
1. 결정 트리 모델
1.1. 개요

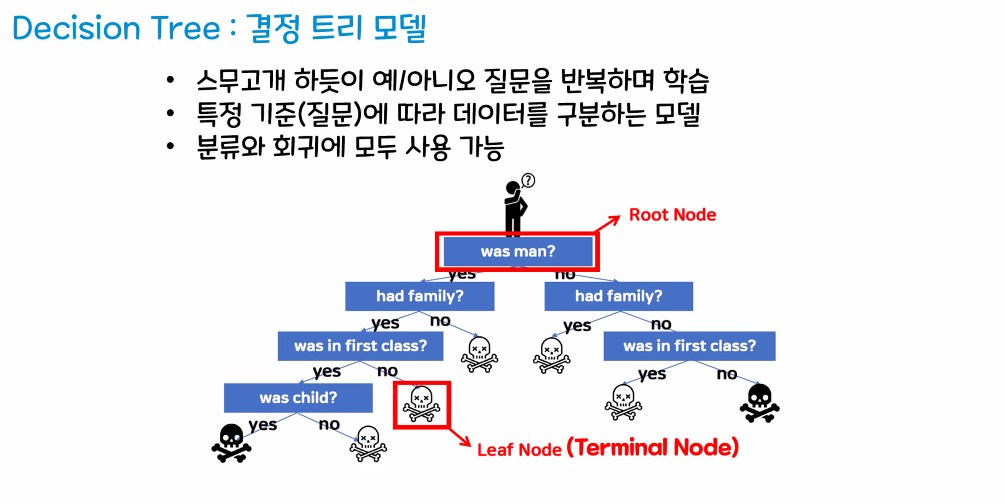
1.2. 결정 트리 모델
- 정의
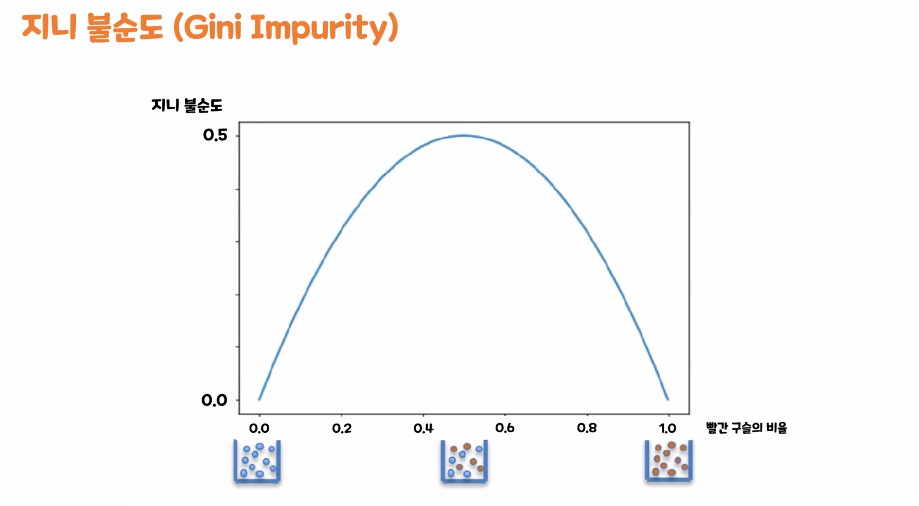
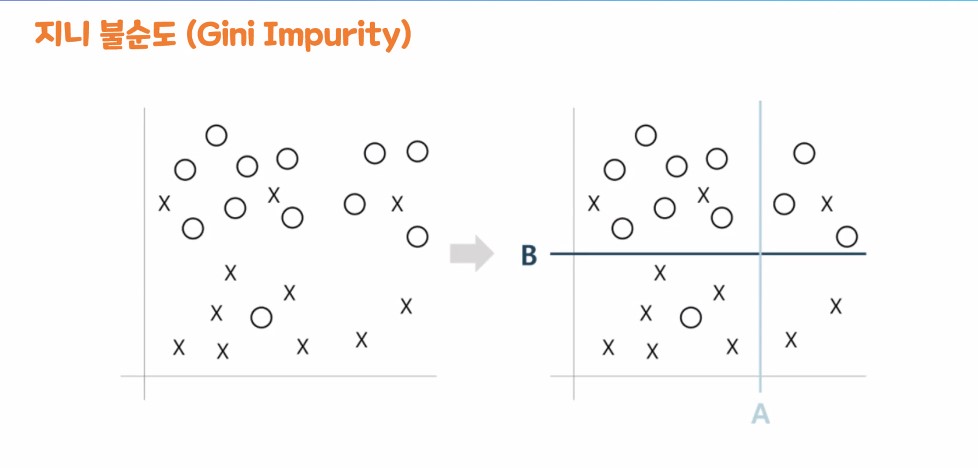
