
성능 개선 시리즈
- 성능 목표 잡기
- 성능 테스트 진행하기
- 문제 원인 파악하기
- 성능 개선하기
이번 글에서는 JVM 기반의 WAS를 중심으로 서버단에서의 성능 문제 및 장애의 원인을 파악하는 과정을 다루어 보겠습니다. 큰 틀에서 문제 해결하는 과정은 비슷하다고 생각하기 때문에 다른 분야의 개발자 분들에게도 도움이 될거라 생각합니다.
문제의 원인을 찾아가는 과정
문제의 원인을 찾는 과정은 마치 경찰이 범인을 수사하는 과정과 비슷합니다.
먼저 사건이 접수됩니다.
경찰은 사건을 분석한 후 전국에서 범인이 어디에 있을지 지역을 특정합니다.
그리고 그 지역에 가서 탐문 수색을 한 끝에 범인을 잡아냅니다.
범인을 잡았다고 그걸로 끝이 아닙니다. 만약 범인의 배후에 누군가 존재한다면 사건은 다시 일어날 것입니다. 따라서 범인을 심문하여 최종 보스를 알아내야 합니다.
지금부터 문제의 원인을 찾아가는 과정을 수사 과정에 빗대어 설명해보도록 하겠습니다.
사건을 제대로 분석하기
사용자 관점에서 문제들은 아래와 같이 표현될 수 있습니다.
- 응답이 느리다.
- 응답이 없다.
개발자 입장에서 이 정도 정보로는 문제의 원인을 찾기가 어렵습니다. 가능한 많은 정보를 얻어야 합니다.
상황에 대한 정의
Who? 누가 (그 사람만?)
When? 언제 (항상 그 때만?)
Where? 어디서 (거기서만?)
What? 어떤 기능을 (그 기능만?)
How? 어떻게 했길래? (그럴 때만?)
Why? 왜 그랬는데?
(마지막 Why가 어색하게 느껴질 수 있습니다. 하지만 문제를 일으킨 쪽이 그 행동을 왜 했는지 이해하면 새로운 관점의 해결책이 보일 때도 있습니다.)
문제에 대한 정의
What? 무슨 문제가 발생했는데?
Why? 그게 왜 문제인데?
질문은 참고일 뿐이고 매우 구체적으로 정의해야 한다는 것이 포인트입니다. 때로는 상황과 문제를 제대로 정의하는 것만으로도 원인이 예측되기도 합니다. 그리고 마지막으로 Why를 던지는게 중요하다고 생각됩니다. 굳이 해결해야 할 필요가 없는 문제라면 시간을 쏟을 필요가 없겠지요.
지역을 좁히는 USE
문제를 정의했다면 그 원인이 어디에 있을지 알아내야 합니다. 문제의 원인은 사용자의 요청이 들어와서 나가기까지 거치는 모든 곳에 존재할 수 있습니다. 이 때 USE라는 방법론을 사용하면 좋습니다. USE 방법론은 넷플릭스의 퍼포먼스 엔지니어가 만든 방법론으로, 시스템에 문제가 생겼을 때 Step by Step으로 원인을 빠르게 파악하는데 도움이 됩니다.
USE에서 U는 Utilization으로 리소스의 사용률을 의미하며, S는 Saturation으로 리소스의 포화도, E는 Error로 말 그대로 에러를 의미합니다. 리소스는 크게 하드웨어 리소스와 소프트웨어 리소스로 나뉘며 하드웨어 리소스는 CPU, Disk, Network, Memory 등을 가르키고 소프트웨어 리소는 Thread, Connection, File descriptor 등을 가르킵니다.
문제가 생기면 다음의 순서대로 원인을 찾아갑니다.
- E : 시스템이나 애플리케이션의 에러 로그를 확인한다. 이상이 없다면,
- U : 리소스의 사용률을 확인한다. 이상이 없다면,
- S : 리소스의 포화도를 확인한다.
(사실 EUS 방법론이 맞는 것 같은데 왜 USE인지는 저도 잘 모르겠습니다)
Utilization 사용률
사용률은 단위 시간 동안 평균적으로 자원을 얼마나 썼는지를 나타냅니다.
CPU나 Memory 같은 경우 '1분 동안의 사용률 100%'와 같이 표현이 되고, Dist I/O, Network I/O 같은 경우는 '초당 몇 바이트를 쓰거나 읽고 있는지?' 등으로 표현이 됩니다. Disk Capacity는 총 용량 대비 얼마나 용량을 차지하고 있는지를 보면 되겠습니다. 소프트웨어 리소스는 갯수로 셀 수 있습니다. 이를 테면 '최대 스레드 설정 갯수 대비 몇 개가 쓰이고 있는지?'가 되겠죠.
사용률을 포함해 앞으로 소개할 각종 지표를 확인할 수 있는 명령어들에 대한 설명은 부록에 넣어 놓도록 하겠습니다.
Saturation 포화도
사용률에는 평균의 문제가 존재합니다. 10초 동안 CPU 사용률 100%였더라도 50초 동안 30%였다면 1분 동안의 사용률은 40%입니다. 따라서 사용률에 문제가 없어 보인다면 포화도라는 지표를 볼 필요가 있습니다. 포화도는 각각의 리소스가 포화되었을 때 어떤 현상이 일어나는지 관찰함으로써 측정할 수 있습니다.
CPU, DISK 같은 경우 각각 Run Queue, Device Queue에 대기하고 있는 스레드의 수, Memory는 Swap 발생 여부, 네트워크는 Overrun, Drop 현상 발생 여부로 알 수 있습니다. 소프트웨어 리소스는 측정하기가 애매한 것 같습니다.
Error 에러
시스템 관련 로그를 기록하는 /var/log/syslog, /var/log/dmesg에서 'error'나 'fail' 등의 키워드로 에러를 찾을 수 있고, 애플리케이션 같은 경우는 개발자가 직접 에러 로그를 수집할 수 있습니다. 또 5xx HTTP 상태 코드를 가진 응답이 단위 시간 당 얼마나 나갔는지도 체크해볼 수 있습니다.
모니터링
위 지표들에 대해서 모니터링을 할 수 있다면 문제의 원인을 더욱 빨리 포착할 수 있습니다. 알람을 걸어둔다면 더 편하겠죠? USE 방법론을 적용하기 쉽게 모니터링을 다음과 같이 구성해 볼 수 있습니다.
