성능 개선 시리즈
- 성능 목표 잡기
- 성능 테스트 진행하기
- 문제 원인 파악하기
- 성능 개선하기
들어가며
"성능테스트라는 말을 들으면 막연합니다. "
"어디서부터 시작해야 할지, 어떻게 해야 할지 모르겠습니다."
저번 글에 이어서 이번 글에서는 위와 같은 생각을 가진 백엔드 개발자 분들(=본인)을 위해 성능 테스트에 대해서 설명하고 간단한 성능 테스트를 진행하면서 막연한 두려움을 걷어내는 시간을 가져보도록 하겠습니다.
트래픽이 많을 때 발생하는 문제를 사전에 찾는 작업
테스트란 무엇일까요?
테스트는 '특정한 상황'에서 발생하는 문제를 사전에 찾기 위한 작업입니다.
이를 테면 '단위 테스트'는 '특정 메소드를 실행하는 상황'에서 발생하는 문제를 사전에 찾기 위한 작업이고, '통합 테스트'는 '여러 메소드와 외부 의존 모듈이 함께할 때' 발생하는 문제를 사전에 찾기 위한 작업입니다.
그리고 '성능 테스트'는 '트래픽이 많은 상황'에서 발생하는 문제를 사전에 찾기 위한 작업입니다
정의 톺아보기
트래픽?
트래픽이란 1초 동안 서버로 요청되는 수입니다.
RPS(Request Per Second)로 표현하기도 합니다.
트래픽이 많은 상황?
이런 트래픽이 얼마나 많아야 많다고 할 수 있을까요?
1000rps면 많다고 할 수 있을까요?
그럴 수도 있고 아닐 수도 있습니다. 서비스에 따라 다르니까요.
'많다'의 기준은 평소 내 서비스가 받는 최대 트래픽입니다.
문제?
서비스는 사용자를 만족시키기 위해 존재합니다.
따라서 사용자를 불만족시키는 모든 것이 '문제'라고 할 수 있습니다.
문제 키워드가 나온 김에 문제를 한 번 내보겠습니다.
Q. 트래픽이 많은 상황에서는 어떤 문제가 발생할까요?
- 서비스 처리 속도가 느려진다.
- 서버의 리소스 부족으로 인해 더 이상 사용자의 요청에 응답할 수 없다.
- 숨겨져 있던 버그로 인해 서버가 오작동한다.
정답은 '모두'입니다. (ㅋ)
일반적으로 '성능 테스트'라고 한다면 말 그대로 성능만을 생각하기 쉽지만,
위와 같은 문제들을 성능 테스트를 통해서 찾아낼 수 있고, 찾아내야 합니다.
중간 정리
이상을 정리해 보면,
성능 테스트란 1초당 요청이 가장 많은 상황을 기준으로 서비스에서 발생하는 성능, 가용성 관련 문제를 찾아내는 작업이라고 할 수 있겠습니다.
지하철 노선도 서비스의 성능을 테스트해보자
성능 테스트에 대해 어느 정도 이해가 됐다면, 저희 지하철 노선도 서비스로 돌아와서 성능 테스트를 진행해보도록 하겠습니다.
저희가 다루는 지하철 노선도 서비스는 다음과 같은 사용자 시나리오를 가진 아주 간단한 서비스입니다.
-
사용자는 경로 검색 페이지에 들어온다.
-
출발역과 도착역을 정하고 검색 버튼을 클릭한다.
-
최단 거리와 경로를 확인한다.
서버 구조
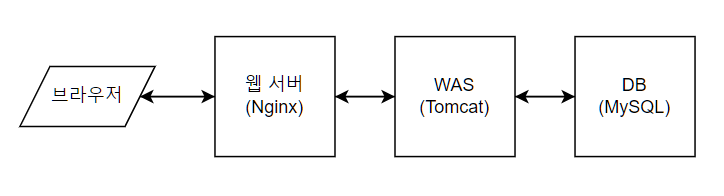
서버는 웹 서버 - WAS - DB로 이루어진 3 tier 형태의 간단한 구조를 갖고 있습니다.
