데이터 탐색적 분석EDA- Titanic
먼저 모듈 하나를 다운 받고 시작한다.
pip install plotly_express
python 라이브러리에 데이터 시각화 모듈이다.
그런데 seaborn 을 사용하지 않고 왜 이걸 사용하지? 의문이 들었다.
어떤 시각화, 어떤 분석이 진행되냐에 따라서 선택적으로 사용하면 되는 것 같다.
Seaborn은 주로 정적 데이터 시각화에 사용되고, Plotly Express는 인터랙티브 데이터 시각화와 다양한 그래프 유형을 사용할 때 유용하다고 한다!
good!
이제 본론으로 들어가자
1. 타이타닉 데이터 불러오기
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
titanic_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/titanic.xls'
titanic = pd.read_excel(titanic_url)
titanic.head()
2. value_counts()
특정 피쳐의 value 값을 각각 카운트 해주는 함수이다.
titanic['survived'].value_counts()3. value_counts() 시각화해서 확인하기
titanic['survived'].value_counts().plot.pie(autopct='%1.2f%%')matplotlib 라이브러리를 활용해서 진행했다.
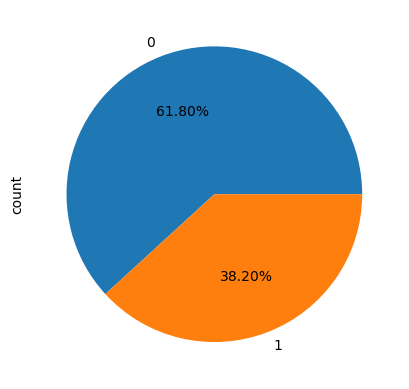
