정밀도와 재현율 (precision & recall) 의 트레이드오프

와인 데이터셋 불러오기
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine =pd.read_csv(red_url, sep=';')
white_wine =pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade > 5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']데이터 나누기
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=13)학습과 예측값 및 정확도
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
lr = LogisticRegression(solver='liblinear', random_state=13)
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print('Train Acc:', accuracy_score(y_train, y_pred_tr))
print('Test Acc: ', accuracy_score(y_test, y_pred_test))Train Acc: 0.7425437752549547
Test Acc: 0.7438461538461538
classification_report - y_test
from sklearn.metrics import classification_report
print(classification_report(y_test, lr.predict(X_test))) precision recall f1-score support
0.0 0.68 0.58 0.62 477
1.0 0.77 0.84 0.81 823
accuracy 0.74 1300 macro avg 0.73 0.71 0.71 1300
weighted avg 0.74 0.74 0.74 1300
precision, recall, threshold 시각화
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
plt.figure(figsize=(10,8))
pred = lr.predict_proba(X_test)[:, 1]
precisions, recalls, thresholds = precision_recall_curve(y_test, pred)
plt.plot(thresholds, precisions[:len(thresholds)], label='precisions')
plt.plot(thresholds, recalls[:len(thresholds)], label='recalls')
plt.grid()
plt.legend()
plt.show()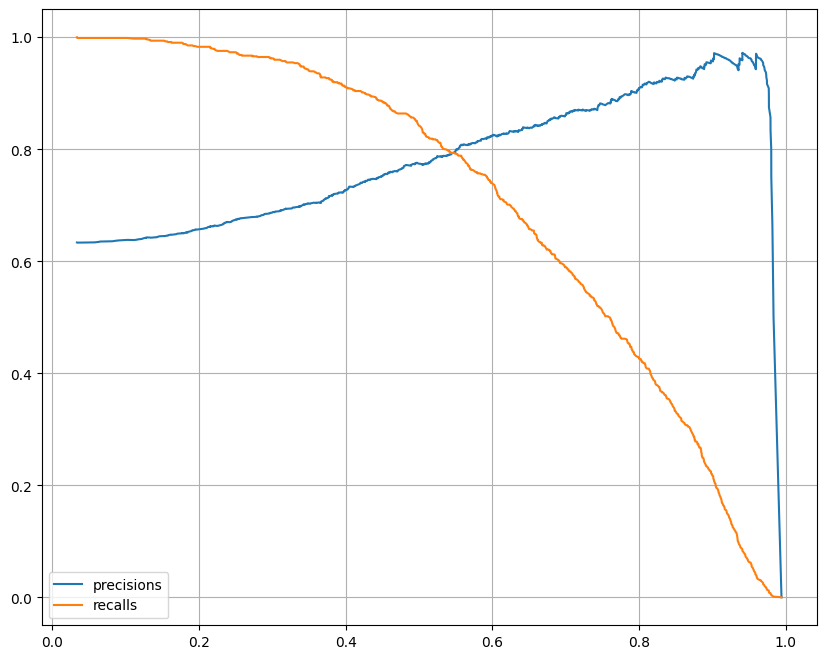
# thredshold = 0.5
pred_proba = lr.predict_proba(X_test)
pred_proba[:3]array([[0.40489885, 0.59510115],
[0.51046968, 0.48953032],
[0.10197579, 0.89802421]])
concatenate
import numpy as np
np.concatenate([pred_proba, y_pred_test.reshape(-1,1)], axis=1)
array([[0.40489885, 0.59510115, 1. ],
[0.51046968, 0.48953032, 0. ],
[0.10197579, 0.89802421, 1. ],
...,
[0.22543326, 0.77456674, 1. ],
[0.67255092, 0.32744908, 0. ],
[0.31413623, 0.68586377, 1. ]])
y_pred_testarray([1., 0., 1., ..., 1., 0., 1.])
y_pred_test.reshape(-1,1)array([[1.],
[0.],
[1.],
...,
[1.],
[0.],
[1.]])
threshold 바꿔보기 - Binarizer
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.6).fit(pred_proba)
pred_bin = binarizer.transform(pred_proba)[:,1]
pred_binarray([0., 0., 1., ..., 1., 0., 1.])
from sklearn.metrics import classification_report
print(classification_report(y_test, pred_bin))[0.5] 일 때
precision recall f1-score support
0.0 0.68 0.58 0.62 477
1.0 0.77 0.84 0.81 823
accuracy 0.74 1300 macro avg 0.73 0.71 0.71 1300
weighted avg 0.74 0.74 0.74 1300
[0.6] 일 때
precision recall f1-score support
0.0 0.62 0.73 0.67 477
1.0 0.82 0.74 0.78 823
accuracy 0.74 1300 macro avg 0.72 0.73 0.72 1300
weighted avg 0.75 0.74 0.74 1300
recall 이 향상 된 것을 볼 수 있다.