테스트 계획짜기
테스트의 목표
목표 응답 시간은?
먼저 성능 튜닝 전에 성능 예산부터 구하자 에서 저희가 짰던 목표를 살펴보겠습니다.
| 경로 검색 페이지 | 경로 검색 결과 페이지 | |
|---|---|---|
| 최종 목표 | 최대 TTI 2s | 최대 LCP 3s |
| 웹서버의 정적 리소스 반환 | 최대 132ms | 최대 45ms |
| WAS 로직 처리 | 최대 27.8ms | |
| DB 조회 | 최대 65ms |
사용자가 가장 자주 쓰는 '경로 검색 페이지'와 '경로 검색 결과 페이지'의 성능을 개선하기로 했었고, 각 부분에 목표 응답 시간을 잡았었습니다.
이번 성능 테스트에서는 웹 서버와 WAS, DB 조회, 즉 브라우저를 제외한 뒷단 전체에 대해서 테스트를 하도록 하겠습니다.
따라서
경로 검색 페이지의 목표 응답 시간 = 132ms
경로 검색 결과 페이지의 목표 응답 시간 = 45 + 27.8 + 65 = 약 138ms입니다.
우리 서비스의 최대 트래픽은 얼마나 될까?
이미 오픈된 서비스라면 APM 툴을 이용해 최대 트래픽을 쉽게 알아낼 수 있겠지만,
저희는 아직 오픈하지 않았기 때문에 주요 경쟁사를 살펴보며 추측해보도록 합시다.
이 글 에 따르면 저희의 주요 경쟁사인 '네이버 지도'의 DAU(하루 중 중복 없는 순수 사용자 수)는 500만명입니다. 이 중 약 200만 명이 지하철 서비스를 이용하다고 가정하고 이를 기준으로 최대 트래픽을 예상해보도록 하겠습니다.
1일 총 요청 수
= DAU x 1명당 1일 평균 요청 수
= 200만 x 4(아침,저녁 각 2번 예상) = 800만
1일 평균 rps(request per second)
= 1일 총 요청 수 / 하루 12시간을 초로 환산
= 800만 / 43200 = 185rps
최대 트래픽
= 1일 최대 rps
= 1일 평균 rps x 피크 시간 집중률
= 185 x 5 = 925rps
여기서 피크 시간 집중률은 평균 트래픽보다 트래픽이 집중될 때는 몇 배나 많을지 예상하면 됩니다. 저는 지하철 노선도 서비스이기 때문에 출퇴근 시간에 평소 트래픽보다 5배가 많을 것 같아 5를 넣었습니다.
그래서 목표는?
- 사용자가 1초에 925번의 요청을 하는 상황에서 각 페이지가 132ms, 138ms 안에 제대로 된 응답을 하는지 테스트하고 문제점 찾기.
- 문제가 없다면, 서버의 최대 성능을 알아보기 위해 최대 트래픽을 넘어서는 부하를 주어가며 문제가 발생하는 지점 찾기
테스트 툴 정하기
성능 테스트를 진행하는 도구는 JMeter, nGrinder, K6 등 많은 도구가 있습니다.
어떤 것을 써도 상관은 없지만 다음 기준을 충족하는 툴을 쓰면 더 정확한 테스트를 진행할 수 있습니다.
- 시나리오 기반의 테스트가 가능해야 한다.
- 동시 접속자 수, 요청 간격, 최대 RPS 등 부하를 조정할 수 있어야 한다.
- 부하 테스트를 진행하는 Agent 서버의 스케일 아웃을 지원하는 등 충분한 부하를 줄 수 있어야 한다.
저는 위 3가지 조건을 만족하는 nGrinder와 K6 중에서 테스트 셋업이 간편하고 Grafana와 쉽게 연동하여 테스트 결과를 이쁘게 볼 수 있는 K6를 선택하였습니다.
테스트 환경
테스트 대상 스펙
웹 서버, WAS, DB 모두 AWS EC2 t3.medium을 사용하며 vCPU 2개, 메모리 4GB를 갖고 있습니다.