- 지니 불순도

|
|
- 엔트로피

- 의사결정 방향
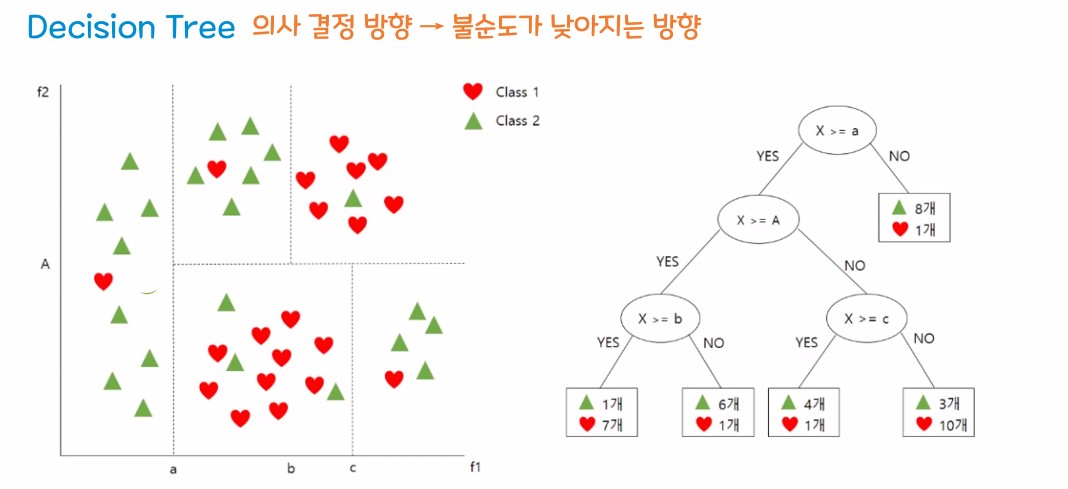
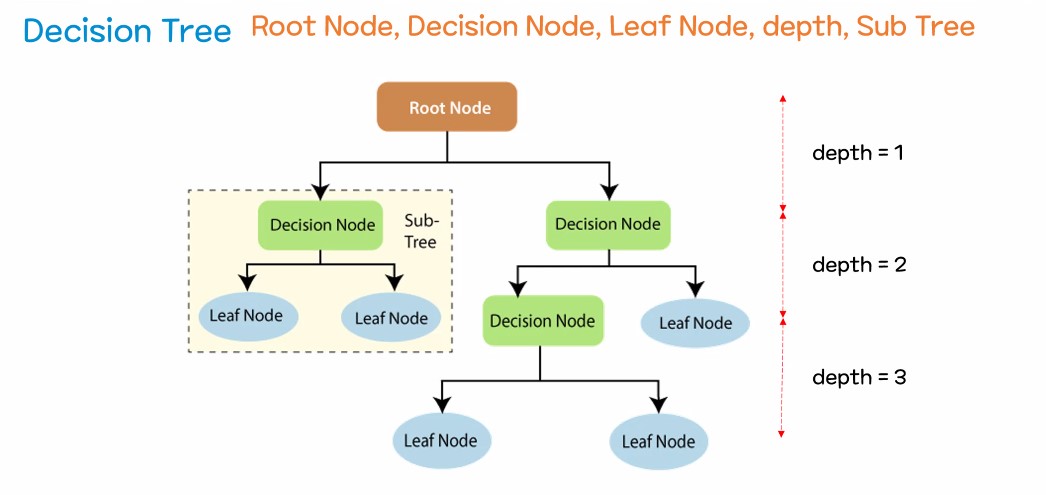


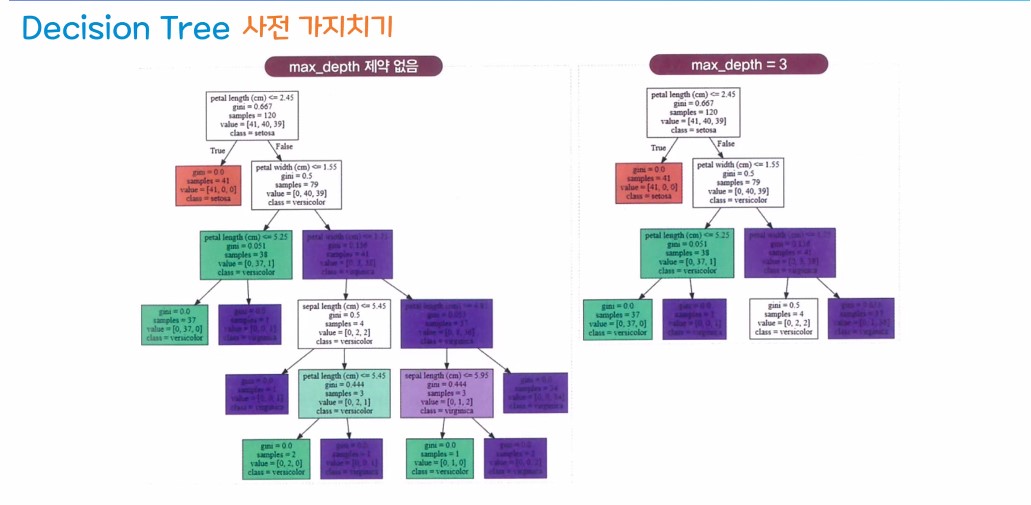