만약 pit() 괄호안을 비워두면 숫자는 뜨지 않는다. 좀 더 가시화하기위해서 소수점 2째자리까지 나오도록 해주었다. 면적을 비교하면서도 수치를 정확히 주어 명확한 의사전달이 가능해 진다.
몇 가지 옵션을 더 추가해 보자.
4. 다양한 옵션들
1) shadow : 그림자 효과
2) explode : 구간의 섹션을 떨어트리는 거리
titanic['survived'].value_counts().plot.pie(autopct='%1.2f%%', shadow=True, explode=[0, 0.05])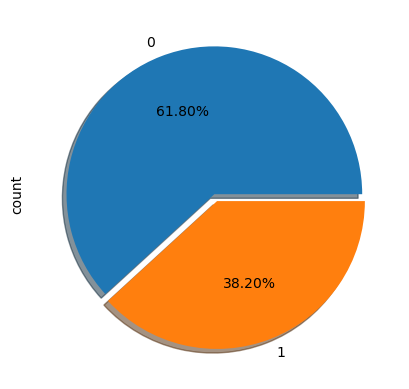
5. 그림 2개 한 번에 그리기
f, ax = plt.subplots(1,2, figsize=(18,8)) # 1행 2열의 그래프를 만들고, 전체 그래프의 크기를 가로 18인치, 세로 8인치로 설정
f, ax = plt.subplots(1,2, figsize=(18,8)) # 1행 2열의 그래프를 만들고, 전체 그래프의 크기를 가로 18인치, 세로 8인치로 설정
titanic['survived'].value_counts().plot.pie(ax=ax[0], autopct='%1.2f%%', shadow=True, explode=[0, 0.05])
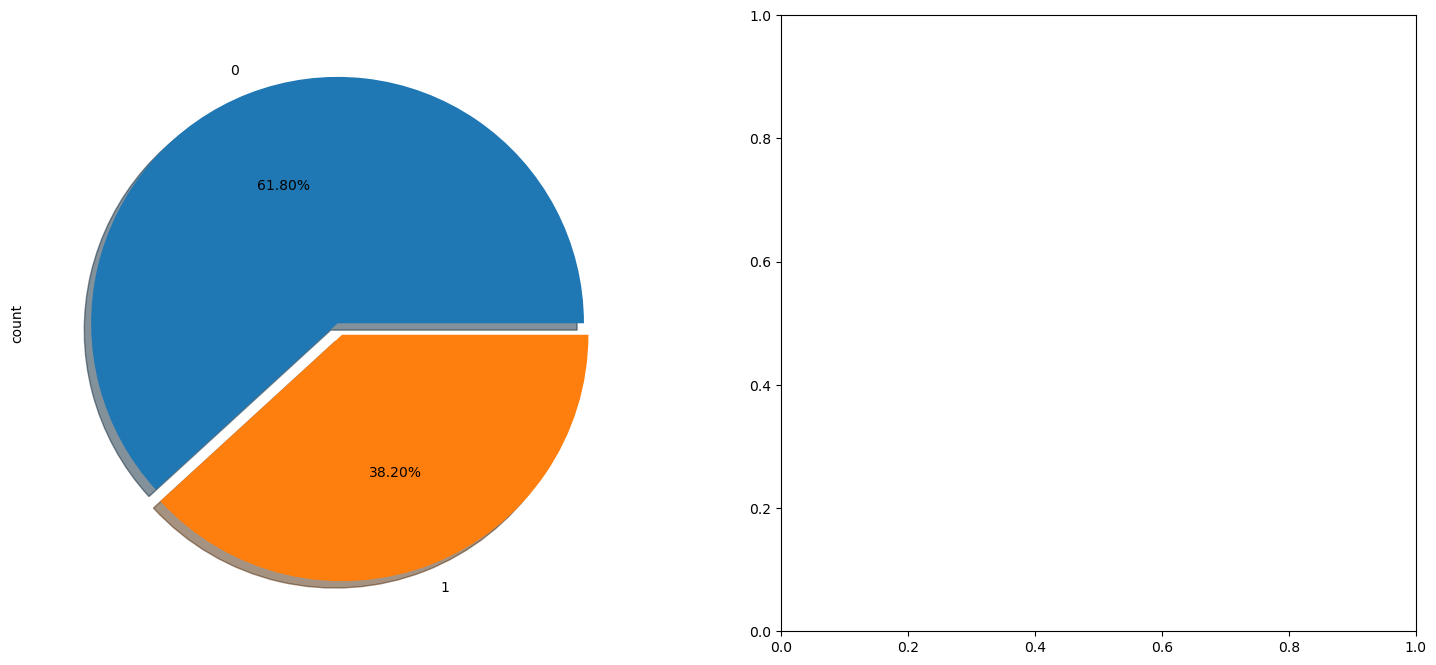
6. 오른쪽에 seaborn 으로 countplot 그려주기
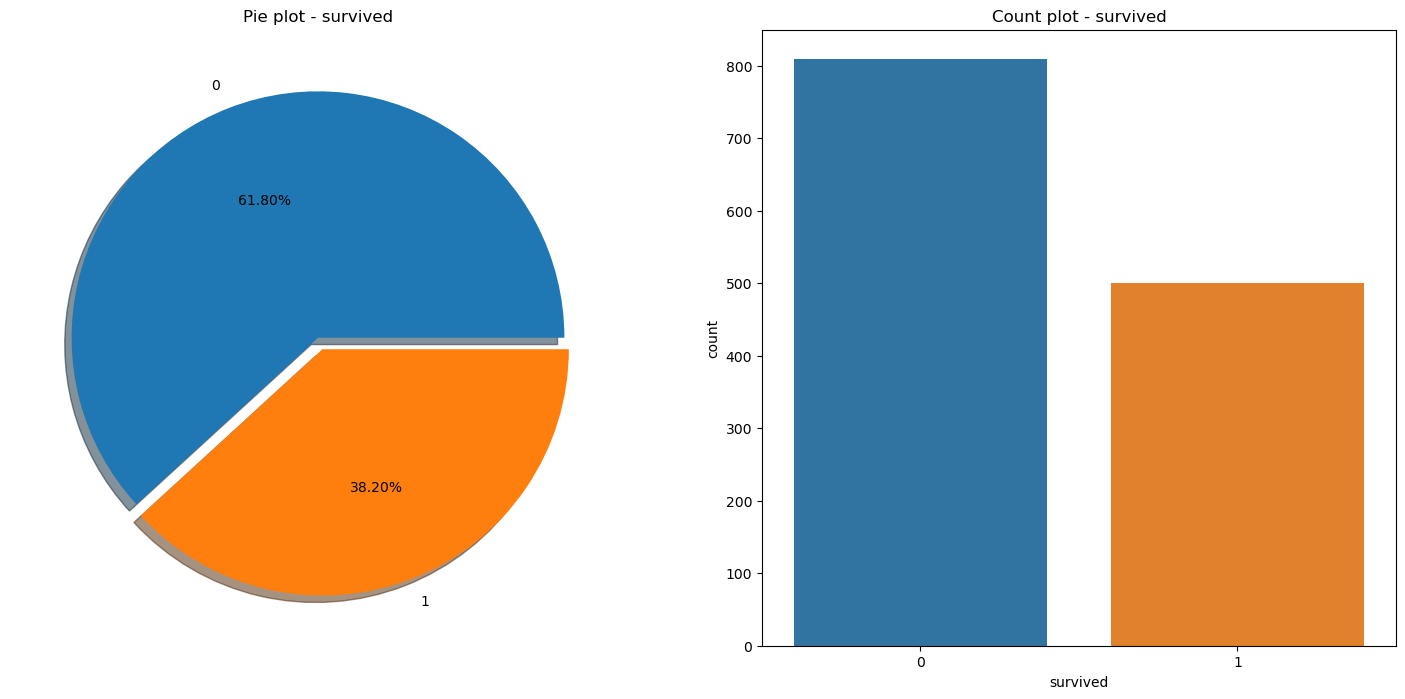