부하를 줄 장비(Agent)의 위치
성능 테스트는 실제 상황과 최대한 유사하게 진행해야 합니다. 만약 내부 네트워크에서 부하를 발생시킨다면 실제 상황과 응답시간에 차이가 발생할 수 있습니다.
따라서 저는 현재 서버가 위치한 망과 다른 망, 다른 AWS 데이터 센터에 부하를 줄 Agent를 위치시켰습니다. 망에 대한 설명은 인프라는 어떻게 구성해야 할까? 에 자세히 설명해 놓았습니다.
시나리오에 따라 테스트 스크립트 작성하기
테스트 스크립트에는 다음과 같은 것들이 필요합니다.
- 부하를 줄 가상 사용자 수(Vuser)
- 부하 시간
Vuser 구하기
동시 사용자는 사이트를 띄워놓고 콘텐츠를 보고 있는 Concurrent User와, 요청을 보내고 요청 처리를 기다리고 있는 Active User로 나누어 볼 수 있습니다. Vuser는 지속해서 요청을 보내기 때문에 Active User를 묘사한다고 보시면 됩니다.

Vuser 계산 공식
Vuser = 목표rps x (한번의 시나리오를 완료하는데 걸리는 시간) / (시나리오 당 요청수)
Vuser = 목표rps x (요청1 목표 시간 + think time1+ 요청2 목표 시간 + think time2+ .. +N) / N
Think time이란 현실 상황을 최대한 반영하기 위해 행동 사이 사이에 존재하는 대기 시간을 의미합니다. 이를 테면 현실 상황에서는 경로 검색 페이지를 요청하고 1초 동안 이것 저것하다가 경로 검색 페이지 결과를 요청하겠죠. 여기서 1초가 Think time입니다.
Think time이 길수록 목표한 rps를 만들어내기 위해 필요한 Vuser가 많아집니다. Vuser가 많아질 경우 웹 서버와 동시에 맺는 커넥션이 증가합니다. 또한 한 번에 몰릴 수 있는 요청 또한 증가하게 되므로 같은 rps 상황을 만들었다고 하더라도 Vuser가 많을 때의 rps가 더 심한 부하를 주고 있다고 할 수 있습니다.
따라서 Think time을 최대한 현실 상황에 가깝게 잡고 그에 따라 Vuser를 늘리는 것이 좋습니다. 하지만 하나의 K6 서버가 만들어낼 수 있는 부하에는 한계가 있고, Vuser가 증가함에 따라 K6 Agent도 여러대가 필요해 테스트가 복잡해지므로 이번 테스트에서는 Think time을 0으로 잡도록 하겠습니다.
그럼 저희 서비스의 Vuser를 계산해보도록 하겠습니다.
Vuser
= 925rps x (경로 검색 목표 응답 시간 + think time + 경로 검색 결과 목표 응답 시간) / 요청 수
= 925rps x (0.132 + 0 + 0.138) / 2
= 125명
Vuser 계산 공식이 왜 그렇게 되는지에 대해서는 부록에 넣어놓겠습니다.
부하 시간
일반적으로 성능 테스트를 진행할 때는 30분 ~ 2시간 사이로 진행하게 됩니다. '내구성 테스트'라고 하여 굉장히 오랜 시간 동안 테스트하는 테스트도 있지만 시간이 오래 걸리기도 하고 귀찮기도 하여 현업에서는 잘 사용되지 않습니다.
저희는 평소 트래픽 상황에서 10분, 최대 트래픽 상황에서 30분간 테스트를 진행하도록 하겠습니다.
테스트 스크립트 작성
K6에서 테스트 스크립트는 Javascript로 작성할 수 있습니다. 각 요소에 대한 자세한 설명은 여기에 있습니다. 설명히 친절하게 되어 있어 빠르게 감을 잡으실 수 있습니다.
load.js
import { URL } from 'https://jslib.k6.io/url/1.0.0/index.js';
import http from 'k6/http';
import { check, group, sleep, fail } from 'k6';
export let options = {
stages: [ // 테스트 단계, 아래에 설정된대로 테스트가 진행된다.