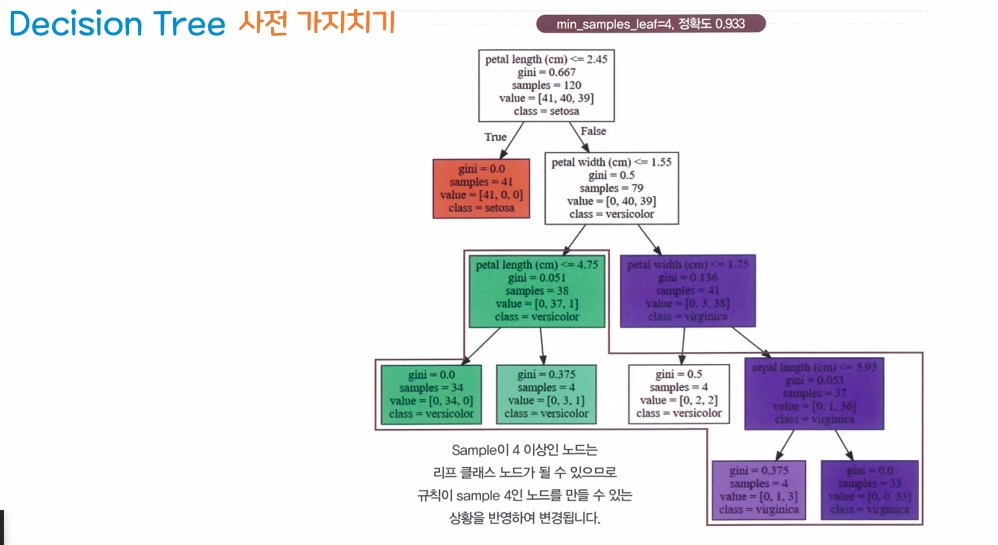

2. 결정 트리 모델을 이용한 실습
2.1. 목표설정
- 버섯의 특정을 활용해서 독버섯인지 식용버섯인지 가려내는것
- 특성 선택을 통해서 중요한 특성을 가려내보자.