Error Log들을 가장 위에 놓고
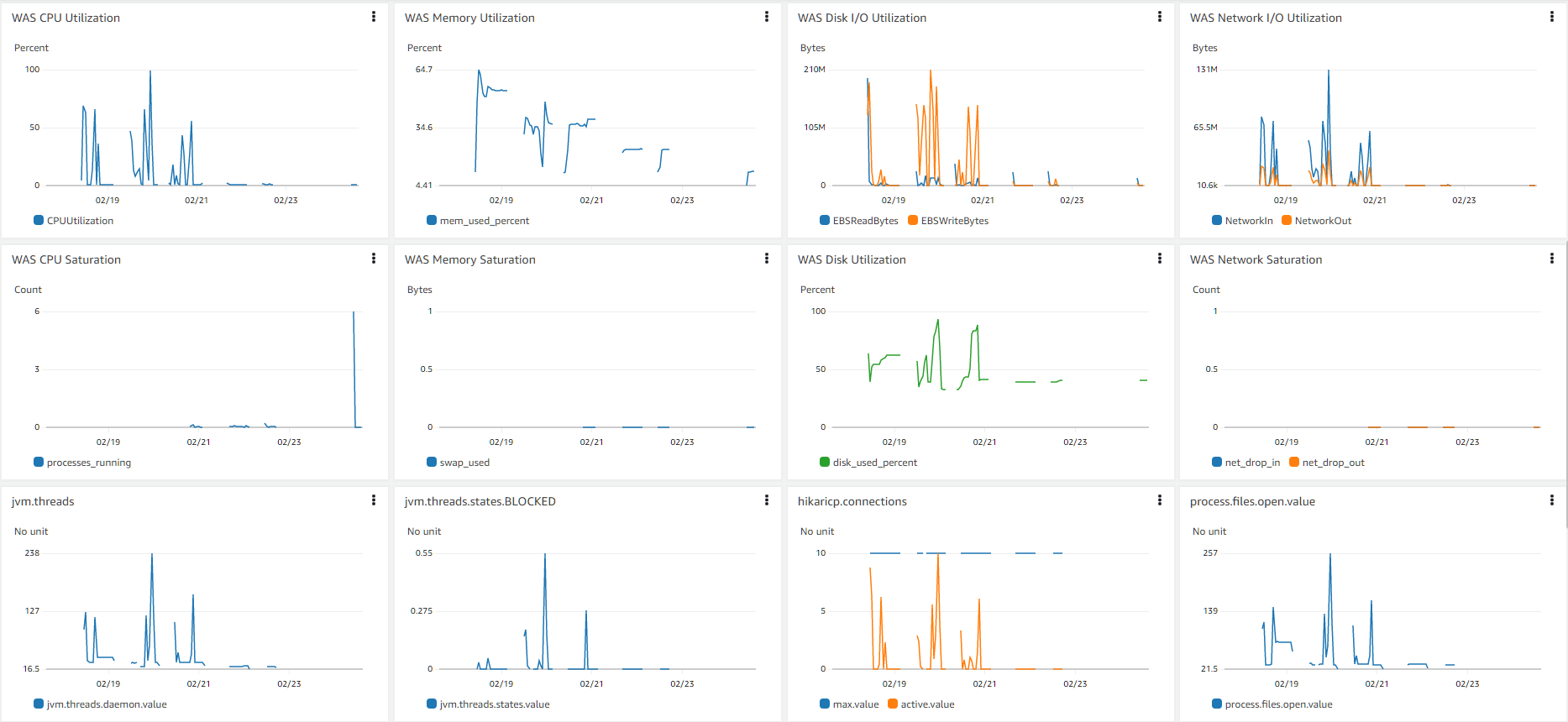
하드웨어 리소스와 소프트웨어 리소스를 순서대로 놓아 보았습니다.
추가적으로 JVM 메모리 공간 관련해서도 모니터링 하면 좋습니다. 만약 Spring Boot를 쓰고 계시다면 Spring Actuator라는 것을 이용해 소프트웨어 리소스를 위처럼 파악하실 수 있습니다.
이렇게 USE 방법론을 활용하여 각 컴포넌트들을 훑으면서 이상 현상을 포착해야 합니다. 에러 로그를 발견한다던가, WAS의 CPU 사용률이 100%를 찍고 있다던가하는 그런 것 말이죠.
탐문 수사하기
이상 현상을 포착했다면 이제 탐문 수사에 들어갈 차례입니다. 샅샅이 수사하여 단서를 수집해야 합니다.
단서를 수집하기 위해 문제가 있는 서버에 접속해서 여러 명령어들을 통해 각 하드웨어 리소스에 대해서 어떤 프로세스가 얼마만큼 이용하고 있는지 알아낼 수가 있습니다. 좀 더 자세히 들어갈 때는 스레드 덤프, 힙 덤프, 패킷 덤프를 사용해볼 수 있는데요.
명령어에 대해서는 말씀드렸듯이 부록에서 설명드리기로 하고, 지금은 다소 생소할 수 있는 이 덤프 패밀리 대해서 설명하도록 하겠습니다.
스레드 덤프, CPU가 심상치 않을 때
스레드 덤프는 특정 시점의 스레드의 상황에 대해 기록하는 것을 의미합니다. 이를테면 덤프 시점에 각 스레드의 상태(RUNNABLE, BLOCKED 등)나 호출 스택, 잡고있는 Lock에 대한 정보 등을 알 수 있습니다.
다음과 같은 명령어로 리눅스에서 쉽게 스레드덤프를 떠볼 수 있습니다.
$ jps // 현재 실행중인 java process의 pid를 얻어온다.
$ jstack [java process pid] > [덤프 파일 이름]
ex. jstack 1275 > thread.dump // 덤프를 떠서 thread.dump 파일에 쓴다.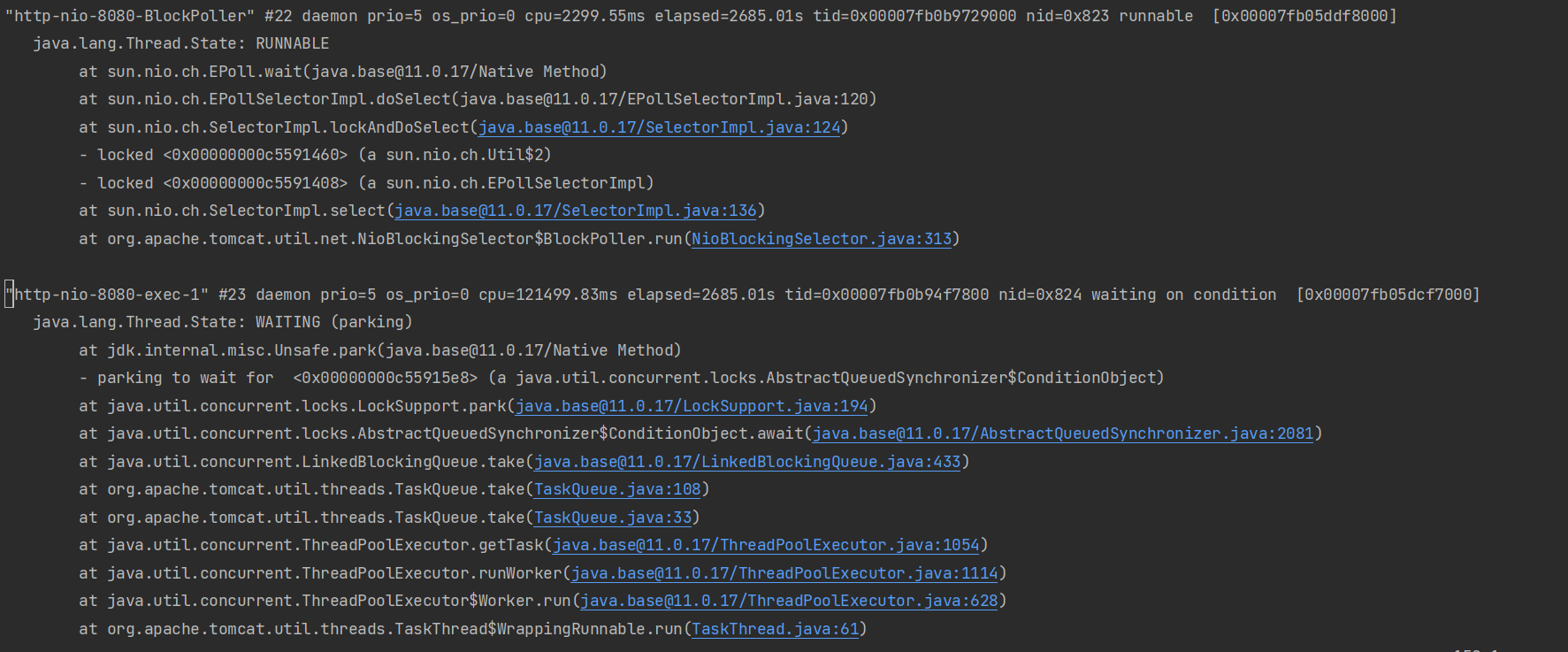
말씀드린 것처럼 덤프 시점의 스레드의 상태나, 호출 스택 등을 보실 수 있습니다. 하지만 이렇게 생짜 파일로 보는 것은 불편합니다. 따라서 스레드 덤프를 분석해주는 툴을 쓰면 좋은데요. 로컬 컴퓨터로 옮겨서 Intellij Ultimate을 통해 볼 수도 있고, Arthus라는 툴을 이용해 리눅스 컴퓨터에서 바로 볼 수도 있습니다.