{ duration: '3m', target: 25 }, //먼저 3분 동안 VUser 1에서 25까지 서서히 올린다.
{ duration: '10m',target: 25 }, //Vuser 25에서 10분간 유지한다.
{ duration: '3m', target: 125 }, //다시 3분간 25에서 125까지 서서히 올린다.
{ duration: '30m',target: 125 }, //30분간 유지
{ duration: '3m', target: 0 }, //3분 동안 Vuser 0으로 내려온다.
],
thresholds: { // 부하 테스트가 언제 성공했다고 할 수 있는지
http_req_duration: ['p(95)<138'], // 전체 요청의 95%가 138ms 안에 들어오면 성공
},
};
const BASE_URL = 'https://www.subway-sgo8308.o-r.kr';
const STATION_COUNT = 16;
function getRandomStationId(){
return Math.floor(Math.random() * STATION_COUNT) + 1;
}
function getPath(){
let pathRes = http.get(`${BASE_URL}/path`, {
tags: {
page_name: "get_path", // tag에 따라 결과를 볼 수 있게 tag이름을 get_path로 지정
},
}); // get요청을 진행하고 결과를 리턴
check(pathRes, { // 결과를 체크
'success to get path': (res) => res.status === 200,//응답 상태코드가 200이면 성공
});
}
function getPathResults(){
var url = new URL(`${BASE_URL}/paths`);
var sourceId = getRandomStationId();
var targetId = getRandomStationId();
url.searchParams.append('source', sourceId);
url.searchParams.append('target', targetId);
//최종 url 형태 : https://subway-sgo8308.o-r.kr/paths?source=1&target=10
let pathResultRes = http.get(url.toString(), {
tags: {
page_name: "get_path_result",
},
});
check(pathResultRes, {
'success to get path results': (res) => "stations" in res
});
}
export default function () {//이 default 함수만 테스트동안 계속 실행, 나머지는 1번만
getPath(); // 경로 검색 페이지를 Get요청하고
getPathResults(); // 경로 검색 결과 페이지를 Get요청한다.
};
stress.js
import { URL } from 'https://jslib.k6.io/url/1.0.0/index.js';
import http from 'k6/http';
import { check, group, sleep, fail } from 'k6';
export let options = {
stages: [
{ duration: '1m', target: 100 },
{ duration: '3m',target: 100 },
{ duration: '1m', target: 200 },
{ duration: '3m',target: 200 },
{ duration: '1m', target: 300 },
{ duration: '3m',target: 300 },
{ duration: '1m', target: 400 },
{ duration: '3m',target: 400 },
{ duration: '1m', target: 500 },
{ duration: '3m',target: 500 },
{ duration: '1m', target: 0 },
],
thresholds: {
http_req_duration: ['p(95)<138'],
},
};
... 이하 load.js와 동일뭔가 대단한 것은 없습니다. 그냥 우리가 코드 짠대로 설정한 시간만큼 무한루프를 돌릴 뿐입니다.
참고로 최대 트래픽에서 발생하는 문제를 찾는 테스트를 load test라고 부르고, 최대 트래픽 이상의 부하를 주어가며 시스템의 한계에서 발생하는 문제를 찾는 테스트를 stress test라고 부릅니다. 위 스크립트의 load.js와 stress.js는 각각 load test와 stress test를 의미합니다.
테스트 진행하기
K6 다운로드
부하를 주기 위한 EC2를 하나 생성하고 K6 다운로드 가이드를 보고 K6를 다운 받습니다.
우분투는 다음을 입력하면 바로 다운받을 수 있습니다.
