점>
- 공간 복잡도 감소
- 시간 복잡도 감소
- 잡음 감소
- 숨겨진 구조를 드러냄
-> 예: manifold learning (고차원 데이터를 더 낮은 차원으로 효과적으로 축소하는 기법)
<단점>
- 정보 손실
- Sampling for Static Data
* Unbiased(Uniform) Sampling
: 단순 무작위 샘플링
- 교체 없는 샘플링
- 교체 있는 샘플링
-> 중복이 가능(많은 문제에서 선호X)
* Biased Sampling, 편향된 샘플링
- 데이터의 일부를 의도적으로 강조
- ex) 시간 감쇠 편향
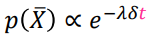
(더 최근 기록에 더 높은 확률 부여)
* Stratified Sampling, 층화 샘플링
: 데이터를 여러 개의 층으로 분할 후 각 층에서 샘플링
: 층화 샘플링은 데이터를 두 개 이상의 그룹(층)으로 나누고, 각 그룹에서 독립적으로 샘플을 추출하는 방법
-> 주로 데이터가 불균형하게 분포되어 있을 때, 특정 그룹(층)이 과소 표본(undersampled)되거나 과대 표본(oversampled)되는 문제를 방지하기 위해 사용
< Example>
: 10000명의 사람 중 100명의 백만장자가 있음
- 편향되지 않은 샘플링으로 100명을 추출
-> 기대값으로는 한 명의 백만장자가 샘플링될 것임
-> 실제로는 백만장자가 샘플링되지 않을 수도 있음 - 층화 샘플링
-> 백만장자와 비백만장자를 각각의 층으로 나눔
-> 100명의 백만장자 중 1명을 편향되지 않게 샘플링
-> 나머지 사람들 중 99명을 편향되지 않게 샘플링
- Reservoir(저수지) Sampling for Data Streams
: 새로운 데이터가 도착할 때 샘플을 갱신하는 방법
-
상황
: 데이터가 순차적으로 도착함
: 이를 균일하게 샘플링하고자 함
-> k개의 데이터를 저장할 수 있는 저수지가 있음 -
알고리즘
: 처음 k개의 데이터는 유지됨
: n번째 데이터를 k/n 의 확률로 삽입
: n번째 데이터가 삽입되면, 기존의 k개 데이터 중 하나를 균일하게 선택하여 삭제
- Feature Subset Selection
- 비지도 학습의 성능(ex. clustering)을 사용하여 특성 선택을 안내
- 지도 학습의 성능(ex. classification)을 사용하여 특성 선택을 안내