# 필요한 라이브러리 import(pandas, numpy, matplotib, train_test_split)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# 데이터 셋 불러오기(pd에 있는 함수를 이용해서 데이터 불러오기)
data = pd.read_csv("./data/mushroom.csv")
data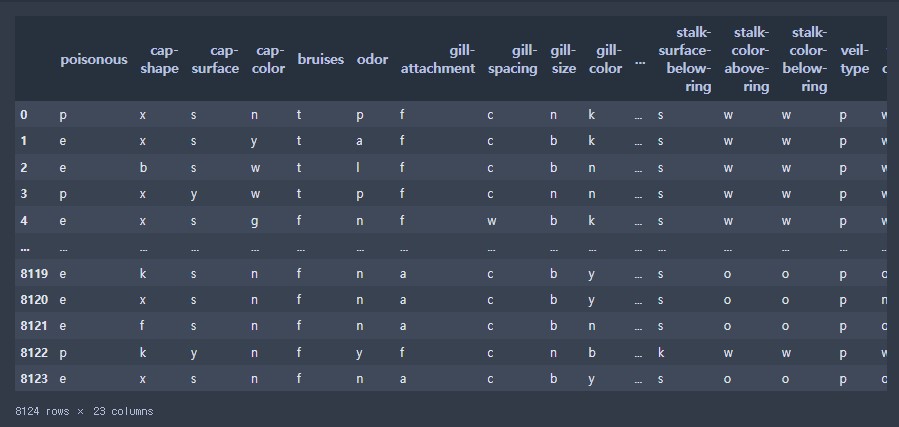
- 데이터 확인하기( shape )
# 데이터 확인하기( shape )
data.shape(8124, 23)
- 데이터 결측치 확인화기( info() )
# 데이터 결측치 확인화기( info() )
data.info()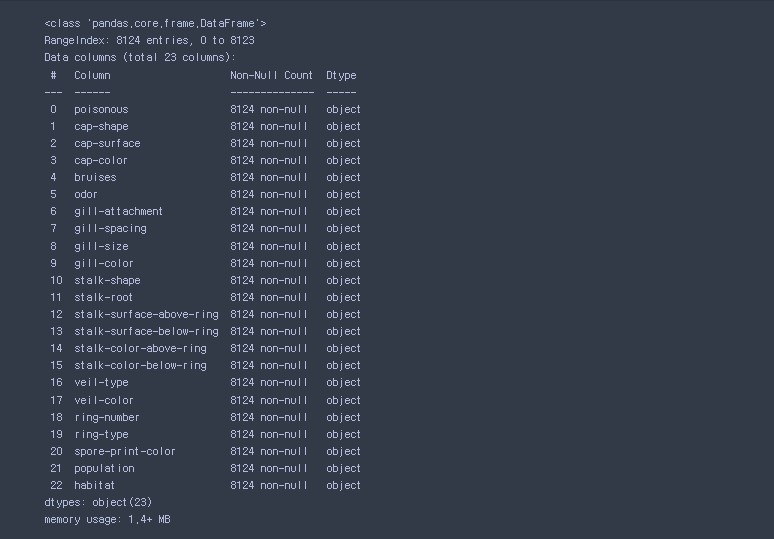
- 버섯 데이터 이미지 (데이터 셋)

# 결측치 없었다 ! 깔끔한 데이터
# 정답 데이터 - poisonous(p / e)
# 내부의 데이터 타입 - 문자 타입
# 기출 통계 확인해보기 - describe()
data.describe()
# 현재 기술 통계는 문자형 데이터를 표기하는 방식
# count - 데이터의 갯수
# unique - 데이터의 고유값 갯수 (중복을 없앤 데이터의 종류 갯수)
# top - 가장 갯수가 많은 데이터의 고유값
# freq - 빈도 수(가장 많은 고유값의 갯수)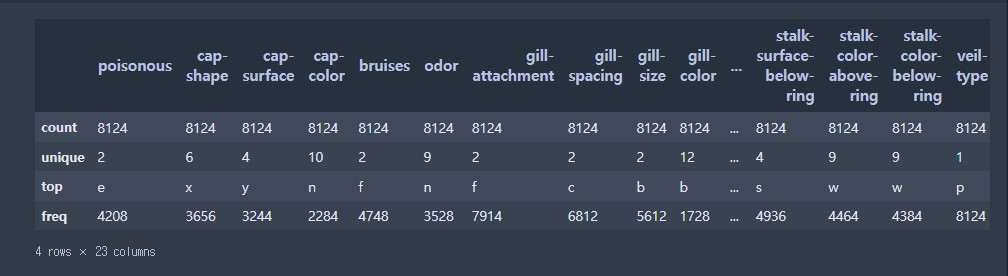
2.2. 데이터 확보
- 위에서 진행 / 별도 데이터 제공
2.3. 데이터 전처리
- 여기까지는 학습용 데이터라 결측치, 이상치 전처리는 필요 없다.