Intellij Ultimate
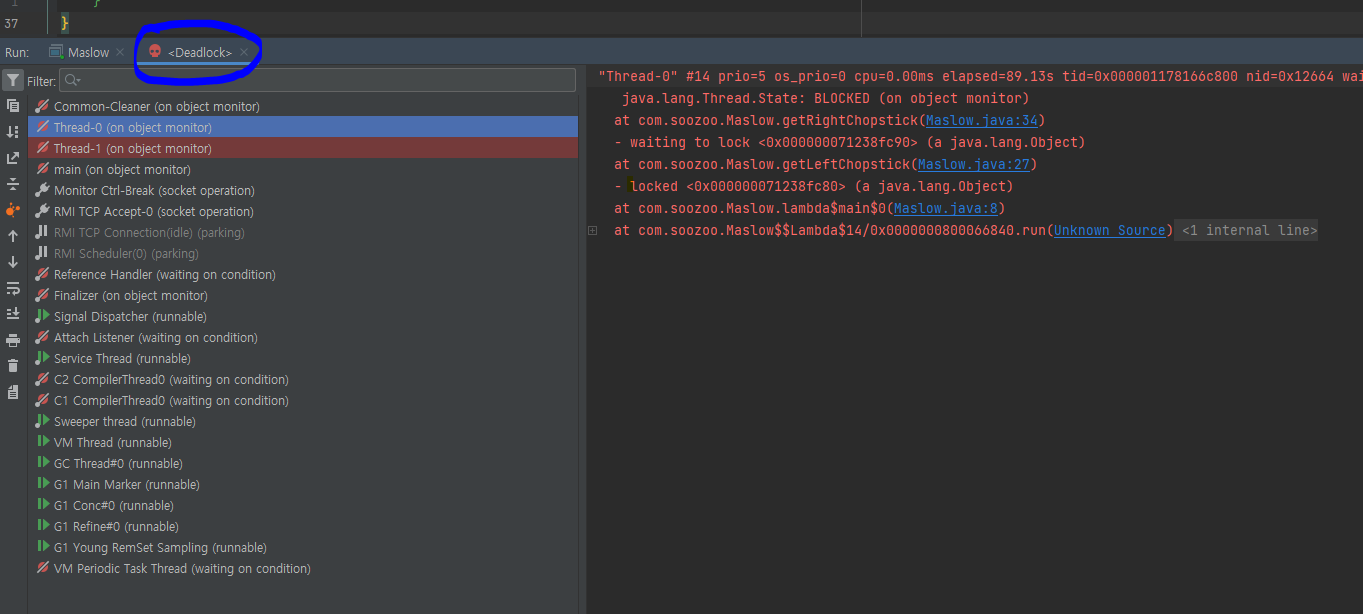
Arthus

스레드 덤프의 핵심은 멈춰 있는 스레드를 찾는 것입니다. 따라서 스레드 덤프를 뜰 때는 5~10초 주기로 최소 5번 떠야하며 스레드 덤프들을 살펴보면서 멈춰있는 스레드가 있는지 살펴보아야 합니다. RUNNABLE 상태로 멈춰 있는 경우 무한루프에 빠진 경우이며, BLOCKED 상태로 멈춰 있는 경우 데드락에 걸렸거나 한 쓰레드가 락을 매우 오래 잡고 있는 상황입니다. 스레드 덤프는 성능에 무리를 주지 않으니 문제가 발생했을 경우, 바로 스레드 덤프를 떠서 스레드 상황을 보존하는 것이 좋습니다.
스레드 덤프를 이용하여 단서를 수집한 사례는 이 곳에서 보실 수 있습니다.
힙 덤프, 메모리가 심상치 않을 때
힙 덤프란 특정 시점의 각 객체의 메모리 점유 상황을 기록하는 것을 말합니다.
다음의 명령어를 통해 힙 덤프를 떠볼 수 있습니다.
jmap -dump:[live],format=b, file=<file-path> <java process id>
ex. jmap -dump:live,format=b,file=/home/ubuntu/heap.hprof 11541
// 살아있는 오브젝트들만, 바이너리 형식으로, /home/ubuntu/폴더에 heap.hprof 이름으로, 11541 자바 프로세스에 대한 힙 덤프 생성이렇게 생성한 힙 덤프를 로컬 컴퓨터로 가져와서, MAT나 VisualVM, Intellij Ultimate같은 툴을 이용해 확인해볼 수 있습니다. 어떤 객체가 메모리를 많이 잡고 있는지 아래처럼 한 눈에 알 수 있습니다.
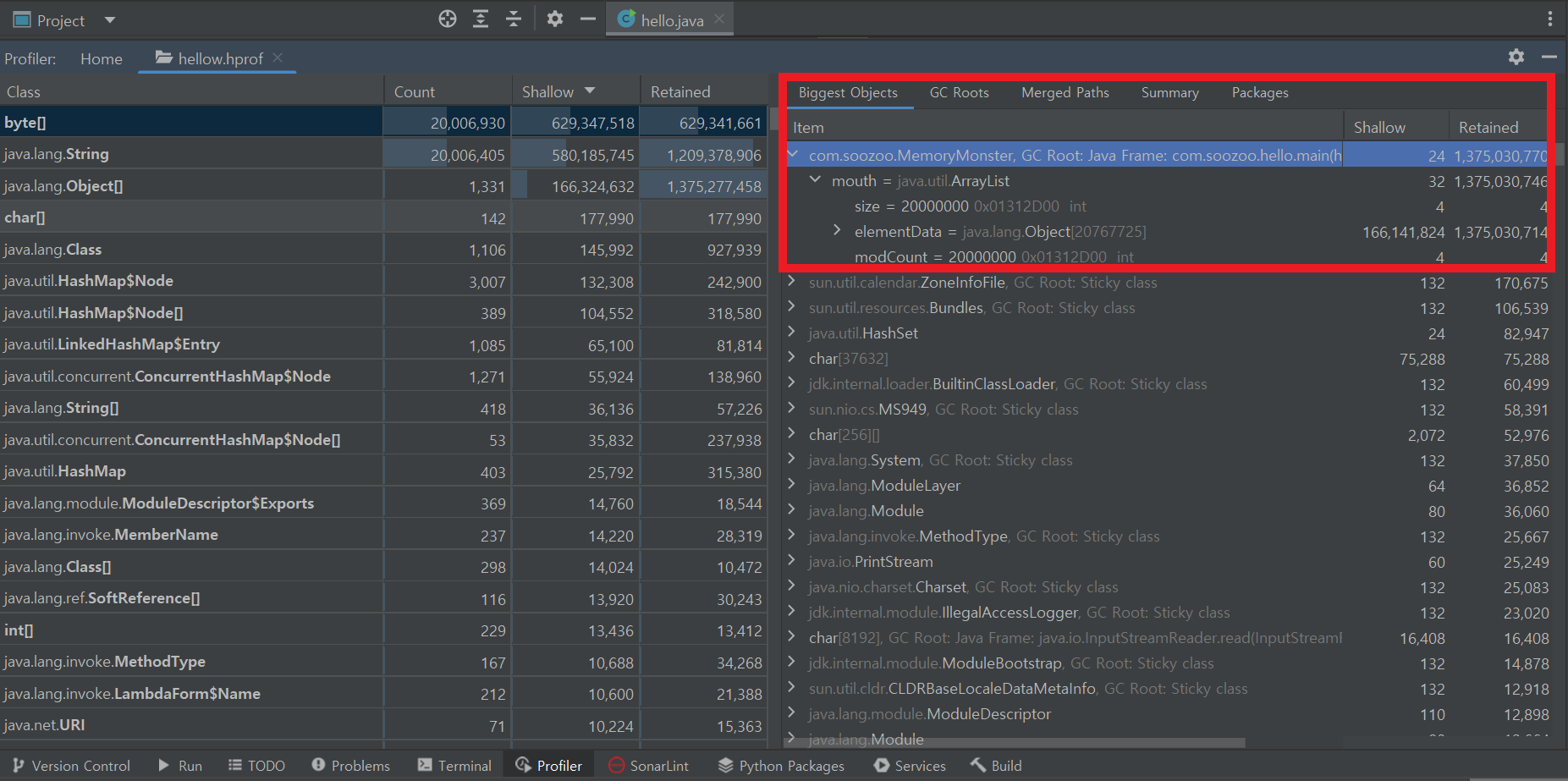
이것은 Intellij Ultimate으로 힙 덤프를 분석한 이미지인데요. 제가 만든 MemoryMonster라는 클래스의 객체가 엄청난 메모리를 잡고 있는 것을 확인하실 수 있습니다.
