타이타닉 생존자 분석 EDA2
1. 경제력 대비 생존률
pd.crosstab(titanic['pclass'], titanic['survived'], margins=True)pclass 는 객실등급을 뜻한다.
crosstab 은 데이터 분석과 통계에서 주로 사용되는 함수라고 한다. 2개의 범주형 변수를 비교할 수 있어서 pclass 범주형 변수와 survived 범주형 변수를 넣어서 사용해 보겠다.
| survived | 0 | 1 | All |
|---|---|---|---|
| pclass | |||
| 1 | 123 | 200 | 323 |
| 2 | 158 | 119 | 277 |
| 3 | 528 | 181 | 709 |
| All | 809 | 500 | 1309 |
1등실의 생존 가능성이 매우 높다.
그런데 여성의 생존률도 높다.
그럼, 1등실에는 여성이 많이 타고 있었나?
2. 객실등급별 각 성별의 나이분포 확인
(FacetGrid)
grid = sns.FacetGrid(titanic, row='pclass', col='sex', height=4, aspect=2)
grid.map(plt.hist, 'age', alpha=0.8, bins=20)
grid.add_legend()
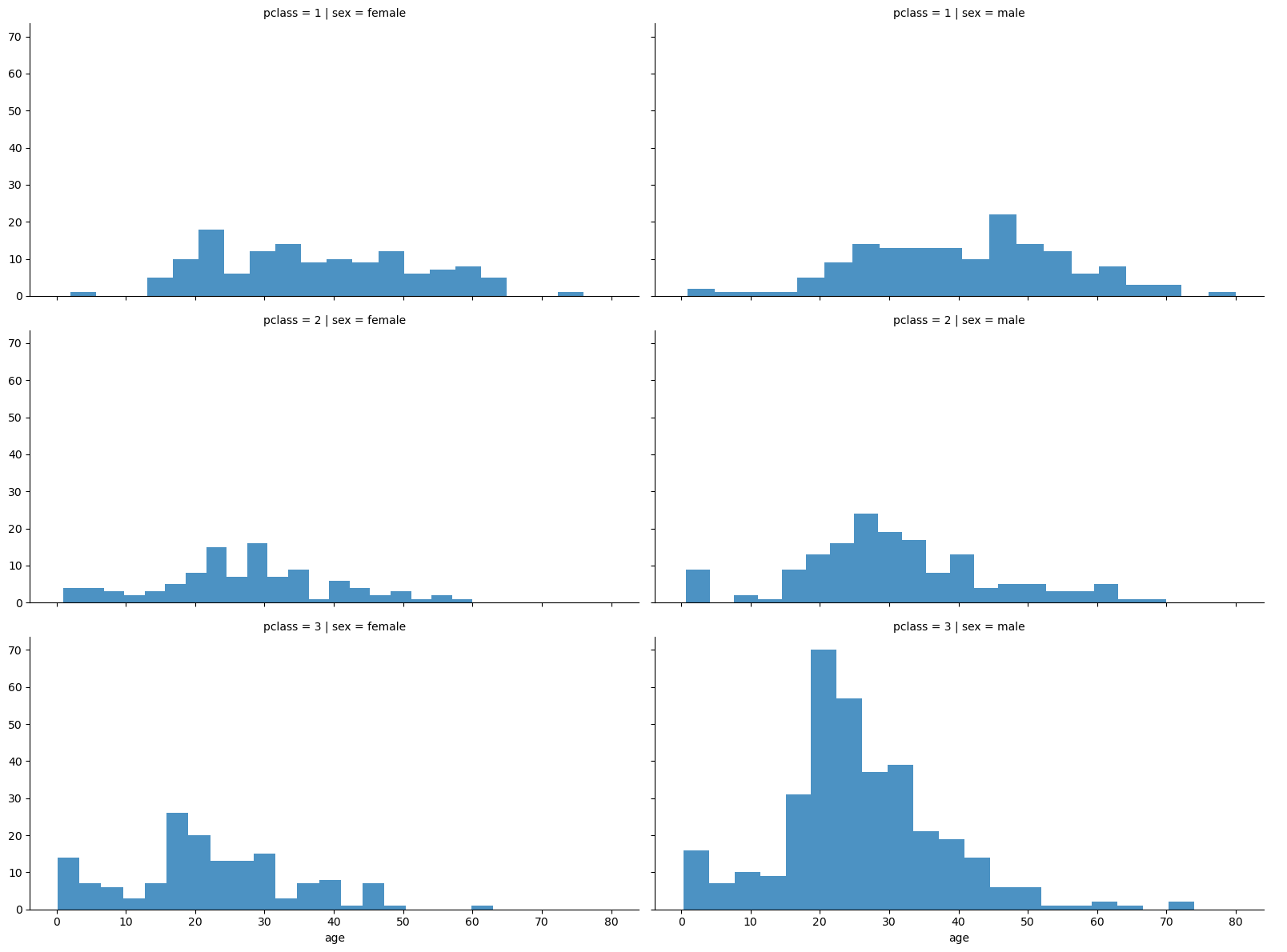
FacetGrid 가 하는 일은 이것 또한 시각화 도구인데 seaborn 에서 그림을 여러 개의 하위 그래프로 분할하여 복잡한 데이터 패턴을 쉽게 분석하고 시각화 할 수 있도록 도와주는 도구라고 한다.