- 추후 인코딩 작업을 진행할 예정
- encoding : 범주형 -> 수치형 / binning : 수치형 -> 범주형
2.4. 탐색적 데이터 분석 (EDA)
- 데이터를 시각화해서 정보를 획득하자!
# 새로운 시각화 라이브러리 등장!
# seaborn - pandas와 호환성이 좋고 matplotlib 보다 조금 더 깔끔한 느낌
import seaborn as sns
# sns.countplot() - matplotlib의 bar 차트와 동일한 차트
sns.countplot(data = data , # 데이터 프레임 지정
x = 'cap-shape' , # x축에 들어갈 컬럼 설정
hue = 'poisonous' # hue : 해당 컬럼의 유니크 값이 들어가서 개수를 세어주고 출력을 진행
# unique 값에 대한 각각의 bar차트가 표시되고 자동으로 범례도 출력
)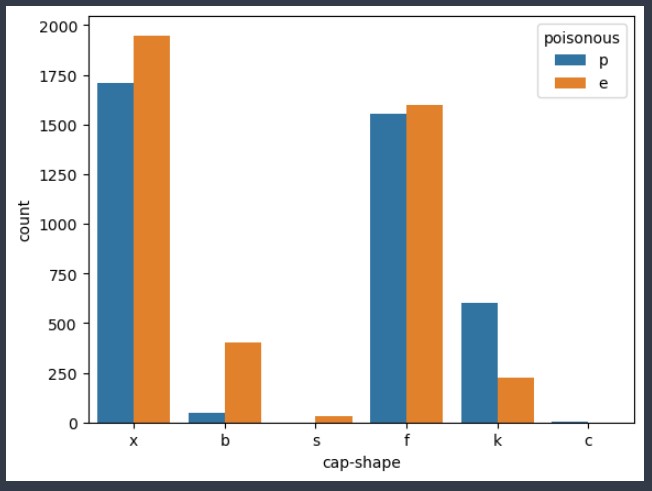
- 우리가 지금 보고 있는 데이터는 갓 모양과 독성 유무를 함께 보고있다.
- 갓 모양이 s : 모두 식용 버섯
- 갓 모양이 c : 모두 독 버섯
- 갓 모양이 b : 식용 버섯일 확률이 높다
- 갓 모양이 k : 독 버섯일 확률이 높다
- 갓 모양이 x / f : 독 버섯과 식용 버섯의 비율이 비슷하다
# sns.countplot() - matplotlib의 bar 차트와 동일한 차트
sns.countplot(data = data , # 데이터 프레임 지정
x = 'cap-surface' , # x축에 들어갈 컬럼 설정
hue = 'poisonous' # hue : 해당 컬럼의 유니크 값이 들어가서 개수를 세어주고 출력을 진행
# unique 값에 대한 각각의 bar차트가 표시되고 자동으로 범례도 출력
)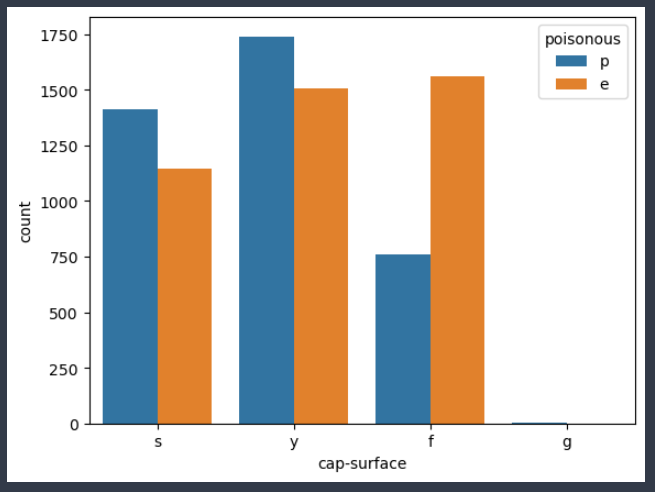
- 우리가 지금 보고있는 데이터는 갓 표면과 독성 유무를 함께 보고 있다.