힙 덤프를 뜨게 될 경우 시간이 오래 걸릴 수 있고 그 동안 서비스가 불가능하기 때문에 신중하게 판단하고 메모리 릭이나 OOM이 발생했을 때만 힙 덤프를 떠봐야 합니다.
힙 덤프를 사용하여 단서를 수집한 사례는 이 글에서 확인하실 수 있습니다.
패킷 덤프, 네트워크가 심상치 않을 때
패킷 덤프를 이용하면 일정 시간 동안 들어오고 나가는 패킷에 대한 상세한 정보를 알 수 있는데요. 특정 IP로 부터 온 패킷, 특정 포트를 통해 오고 간 패킷 등등 여러 조건으로 필터링해서 볼 수도 있습니다. 이를 통해 평소 상황의 패킷 흐름과, 문제가 발생했을 때의 패킷 흐름을 비교해보면서 이상 현상을 찾을 수 있습니다.
다음과 같은 명령어로 리눅스에서 쉽게 패킷 덤프를 떠볼 수 있습니다.
tcpdump -i eth0 tcp port 8080 -w dump.pcap
// eth0네트워크 인터페이스,tcp 프로토콜,8080 포트를 이용한 패킷 캡쳐본을
// dump.pcap 파일로 생성패킷 캡처 파일을 생성하고 로컬 컴퓨터로 이 파일을 가져와서 Wireshark라는 프로그램을 통해 이쁘게 볼 수 있습니다.
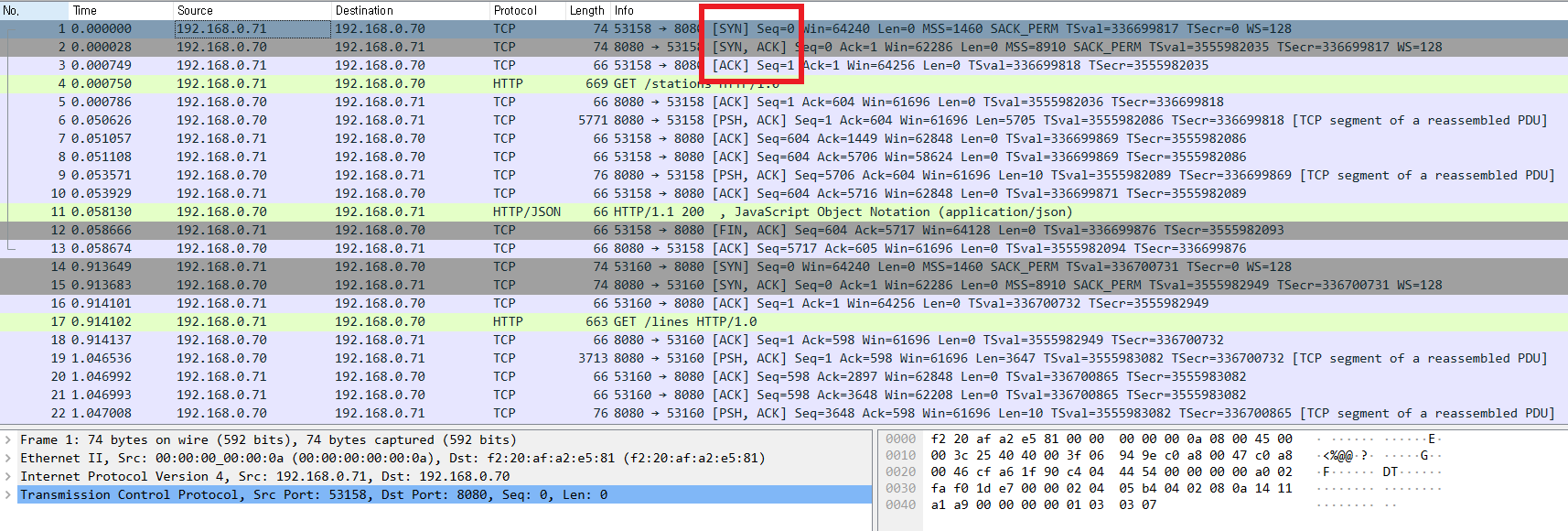
(TCP three way handshake가 일어나는 모습을 네모쳐보았습니다.)
패킷 덤프를 이용하여 단서를 수집한 사례는 이 글에서 보실 수 있습니다.
가설 및 검증
소개해드린 여러가지 툴들을 이용해 이상 현상과 관련 있어 보이는 여러 단서들을 찾을 수 있습니다. 이 후 단서들을 토대로 여러가지 가설을 세우고 검증하는 과정을 통해서 문제의 원인을 파악할 수 있습니다. 내가 그 동안 쌓아왔던 지식과 경험에 비례해 세울 수 있는 가설도 많아질테고, 검증 또한 철저히 할 수 있을 것입니다.
가설 및 검증 과정을 통해 원인을 찾았다면 그 원인을 제거함으로써 문제를 해결할 수 있습니다.
하지만 정말로 근본 원인 (Root Cause)를 없애지 않는다면 문제는 다시 생길 수 있는데요.
이 근본 원인은 어떻게 알아낼 수 있을까요?
배후를 밝히는 5WHY
근본 원인을 알아내기 위해서는 '5 WHY'라는 방법을 사용해볼 수 있습니다. '왜 그러한 상황이 발생하였는가?'라는 WHY를 계속 던져 근본 원인을 찾는 방법인데요. 이를테면 아래와 같이 진행해 볼 수 있습니다.
Q. 왜 시스템이 응답을 하지 못하는가?
A. WAS의 CPU 사용률이 100%를 계속 찍고 있기 때문이다.
Q. 왜 CPU 사용률이 100%를 찍는가?
A. 특정 스레드가 무한 루프에 빠졌기 때문이다.
Q. 왜 특정 스레드가 무한 루프에 빠졌는가?
A. 내가 무한 루프에 빠지는 로직을 짰기 때문이다.
Q. 나는 무한 루프에 빠지는 로직을 왜 짰는가?
A. 무한 루프에 빠질 줄 몰랐기 때문이다.
Q. 무한 루프에 빠질 줄 왜 몰랐는가?
A. 코드 가독성이 안 좋았기 때문이다.
=> 코드 가독성 개선을 통해 근본 원인 제거 !
5는 상징적인 숫자일 뿐 그보다 적거나 많아도 상관 없습니다. 근본 원인은 코드 레벨에서 찾을 수도 있고 위처럼 개발 프로세스 단까지 내려갈 수 있습니다. 깊게 내려가 원인을 제거할수록 그 영향력이 커진다 생각합니다.
문제의 원인을 찾는 방법 정리
- 문제를 정확히 정의하고 정말 문제가 맞는지 생각해본다.
- USE 방법론을 이용해 큰 틀에서 원인이 있을 법한 곳을 짚어본다.
- 각종 툴을 이용해 세세하게 단서를 수집한다.
- 가설을 세우고 검증하는 과정을 통해 원인을 파악한다.
- 5WHY를 활용해 근본 원인을 알아낸다.
범인은 대개 비슷하게 생겼습니다. 범인이 주로 어떻게 생겼는지 알고 있다면 수사 과정이 한결 수월할 것입니다. 응답이 느린 문제에 대해서는 다음 글에서 알아보기로 하고, 지금부터는 응답이 없는 문제의 대표적인 원인들에 대해서 살펴보도록 하겠습니다.