3등실에는 남성이 많았다 - 특히 20대 남성
2등실은 남여 모두 갓난아기들이 1등실에 많다.
3. 나이별 승객 현황
import plotly_express as px
fig = px.histogram(titanic, x='age')
fig.show()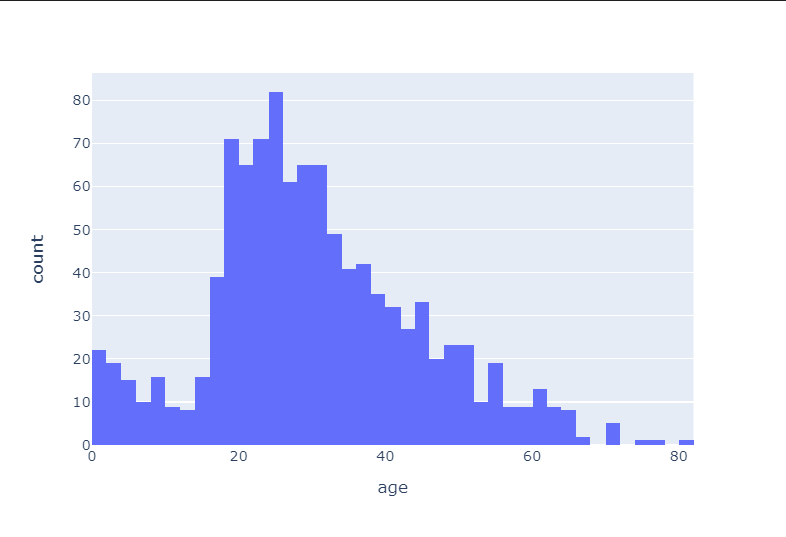
아이들과 2~30대가 꽤 많았다.
4. 등실별 생존률
grid = sns.FacetGrid(titanic, row='pclass', col='survived', height=4, aspect=2)
grid.map(plt.hist, 'age', alpha=0.8, bins=20)
grid.add_legend()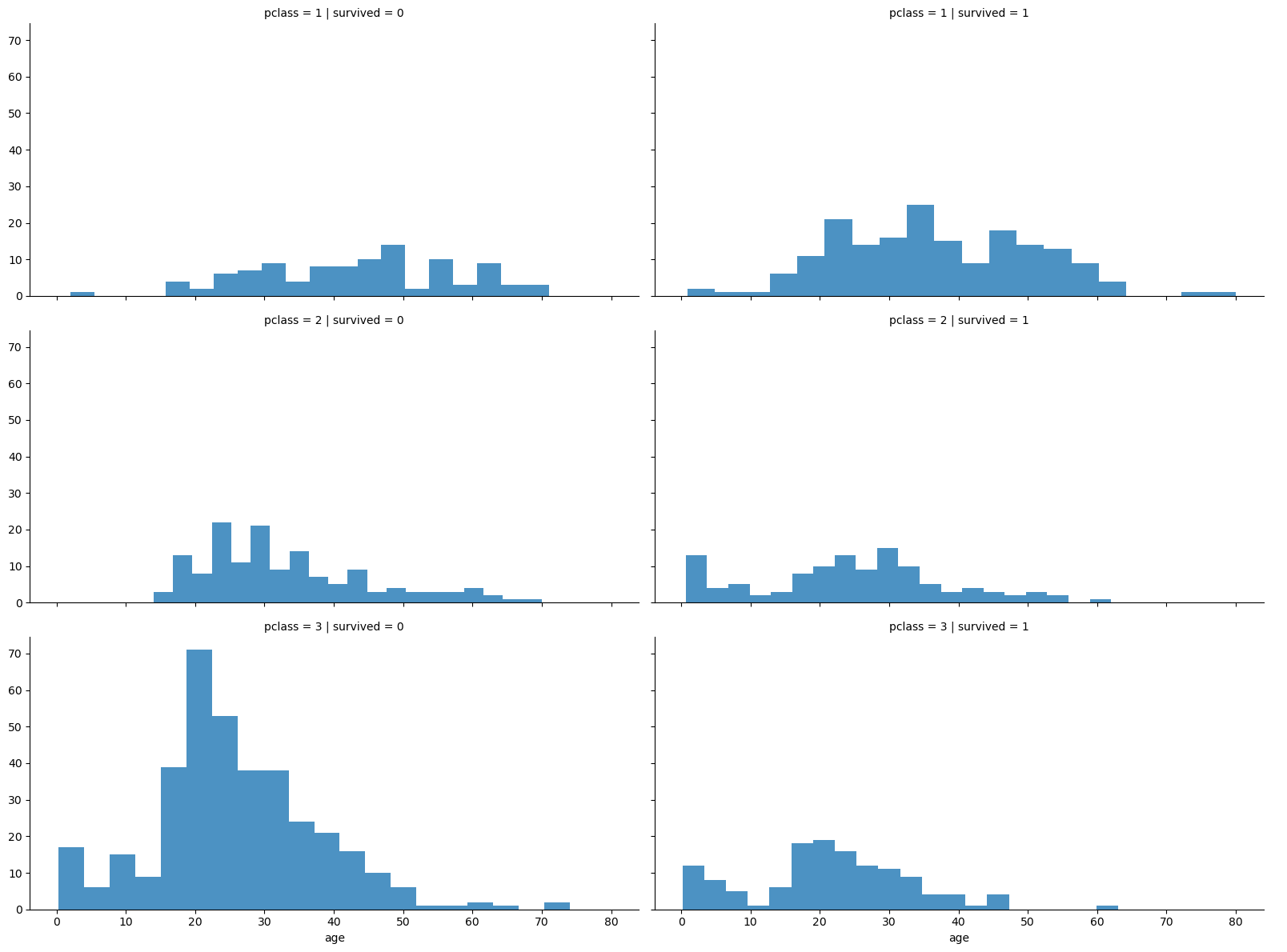
3등실 쪽은 2~30대의 많은 사람들의 사망률이 높다.
5. 나이별 등급 피쳐 생성
titanic['age_cat'] = pd.cut(titanic['age'], bins=[0,7, 15,30,60,100] ,
include_lowest=True,
labels=['baby', 'teenage', 'young', 'adult', 'old'])