- 갓 표면이 g : 모두 독 버섯
- 갓 표면이 f : 식용 가능성 높음
- 갓 표면이 s / y : 독 버섯 가능성이 높음
2.5. 모델링
- 문제와 정답 분류
- 인코딩 진행
- 훈련 셋, 평가 셋 분리
data['poisonous']
data.loc[:,'cap-shape':]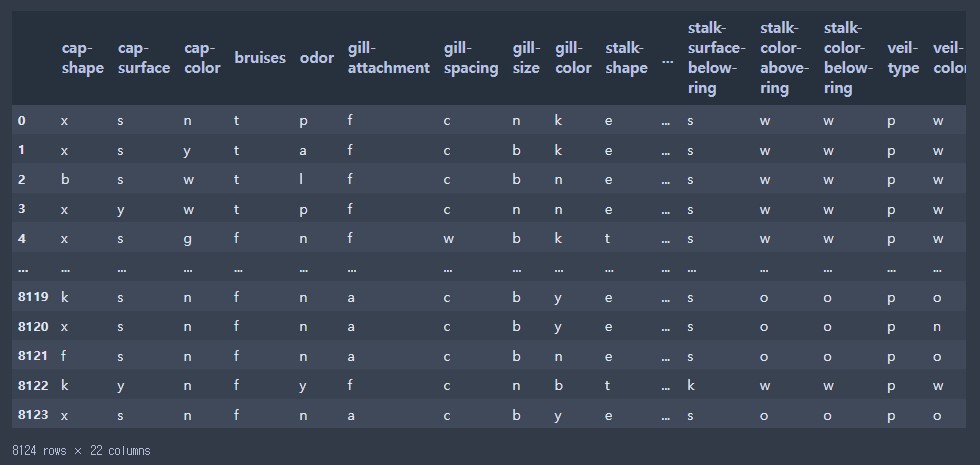
# y = poisonous
# X = poisonous를 제외한 모든 데이터
# loc[] 인덱서를 이용하는 방법 ( 3가지중 하나 사용! )
# 방법 1) X = data.loc[ 행 범위 , 열 범위 ] - comma를 기준으로 행과 열을 나눠준다.
# comma 앞은 행 / comma 뒤는 열
X = data.loc[:,'cap-shape':]
y = data['poisonous']
# 방법 2) X = data.loc[ 행 범위 , 열 범위 ] - comma를 기준으로 행과 열을 나눠준다.
# comma 앞은 행 / comma 뒤는 열
X = data.iloc[:, 1:]
y = data.iloc[0]
# 방법 3) 발상의 전환(drop)
# comma 앞은 행 / comma 뒤는 열
X = data.drop('poisonous', axis = 1):
y = data.poisonous
X.shape, y.shape((8124, 22), (8124,))
2.5.2 인코딩 작업 진행
- 머신 러닝 모델은 내부의 연산을 통해 값을 예측하는 구조
- 연산을 하기 위해서는 숫자 데이터 필요
- 현재 우리가 가지고 있는 버섯 데이터는 무슨 데이터? -> 문자 데이터(연산 불가능)