응답이 없는 문제의 원인
무한루프
애플리케이션 로직상의 문제로 무한루프에 빠질 경우 이 로직을 수행하는 쓰레드가 CPU 하나를 점유하게 됩니다. 따라서 CPU 리소스의 부족으로 처리량이 떨어져 응답이 느려지게 됩니다. 문제를 야기시킨 로직을 필요로 하는 요청이 추가로 오게 되면 CPU 전체가 이 로직에 점유 당해 응답을 전혀 못하게 되는 문제로 발전할 수 있습니다.
이 문제가 발생하게 될 경우 CPU 사용량이 점차적으로 올라가게 되고 내려오지 않게 됩니다. CPU 코어 하나만 100%로 사용되고 있는 경우도 무한루프 문제일 가능성이 큽니다. USE 방법론을 통해 CPU의 이상현상을 감지했다면 앞서 말씀드린 것처럼 스레드 덤프를 이용하여 무한루프에 빠진 스레드가 어떤 스레드인지 알아낼 수 있습니다.
데드락
데드락은 락을 잡고 있는 스레드들이 서로의 락을 기다리는 상황을 말합니다. 서로 젓가락 한 쪽씩 들고 '너가 먼저 줘, 쓰고 줄게'라고 얘기하며 아무도 주지 않는 상황과 비슷합니다.
데드락이 발생하게 될 경우 데드락에 걸려 있는 락을 중심으로 스레드들이 BLOCKED 상태에 빠지게 됩니다. BLOCKED된 스레드들은 스레드 풀로 반환되지 않고 시간이 지날수록 스레드 풀의 스레드 수는 증가하게 됩니다. 스레드 풀이 허용 가능한 최대 스레드 개수에 도달하게 되면 더 이상 요청에 응답할 수 없게 됩니다.
데드락이 발생할 경우 스레드들이 BLOCKED 되어 있는 상태이기 때문에 CPU 사용량은 낮지만 요청에 응답할 수 없는 상태가 됩니다. 데드락이 발생했다고 판단되면 마찬가지로 스레드 덤프를 이용해서 데드락의 유무와, 데드락에 걸린 스레드들을 알아낼 수 있습니다. 데드락이 있을 경우 스레드 덤프에 친절하게 데드락이 있다고 표시됩니다.
메모리 릭
메모리 릭은 더 이상 사용되지 않음에도 GC되지 않은 객체들로 메모리가 꽉차 메모리가 부족해지는 현상을 말합니다.
메모리 릭이 생길 경우 사용 가능한 메모리 영역이 점차 적어지며 잦은 Full GC로 인한 멈춤 현상으로 인해 애플리케이션이 느려집니다. 메모리 릭으로 인해 메모리가 꽉차게 될 경우 GC 관련 스레드만 실행되면서 CPU 코어 하나를 100% 점유하게 되고 나머지 모든 스레드는 아무런 작업을 하지 못하게 됩니다. 또한 더 이상 가비지 컬렉터가 가용 가능한 메모리를 만들어내지 못하게 될 때 OutOfMemoryError가 발생하여 애플리케이션이 다운될 수 있습니다.
메모리 릭이 발생한다면 일반적으로 Full GC가 자주 발생하면서 메모리 사용량이 80%~90%를유지하게 됩니다. 만약 Full GC 수행 이후에 사용량이 20%~50% 대로 떨어진다면 메모리 릭이 아닐 확률이 높습니다. 메모리 릭이 발생했을 경우 힙 덤프를 이용해 메모리를 많이 잡고 있는 객체를 알아낼 수 있습니다.
한 편 OOM이 발생할 경우는 힙 덤프를 뜨지 못하는데요. 이 때는 JVM의 시작 옵션으로
-XX:+HeapDumpOnOutOfMemoryError 을 줌으로써 OOM 발생시 자동으로 힙 덤프를 생성하게 할 수 있습니다.
설정 문제
부절절한 설정이 원인이 되는 경우도 많습니다. 이를 테면 각 리눅스에는 프로세스 별로 열 수 있는 파일 갯수 제한이 있습니다. 'ulimit -a'라는 명령어를 쳤을 때 open files 항목에 있는 갯수가 바로 그 제한인데요. TCP 연결을 하기 위해서는 소켓이 필요하고 소켓은 파일로 취급되기 때문에 이 값이 만약 1000으로 설정되어 있다면 1000개 이상의 커넥션을 맺을 수 없습니다. 커넥션을 맺을 수 없다면 클라이언트는 커넥션이 거부되거나 Connection Timeout이 발생하여 응답을 못 받게 될 수 있겠죠.
open files 제한을 늘려주더라도 각 서버 프로그램에서 최대로 맺을 수 있는 커넥션 갯수가 낮게 설정되어 있다면 마찬가지로 그 이상의 요청이 왔을 때 위와 같은 문제가 발생할 수 있습니다.
서버 커넥션에 대한 설정 이외에도 Thread Pool, DB Connection Pool 관련 설정으로 인해 문제가 발생할 수 있습니다. DB Connection Pool Size가 작아 커넥션이 부족할 경우 스레드는 connection-timeout 설정값만큼 커넥션을 얻기 위해 기다립니다. 스레드 풀의 모든 스레드가 커넥션을 기다리는 상태가 되면 더 이상 요청을 받을 수가 없게 됩니다.
따라서 Thread Pool Size, DB Connection Pool Size, DB Connection-Timeout 설정값을 적절히 설정하는 것도 중요합니다. 귀찮다고 너무 크게 잡는 것도 문제가 되는데요. 스레드 및 커넥션이 늘어날수록 메모리를 많이 차지하고 각각 WAS와 DB의 컨텍스트 스위칭을 증가시킵니다. 특별한 공식이 있지는 않기 때문에 기준점을 정하고 성능 테스트를 진행하며 최적의 값을 찾아나가야 합니다.
디스크 용량 포화
디스크 용량이 꽉 차게 될 경우 시스템이 아무런 출력을 하지 못해서 멈추어 버리는 행(hang)현상이 발생할 수 있습니다. 보통 아무 생각 없이 저장하는 로그 파일로 인해 디스크 용량이 꽉차게 되고 장애의 원인이 되기도 합니다. 따라서 주기적으로 로그 파일을 백업 및 압축, 이동 등의 관리를 하는 것이 중요합니다.
지하철 노선도 서비스의 문제 원인 파악
지난 글에서 지하철 노선도 서비스의 성능을 테스트하면서 다음과 같은 문제를 발견했습니다.
- Vuser 5명부터 경로 검색 결과 페이지의 목표로 한 응답 시간을 달성하지 못함.
- Vuser 200명부터 경로 검색 페이지의 갑작스런 응답 시간 증가.
- Vuser 약 250명부터 요청이 대규모로 실패하기 시작.
1번과 2번은 다음 글에서 다루기로 하고 3번 문제의 원인을 파악해보도록 하겠습니다.
문제 정의
Vuser 약 250명부터 요청이 대규모로 실패하기 시작.
정의를 좀더 확실하게 할 필요가 있어 보입니다.
상황에 대한 정의
Who? 일부 Vuser
When? 매 테스트 상황마다 Vuser가 255명을 넘어갈 때
Where? 외부망에서
What? 경로 검색 결과
How? 지속적으로 요청했을 때
문제에 대한 정의
What? 1초 당 100개 이상의 응답 실패가 갑자기 발생.
Why? 가장 중요한 기능에 대한 대규모 요청 실패는 서비스 신뢰도 하락으로 이어지고, 한 번 떨어진 신뢰도는 복구하기 힘들다.
최종 정의
매 테스트 상황마다 Vuser가 255명을 넘어갈 때, Vuser들의 경로 검색 결과 요청이 대규모로 실패하고 있다. 가장 중요한 기능에 대한 대규모 요청 실패는 서비스 신뢰도 하락으로 이어지고, 한 번 떨어진 신뢰도는 복구하기 힘들기 때문에 해결해야 할 문제로 보인다.
범위 좁히기
USE 방법론에 따라 Error Log부터 먼저 살펴보겠습니다.
Nginx의 Error Log

..?