titanic.head()[생성된 feature]

나이, 성별, 등급별 생존자 수를 한 번에 파악할 수 있을까?
plt.figure(figsize=(12,4))
plt.subplot(131)
sns.barplot(x='pclass', y='survived', data=titanic)
plt.subplot(132)
sns.barplot(x='age_cat', y='survived', data=titanic)
plt.subplot(133)
sns.barplot(x='sex', y='survived', data=titanic)
plt.subplots_adjust(top=1, bottom=0.1, left=0.1, right=1, hspace=0.5, wspace=0.5)
plt.show()
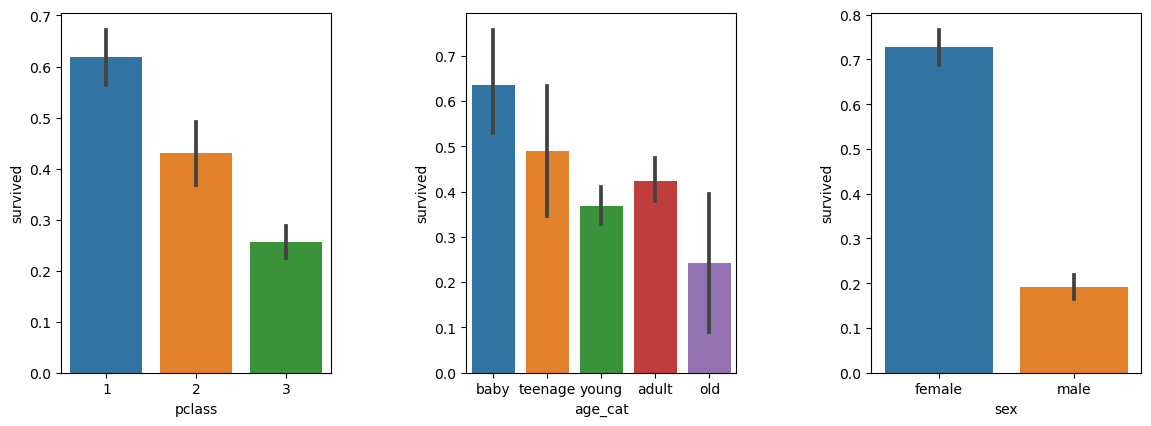
결론
1. 1등실에 탄 사람들의 생존율이 높았다.
2. 나이대는 15세~30세 , 60~100세 사이의 사람들이 살아남지 못했다.
3. 여성의 생존율이 높았다.
- 1등실, 여성, 0~15세와 30~60세 사람의 생존율이 높았던 것으로 볼 수 있다.

Analytics Engineer