- 연산을 할 수 있도록 숫자로 바꿔줘야 한다(인코딩)# 1. 라벨 인코딩
# 각각의 유니크 값에 0 부터 순서대로 번호를 매개는 방식
# 숫자의 크고 작은에 대한 특성이 자동으로 반영
# 중요) 회귀와 같이 연속된 숫자를 다루는 부분에서는 사용하면 안된다.
# 숫자에 따른 순서나 중요도로 인식될 가능성이 있어서 주의해야 한다.
# 라벨 인코딩 예시
# 데이터 유니크 값 확인
X['cap-shape'].unique()
array(['x', 'b', 's', 'f', 'k', 'c'], dtype=object)
# 라벨 인코딩 진행하기 (딕셔너리 구조로 대체함)
X['cap-shape'].map({'x':0, 'b':1, 's':2, 'f':3, 'k':4, 'c':5})
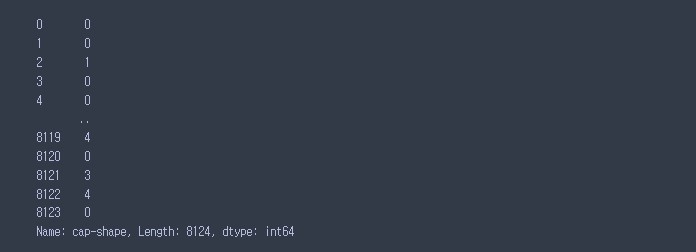
# 사이킷 런의 Labelencoder()를 이용해서 라벨 인코딩을 진행할 수 있음 !
from sklearn.preprocessing import LabelEncoder
label = LabelEncoder()
label.fit(X['cap-shape'])
X_label = label.transform(X['cap-shape'])
X_labelarray([5, 5, 0, ..., 2, 3, 5])
# 2. 원 핫 인코딩(더미 변수화)
# 모든 데이터를 0과 1로 변환을 해준다.
# 컴퓨터는 2진법을 모든 데이터를 처리하기 때문에 수치에 대한 변화가 적용되는
# 라벨 인코딩 보다 직관적인 원 핫 인코딩을 주로 사용한다.
# pd.get_dummies() : 더미 변수화 / 원 핫 인코딩 진행
X_one_hot = pd.get_dummies(X)