바로 이상 현상을 발견했네요.
뭔가 감이 오시나요?
테스트 에이전트에서 Nginx와 Connection을 255개 맺고, 다시 Nginx가 WAS와 255개의 커넥션을 맺으면 정확히 512....!는 아니고 510개의 커넥션이 생성됩니다.
자연스럽게 다음과 같은 가설을 세워보았습니다.
'Nginx Worker Process의 Max Connection이 512개로 설정되어 있고 Vuser가 255명을 넘어갈 때 커넥션을 더 이상 받을 수 없어 응답 실패가 일어났다.'
바로 Nginx의 Worker Process의 Max Connection 갯수를 2000개로 늘리고 가설에 대한 검증을 진행해보았습니다.

Vuser가 260명이 되어도 대규모 실패는 이러나지 않고 있네요 !

이전에는 이렇게 대규모로 실패가 일어났었습니다 ㅠ

Nginx Worker Process 또한 1개만 돌고 있다는 사실이 Worker Process의 Max Connection 갯수 문제가 맞다는 사실을 뒷받침해주네요.
근본 원인 파악 후 원인 제거하기
Worker Process의 Max Connection 갯수를 조정함으로써 상황을 마무리 지을 수 있지만, 5WHY를 활용하여 이 문제를 야기한 보다 더 근본적인 원인에 대해 파악해 보도록 하겠습니다.
Q. 왜 응답 실패 문제가 발생했는가?
A. Nginx의 Worker Process의 Max Connection 갯수가 낮게 설정 되어 있었다.
Q. 왜 Max Connection 갯수가 낮게 설정되어 있었는가?
A. 내가 Nginx를 설치하고 설정하지 않았다.
Q. 왜 설정안했는가?
A. 설정하는 것을 깜빡했다.
Q. 왜 깜빡했는가?
A. 설정하는 것을 그 때 그 때 생각나는대로 진행했기 때문이다.
=> 컴포넌트 설정시 꼭 확인해봐야 할 부분에 대해서 체크리스트를 만들고, 시스템에 새로운 컴포넌트가 추가될 때는 이 체크리스트에 따라 설정하자 !
직접 5WHY를 적용해보니, 정말 아래로 한도 끝도 없이 내려갈 수도 있는 것 같습니다. 질문의 방향을 잘못 잡으면 이상하게 흘러가기도 하구요. 결국 근본 원인을 찾는 이유는 재발 방지 혹은 더 나은 프로세스를 만들기 위함이니 앞으로의 개선 방향에 대한 인사이트를 얻었다면, 적정한 선에서 멈추는 것도 좋을 것 같습니다.
마무리
저는 이 글을 쓰면서 생소했던 지식들이 문제 원인 파악이라는 큰 틀 안에 정리되는 느낌을 받았는데요. 여러분도 그런 경험이 되셨으면 좋겠습니다. 다음 글에서는 응답 속도가 느린 문제의 원인에 대해서 살펴보고 지하철 노선도 서비스의 성능을 개선해보는 시간을 갖도록 하겠습니다 :)
부록 - 리눅스 명령어
최근에 저는 모르는 명령어, 모르는 설정, 복잡한 코드 등을 ChatGPT를 이용해서 해석하는데요.
리눅스 명령어나 옵션들에 대해서는 자세히 적지 않았으니, ChatGPT를 사용해보지 않으신 분들은 이 기회에 ChatGPT를 이용해보시는 것도 좋을 것 같습니다.
CPU, 메모리 사용률
$ top리눅스에서 위 명령어를 치면 다음과 같은 화면이 나오고, 쉽게 CPU와 메모리의 사용률을 알 수 있습니다. 또한 어떤 프로세스가 CPU나 메모리를 많이 잡고 있는지 알 수 있습니다.
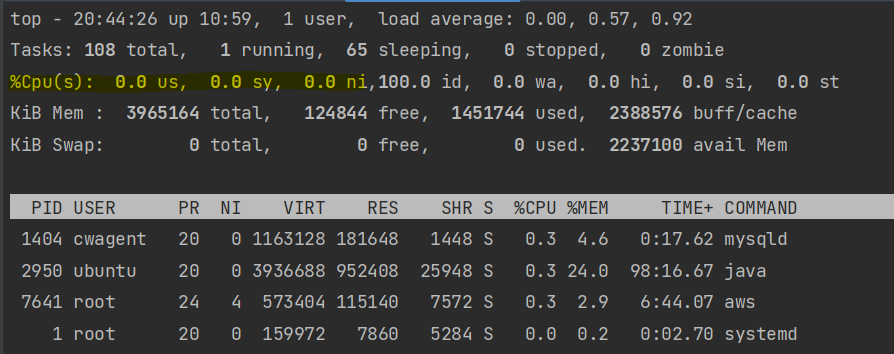
하이라이트 친 곳을 보시면 CPU 사용량이 나오는 것을 볼 수 있습니다. us와 sy를 더하면 CPU 사용률을 계산할 수 있습니다. 각각 일반 Process의 사용률과 커널 Process의 사용률 의미합니다. 각 CPU 코어 별 사용 시간을 보고 싶다면 이 화면에서 1번을 누르면 됩니다.
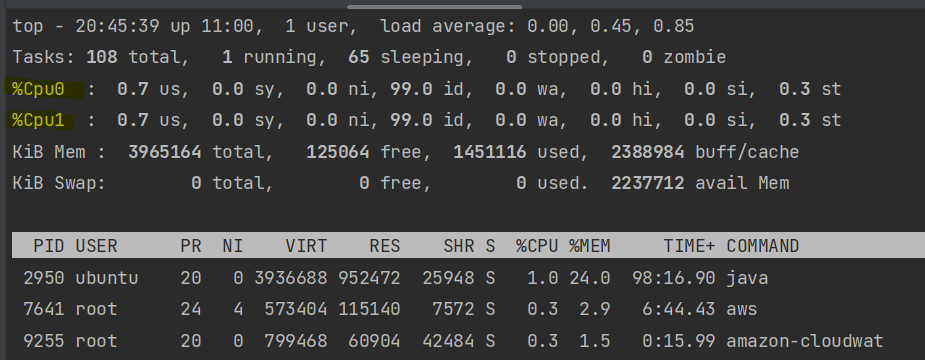
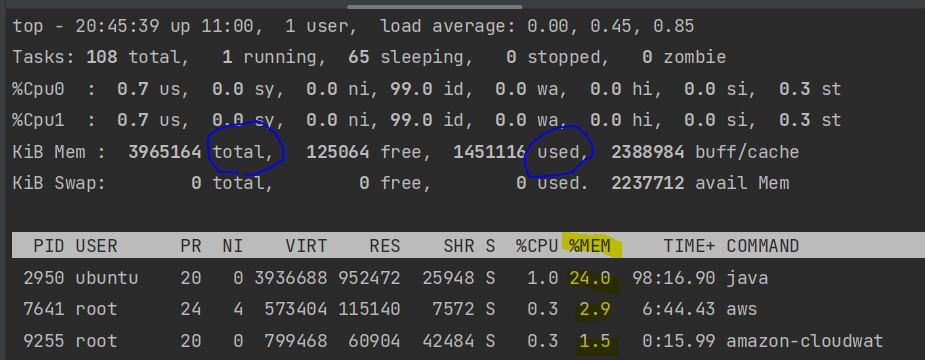
메모리 사용률은 그 아래에 KiB Mem 부분을 보시면 됩니다. 100 x (total / used) 하게 되면 메모리 사용률이 나오게 되지만 그 아래에 프로세스 별 메모리 사용량을 보시면 얼추 계산할 수 있습니다.
