저번시간 cctv 데이터셋에 이어 범죄현황 데이터셋을 다루는 시간이 왔다..!!
범죄 관련 데이터도 매우매우 궁금하기 때문에 눈을 크게 뜨고 볼 예정이다.
범죄 관련 데이터 쪽으로 일을 하고 싶으면 ... 어떻게 해야 하지...? 보안회사에 가야하나
경찰청에 들어가야 한........나......갈 순 있는건가..... 아무튼 일단 해보자
Analysis seoul crime
import numpy as np
import pandas as pd# 데이터 읽기
crime_raw_data = pd.read_csv('../data/02. crime_in_Seoul.csv', thousands="," , encoding='euc-kr')
crime_raw_data.head()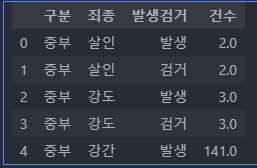
# 데이터 개요 확인
crime_raw_data.info()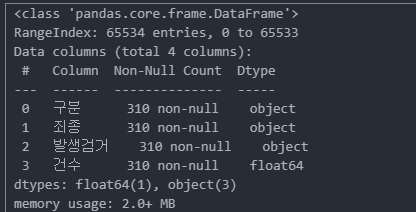
- info() : 데이터의 개요 확인하기
- rangeindex가 65534 인데, 310개로 나온다. (문제점)
#unique() 를 통해 '죄종' 이라는 컬럼의 값을 확인한다.
crime_raw_data['죄종'].unique()결과)
array(['살인', '강도', '강간', '절도', '폭력', nan], dtype=object- 특정 컬럼에서 unique 값을 조사.
- nan 값이 들어가 있다.
#null 값확인
crime_raw_data[crime_raw_data['죄종'].isnull()].head()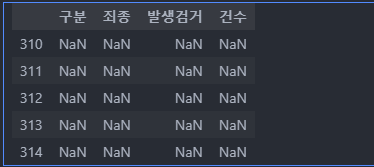
#null이 아닌 값을 다시 원본데이터에 저장한다.
crime_raw_data = crime_raw_data[crime_raw_data['죄종'].notnull()]후에 확인
crime_raw_data.info()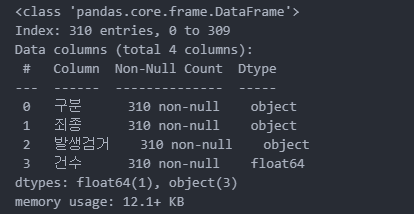
index 수가 310개로 정상적임을 확인 할 수 있다.
crime_raw_data.head()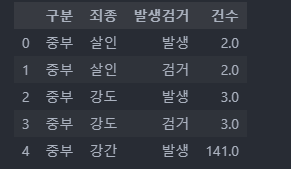
crime_raw_data.tail()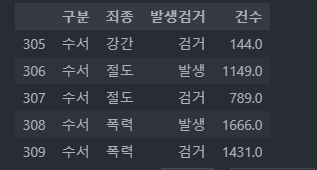
맨 위, 맨 아래 각각 5개의 데이터를 확인하니 문제가 없이 잘 출력이 된다.
오늘은 데이터의 결측치를 확인하는 방법과 결측치가 없는 데이터를 추려내는 방법을
배웠다. 그리고 데이터 개수를 체크하고, 데이터타입을 확인하는 방법도 배웠다.
info() 함수와 unique() 함수를 잘 기억해 두어야겠다.

Analytics Engineer