X_one_hot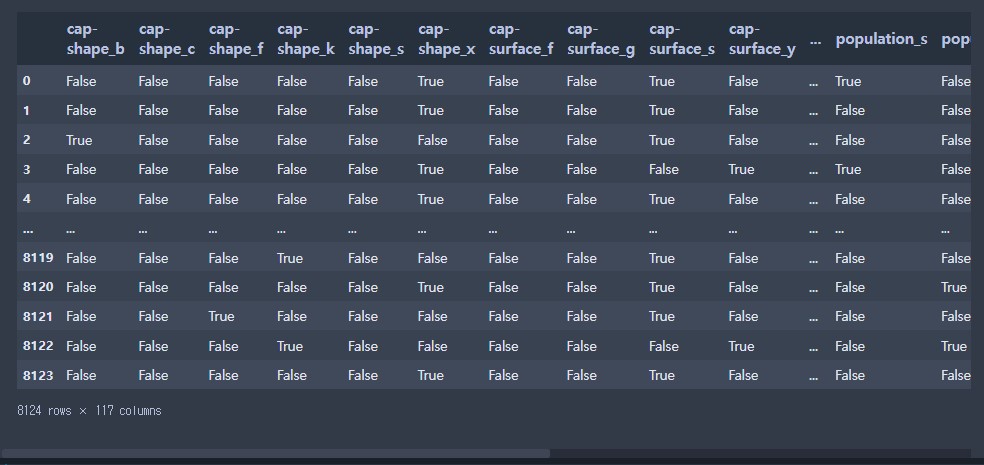
- 데이터 분할
- train_test_split을 이용해서 데이터를 분할하자
- 문제 데이터는 원핫 인코딩 진행된 데이터를 넣어줄 것
- 평가용 셋트의 비율을 30%
- 랜덤 시드의 값을 10
# 만약 문제 데이터가 훈련셋과 평가셋으로 나눠진 경우 같은 인코딩 변환 방식을 사용한다.
# X_train(라벨 인코딩) / X_test (라벨 인코딩) = 0
# X_train(원핫 인코딩) / X_test (원핫 인코딩) = 0
# X_train(라벨 인코딩) / X_test (원핫 인코딩) = 잘 못된 인코딩
# 문제 데이터를 훈련과 평가셋으로 나눠주기 전에 인코딩을 진행하고 분할하는 것이
# 실수를 줄일 수 있는 방법이다.
X_train, X_test, y_train, y_test = train_test_split( X_one_hot,
y,
test_size =0.3,
random_state = 10)
# 데이터 확인
X_train.shape, X_test.shape, y_train.shape, y_test.shape((5686, 117), (2438, 117), (5686,), (2438,))
- 모델 불러오기
- 학습 및 예측 / 평가
# 결정트리 모델 import
from sklearn.tree import DecisionTreeClassifier
# 모델 객체 생성
tree_model = DecisionTreeClassifier()
# 모델 객체 생성
tree_model.fit(X_train, y_train)
# 모델 예측 : predict (평가용 문제 데이터)
tree_model.predict(X_test)array(['e', 'p', 'e', ..., 'p', 'e', 'e'], dtype=object)
# 모델 성능 평가
tree_model.score(X_test, y_test)1.0
배운 내용 요약
Decision Tree(결정트리 / 의사 결정 나무)
- 스무고개 하듯 질문을 던지고 예/아니오(T/F)로 데이터를 분리하며 학습하는 알고리즘
지니 불순도
- 범위 : 0 ~ 0.5
만약 범위가 0에 가깝다면 : 지니 불순도가 낮다
-> 데이터 분리가 잘 된 상태
(데이터를 분리하기 위한 질문이 좋은 질문이다)
만약 범위가 0.5에 가깝다면 : 지니 불순도가 높다
-> 데이터 분리가 잘 안된 상태
(데이터를 분리하기 위한 질문이 안좋은 질문이다)
엔트로피
- 범위 : 0 ~ 1
만약 범위가 0에 가깝다면 : 엔트로피는 낮다(작아진다)
엔트로피가 낮다(작다) -> 데이터의 순도는 높아진다.
데이터의 순도가 높다 -> 데이터가 같은 종류가 많이 모여있다
(데이터를 분리하기 위한 질문이 좋은 질문이다. 정리가 잘되있다)
만약 범위가 1에 가깝다면 : 엔트로피는 크다
엔트로피가 크다 -> 데이터의 순도는 낮아진다.
데이터의 순도가 낮다 -> 데이터의 종류가 다양하고 혼탁하게 섞였다.
(데이터를 분리하기 위한 질문이 안좋은 질문이다. 정리가 안되있다)
주요 파라미터
max_depth : 최대 깊이 제어
min_samples_split : 노드를 분할하기 위한 최소 샘플수
ex) 루트 노드 데이터 5000개 / min_samples_split = 1500
루트노드 분할 가능하다
분할 1 : 4500개 - 분할 가능
분할 2 : 500개 - 분할 불가
min_samples_leaf : 리프노드가 가져야할 최소 샘플 수
ex) 노드의 데이터가 9 / 분할 1번 노드 5개 / 분할 2번 4개
min_samples_leaf가 4로 지정이 되었을 때
노드가 분리 될까? - 분리가 가능 하다
max_leaf_nodes : 리프 노드(최말단 노드)를 최대 몇개까지 만들것인가?
장단점
- 장점 : 직관적이다 / 쉽다
- 단점 : 과대적합에 빠지기 쉽다(취약하다)
- 과대적합을 제어하기 위해서 사전 가지치기
(하이퍼 파라미터 조정이 필요하다)
인코딩 - 문자형 / 범주형 -> 수치형
비닝 - 수치형 -> 문자형 / 범주형
원 핫 인코딩 : 더미변수화
컬럼이 가지고 있는 고유값의 갯수만큼 컬럼을 늘려주고
고유값을 가지고 있는 데이터는 1 , 이외에 데이터는 0으로 바꿔주는 방법
라벨 인코딩 :
유니크값을 가지고 숫자를 순서대로 번호 매기는 방법
1, 2, 3, ....
Seaborn - 시각화 라이브러리
- pandas와 호환성이 좋고 matplotlib보다 좀더 색상이 깔끔함