디스크 사용률
$ df -h => 현재 사용 가능한 디스크 여유 공간 확인
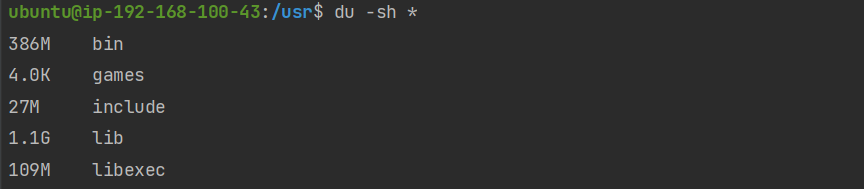
$ du -sh * => 현재 디렉토리 내에 각 파일별 사이즈 확인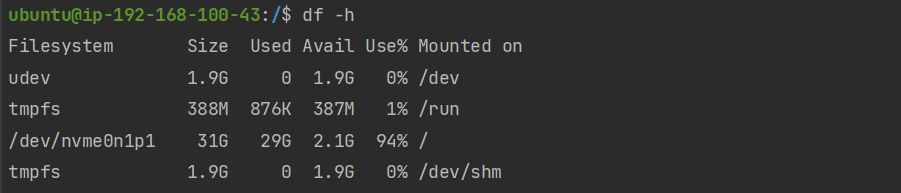
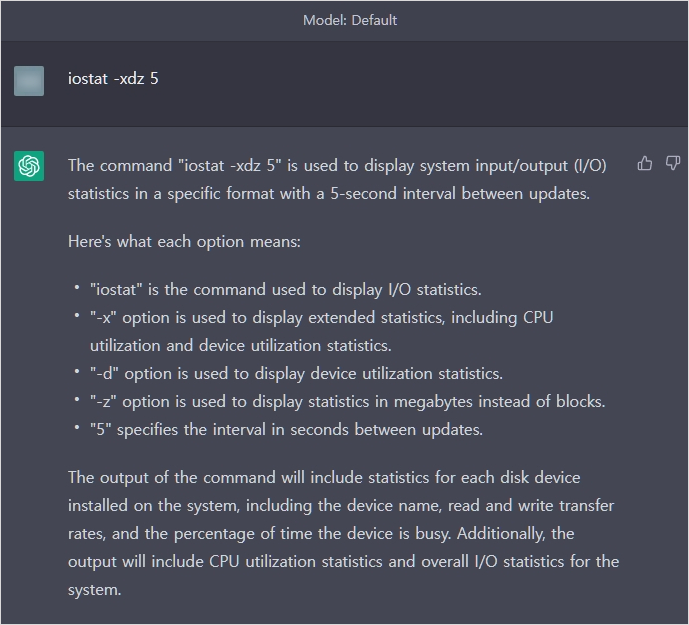
디스크 I/O Per Second
$ iostat -xdz 5 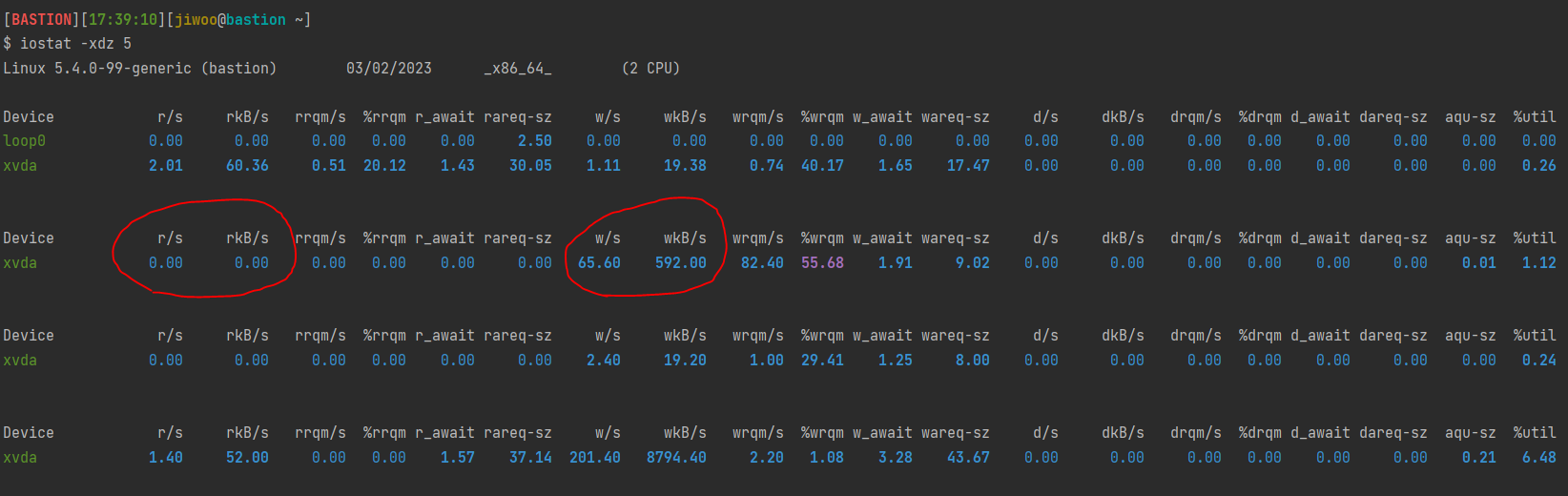
주의해야 할 점은 이 명령어에 가장 마지막에는 주기를 입력하는데요. 5를 입력했으니 5초마다 사용률을 보여주는 것이죠. 리눅스에서는 이렇게 일정 주기로 찍히는 명령어가 많은데 이 때 가장 첫번째 나오는 데이터는 거르셔야 합니다. 현재 상황이 아니라 부팅 후부터 지금까지의 상태를 나타내는 정보가 주로 오기 때문입니다.
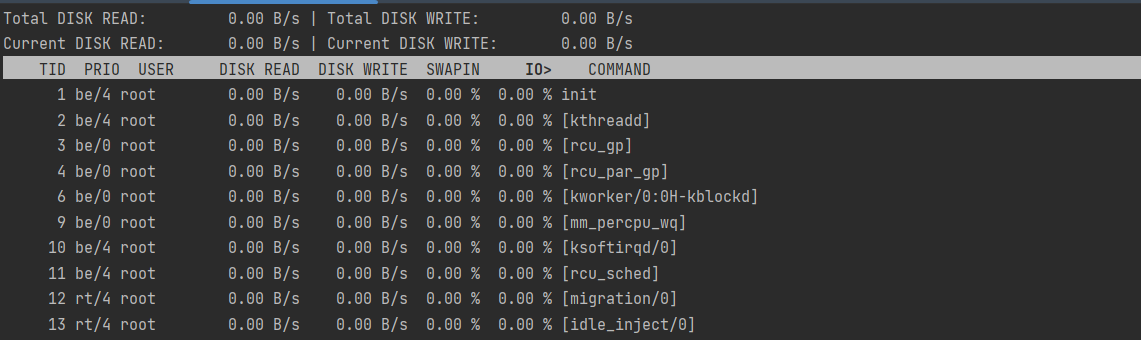
$ iotop이 명령어를 통해 어떤 프로세스 또는 스레드가 disk i/o 작업을 얼만큼 하고 있는지 알 수 있습니다.
네트워크 I/O Per Second
$ sar -n DEV,TCP,ETCP 5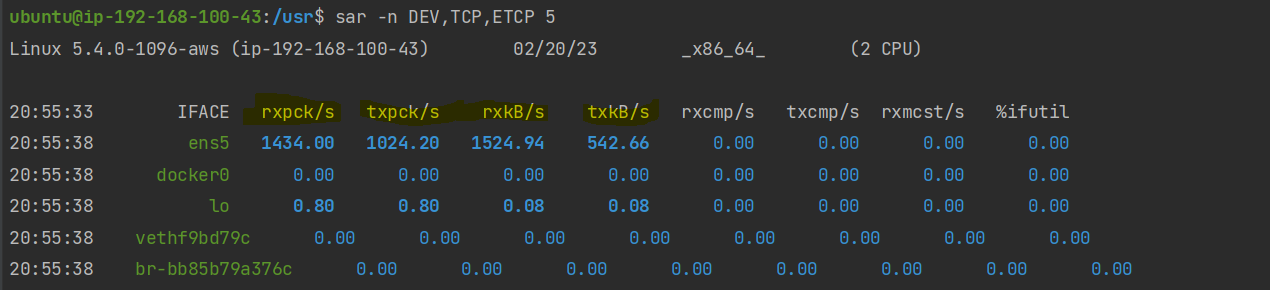
rxkB/s : 초당 받는 데이터, 단위 kB
txkB/s : 초당 나가는 데이터, 단위 kB
$ ss -4tp이 명령어를 통해 어떤 프로세스가 어떤 소켓을 열고 있는지와 소켓의 상태를 알 수 있습니다. 또한 각 소켓 별로 처리되지 못해 쌓여 있는 데이터의 양(bytes)를 알 수 있습니다.