f, ax = plt.subplots(1,2, figsize=(18,8)) # 1행 2열의 그래프를 만들고, 전체 그래프의 크기를 가로 18인치, 세로 8인치로 설정
titanic['survived'].value_counts().plot.pie(ax=ax[0], autopct='%1.2f%%', shadow=True, explode=[0, 0.05])
ax[0].set_title('Pie plot - survived')
ax[0].set_ylabel('')
sns.countplot(x='survived', data=titanic, ax=ax[1])
ax[1].set_title('Count plot - survived')
7. 성별에 따른 생존현황
# 성별에 따른 생존 현황
f, ax = plt.subplots(1,2, figsize=(18,8)) # 1행 2열의 그래프를 만들고, 전체 그래프의 크기를 가로 18인치, 세로 8인치로 설정
sns.countplot(x='sex', data=titanic, ax=ax[0])
ax[0].set_title('Count of passengers of sex')
ax[0].set_ylabel('')
sns.countplot(x='sex', data=titanic, hue='survived' ,ax=ax[1])
ax[1].set_title('sex : survived')
plt.show()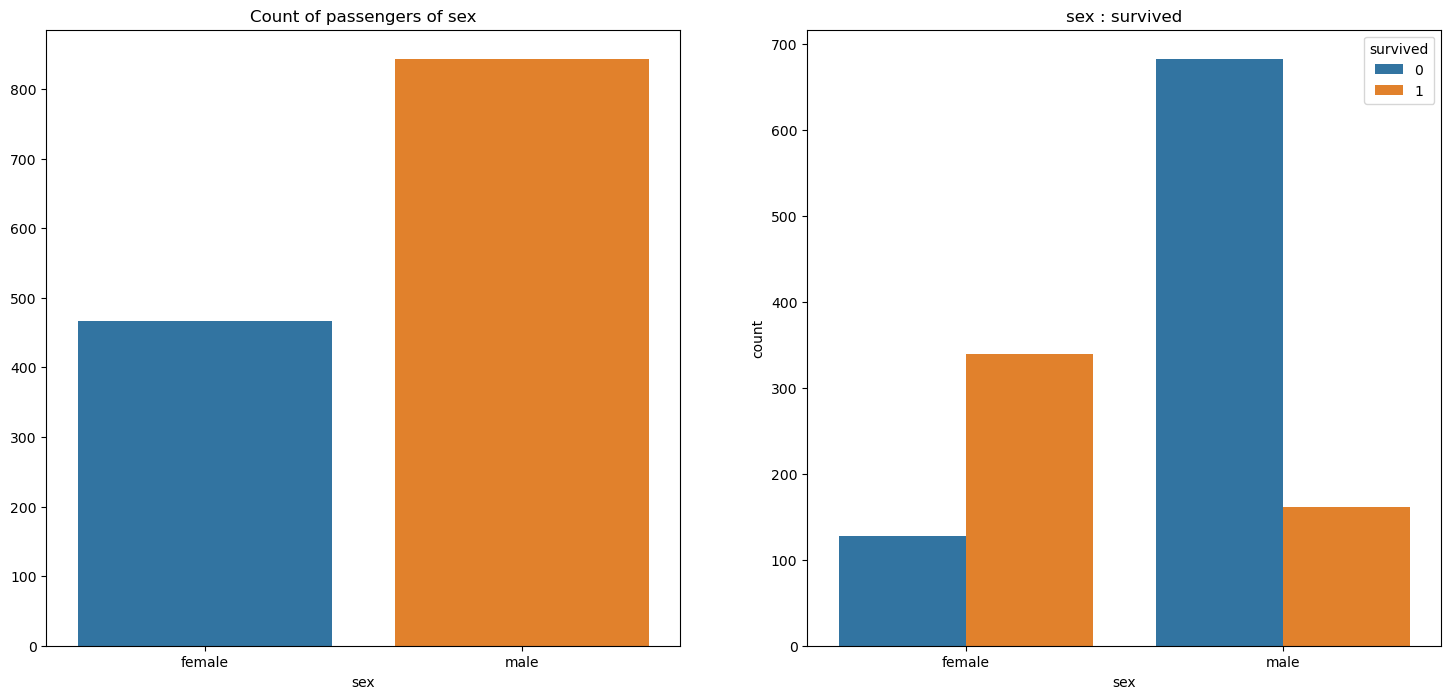
인사이트 : 남성의 생존 가능성이 더 낮다

Analytics Engineer