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys C5AD17C747E3415A3642D57D77C6C491D6AC1D69
$ echo "deb https://dl.k6.io/deb stable main" | sudo tee /etc/apt/sources.list.d/k6.list
$ sudo apt-get update
$ sudo apt-get install k6K6 실행
K6를 실행합니다.
k6 run load.js이 때 CPU, 메모리, 디스크 I/O, 네트워크 I/O와 같은 서버 리소스에 대한 모니터링도 같이 진행하면 문제의 원인을 더 빠르게 파악할 수 있습니다.
대시보드 구성
Grafana와 InfluxDB를 이용하면 시간에 따른 결과를 그래프로 더 이쁘게 볼 수 있습니다. 성능 테스트를 진행하면서 생성된 기록들을 InfluxDB라는 시간에 따른 데이터를 저장하는데 특화된 DB에 저장합니다. 이 후 Grafana에서 해당 데이터들을 이용해 그래프로 표현합니다.
대시보드 연결하는 법은 부록에 실도록 하겠습니다.
테스트 결과 분석하기
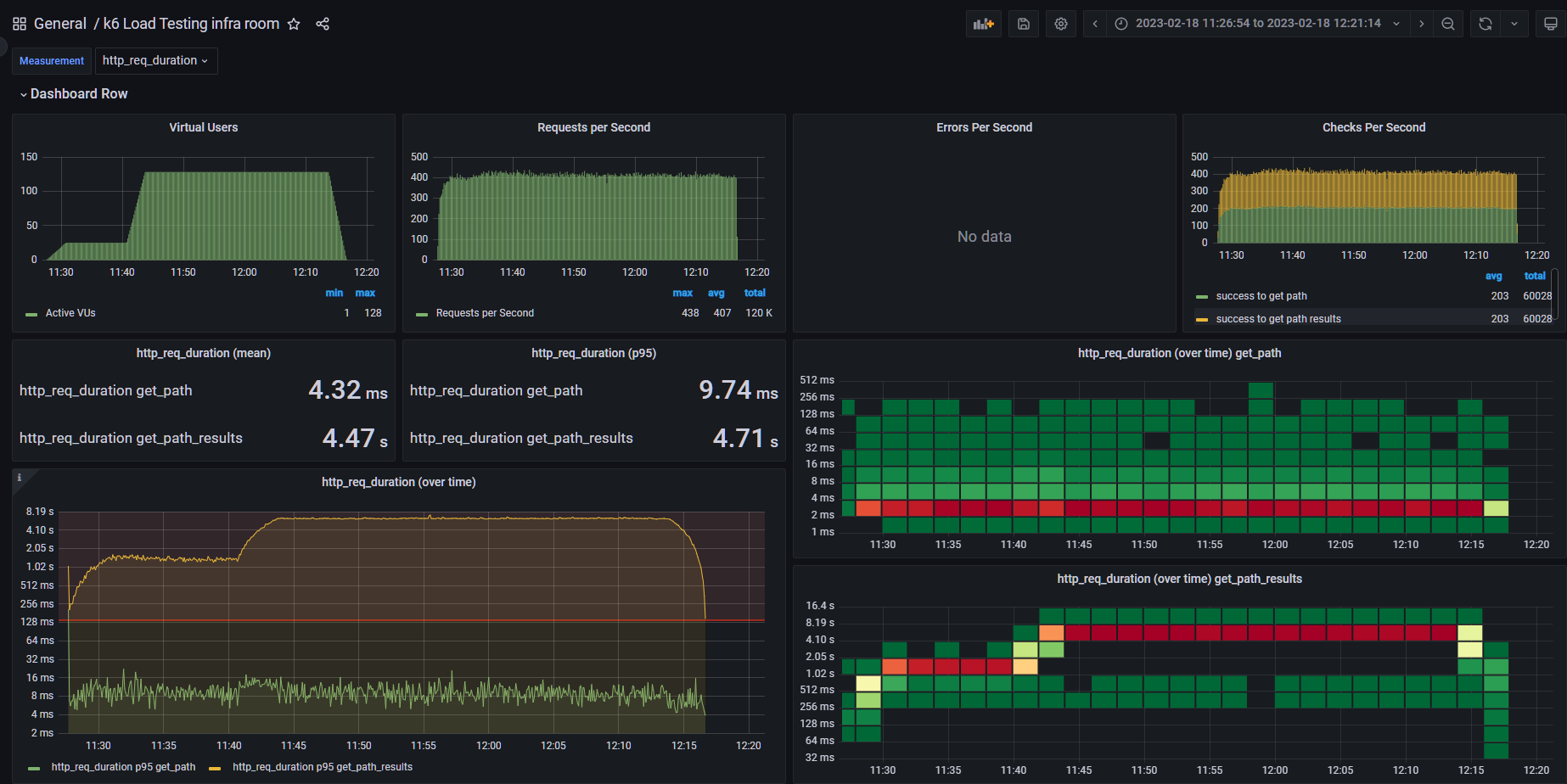
대시보드 해석
load test
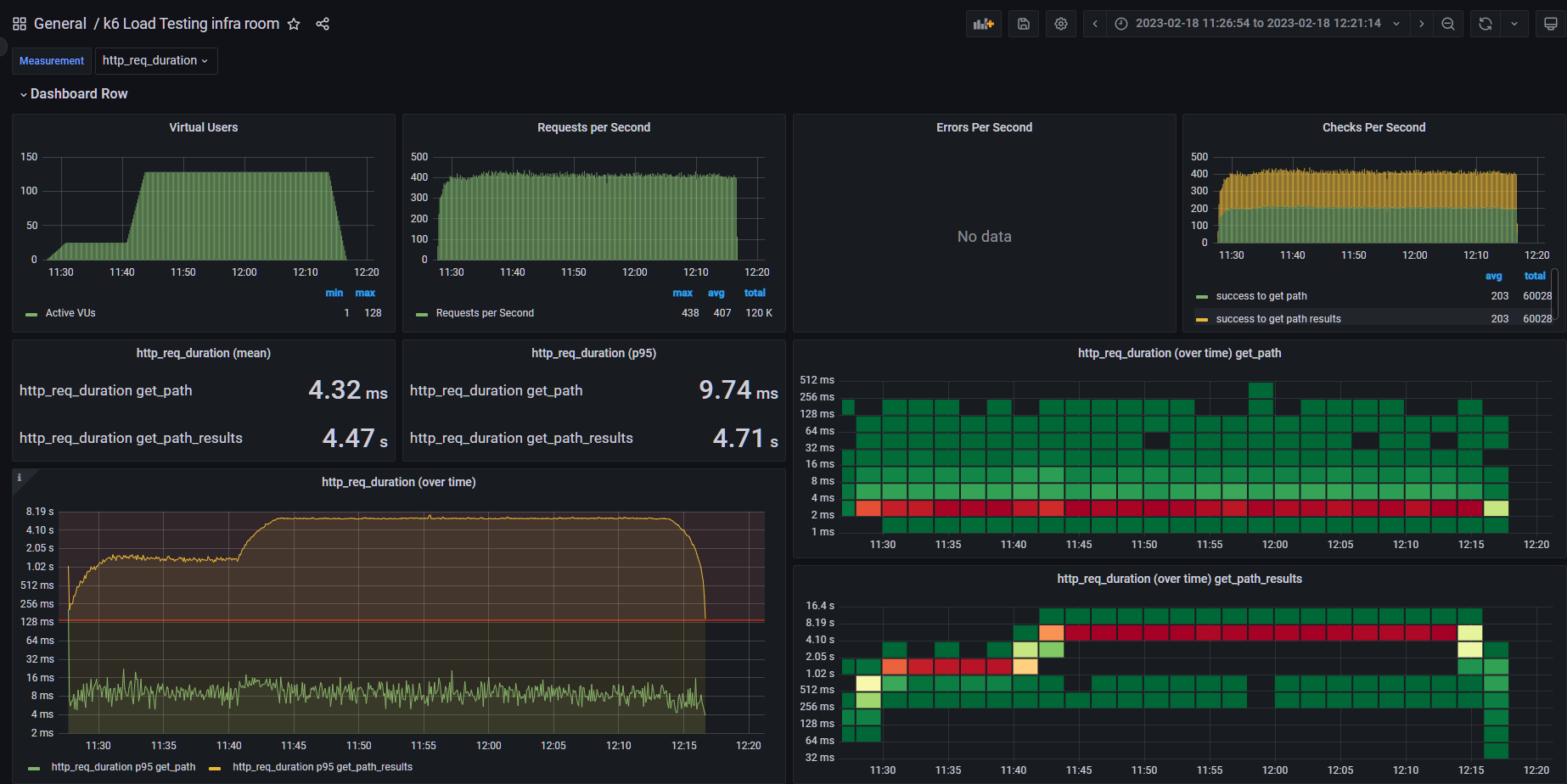
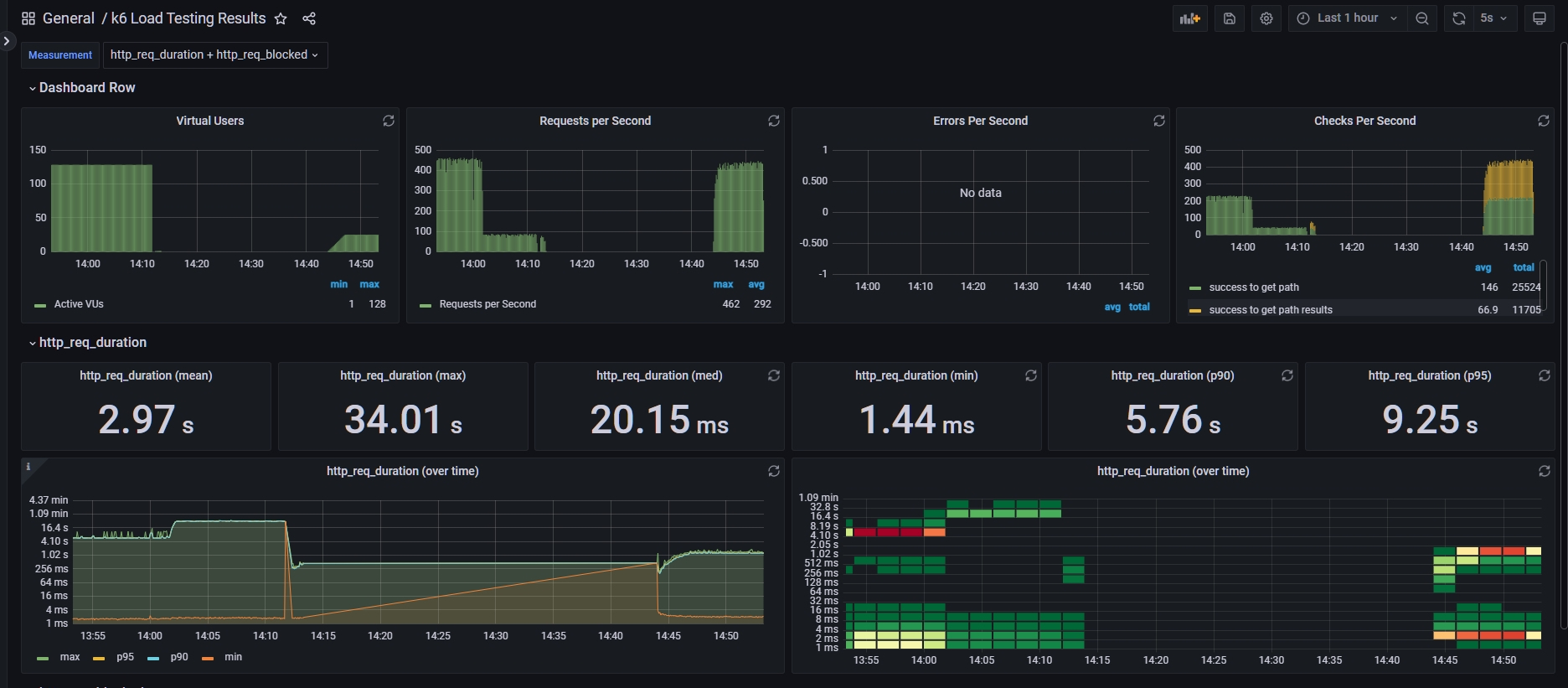
맨 왼쪽 윗편에 Virtual User는 말 그대로 가상 사용자 수를 나타냅니다. 저희가 스크립트 짠대로 잘 진행되었네요.