CPU 포화도
스레드들은 CPU나 Disk를 이용하기 위해서 각각 Run Queue와 Device Queue에서 대기하고 OS에 의해서 스케쥴링됩니다. 따라서 큐의 길이를 보면 얼마나 리소스가 포화되었는지 판단할 수 있습니다.
vmstat 1위 명령어는 1초마다 현재 리눅스의 상태를 대략적으로 찍어 보여주게 됩니다. 아래는 4초 동안 4번 찍힌 이미지입니다.
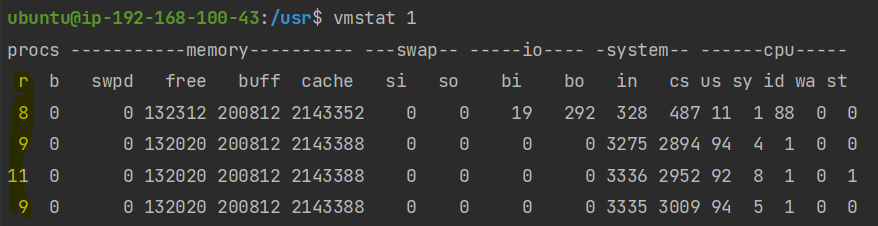
가장 앞에 있는 r을 보시면 됩니다. r은 RUNNABLE 상태의 스레드 갯수로, 큐에 대기하고 있는 스레드와 현재 CPU에서 실행중인 스레드를 모두 포함한 값이므로 r이 CPU의 갯수보다 높을 때 포화 상태라고 할 수 있습니다. r이 얼마나 높냐에 따라 포화 정도를 가늠해볼 수 있습니다.
메모리 포화도
메모리가 포화될 경우 메모리에 올라와 있는 Process를 디스크로 내쫓는 Swap Out과 다시 메모리로 들고 오는 Swap In 현상이 지속해서 발생합니다. 따라서 이 현상이 얼마나 발생하는지를 봄으로써 포화도를 측정할 수 있습니다.
vmstat 1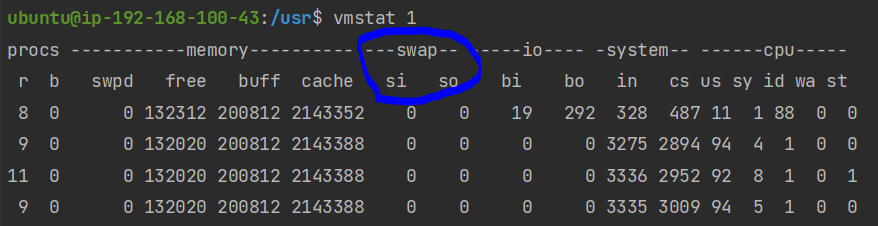
si와 so가 각각 1초당 Swap In, Swap Out되는 메모리의 양을 나타냅니다. 일반적으로 이 값이 10 이상이 넘어가면 포화되고 있다고 판단하시면 됩니다.
디스크 I/O의 포화도
말씀 드렷듯이 아직 처리되지 못해 디스크 큐에 대기하고 있는 스레드의 수를 보면 됩니다.
iostat -xdz 5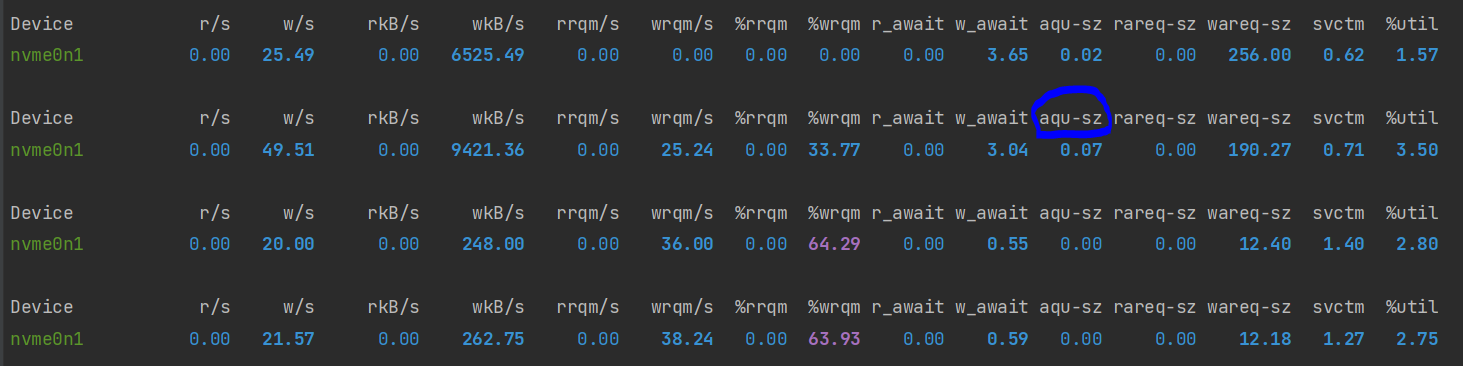
aqu-sz가 평균 큐의 길이를 의미하는데요. 1보다 클 경우 포화 상태라고 보시면 됩니다.
네트워크 I/O 포화도
네트워크가 포화될 경우 패킷들이 처리되기 전에 임시적으로 저장되어 있는 버퍼가 꽉차게 됩니다. 그에 따라 도착하는 패킷이 버려지거나 사라지는 Overrun 현상이 발생하게 되구요. 네트워크 혼잡 상황에서 네트워크 패킷이 사라지는 Drop 현상 또한 나타날 수 있습니다. 따라서 이 현상이 일어났는지를 관찰하면 네트워크 포화도를 알 수 있습니다.
ifconfig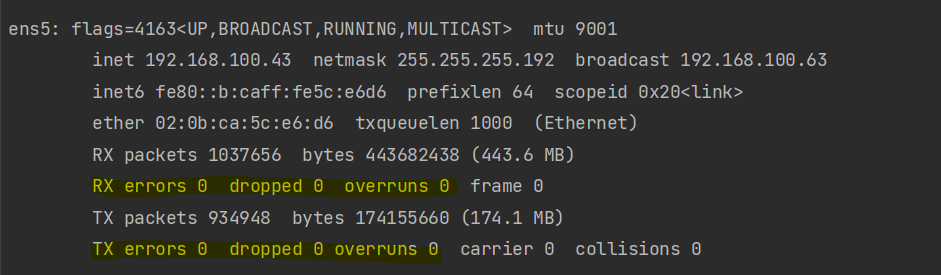
Reference
넥스트스텝 - 인프라 공방
이상민, 자바 트러블슈팅, 제이펍, 1쇄, 2019
Thinking Methodically about Performance - ACM Queue
USE Method: Linux Performance Checklist
조대협, 대용량 아키텍처와 성능 튜닝, 프리렉, 초판, Part 4, 2015
SRE 팀에서 장애의 root cause를 찾고 재발방지 하는 방법 | 우아한형제들 기술블로그
우아~한 장애대응 | 우아한형제들 기술블로그
리눅스 서버의 TCP 네트워크 성능을 결정짓는 커널 파라미터 이야기 - 2편 : NHN Cloud Meetup
Java, max user processes, open files | 우아한형제들 기술블로그
제11회 D2 OPEN SEMINAR 'Java 애플리케이션 트러블 슈팅' 편


양질의 포스트 정말 감사합니다