그 다음의 Request Per Second는 초당 K6 Agent가 요청한 수를 의미합니다. Error Per Second와 Checks Per Second는 각각 실패한 응답 성공한 응답 등을 나타냅니다.
그 아래의 저희의 주요 지표인 HTTP 요청을 처리하는 시간이 통계적으로 나옵니다. 이 처리 시간은 K6 Agent가 요청을 보내고 나서 받기까지의 시간입니다.
그 아래의 그래프는 이 HTTP 요청을 처리하는 시간을 그래프로 표현한 것이고 오른쪽의 타일들은 각 응답 시간 구간에 얼마나 많은 요청이 처리되었는지를 나타냅니다.
목표 응답 시간을 지키지 못하고 있다
load test
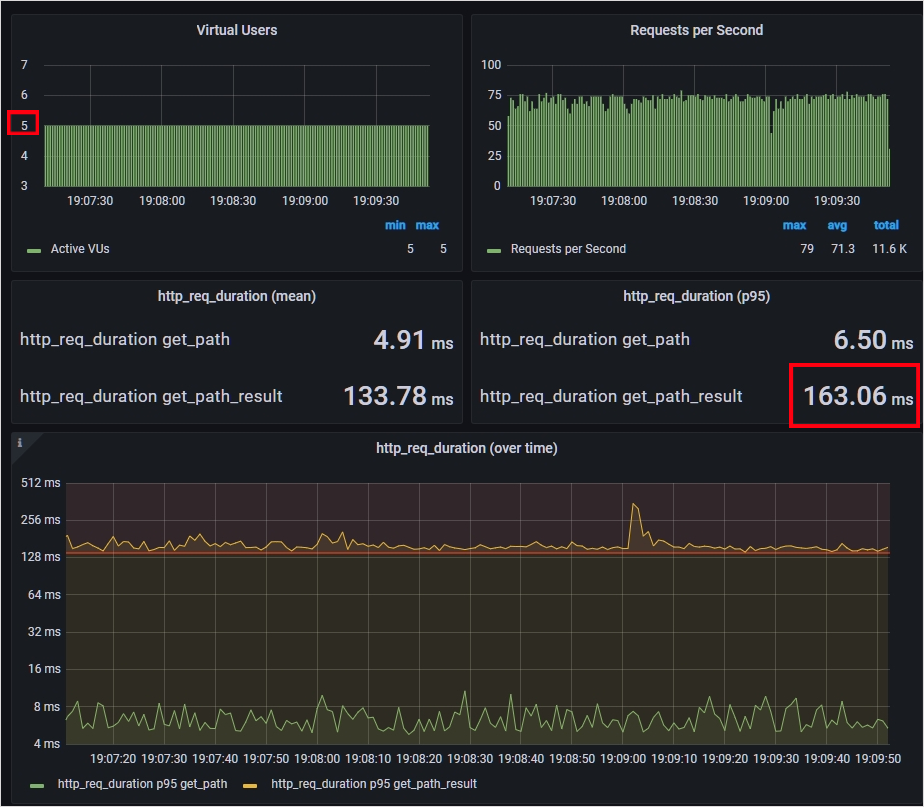
줌을 땡겨서 좀더 들어가보겠습니다. 아래 그래프에 빨간 수평줄이 138ms를 가르킵니다.
경로 검색 페이지는 목표 응답 시간을 충분히 달성하고 있지만, 경로 검색 결과 페이지는 고작 Vuser 5명부터 목표 응답 시간을 전혀 지키지 못하고 있습니다.
요청이 대규모로 실패하기 시작하는 구간 발견
stress test
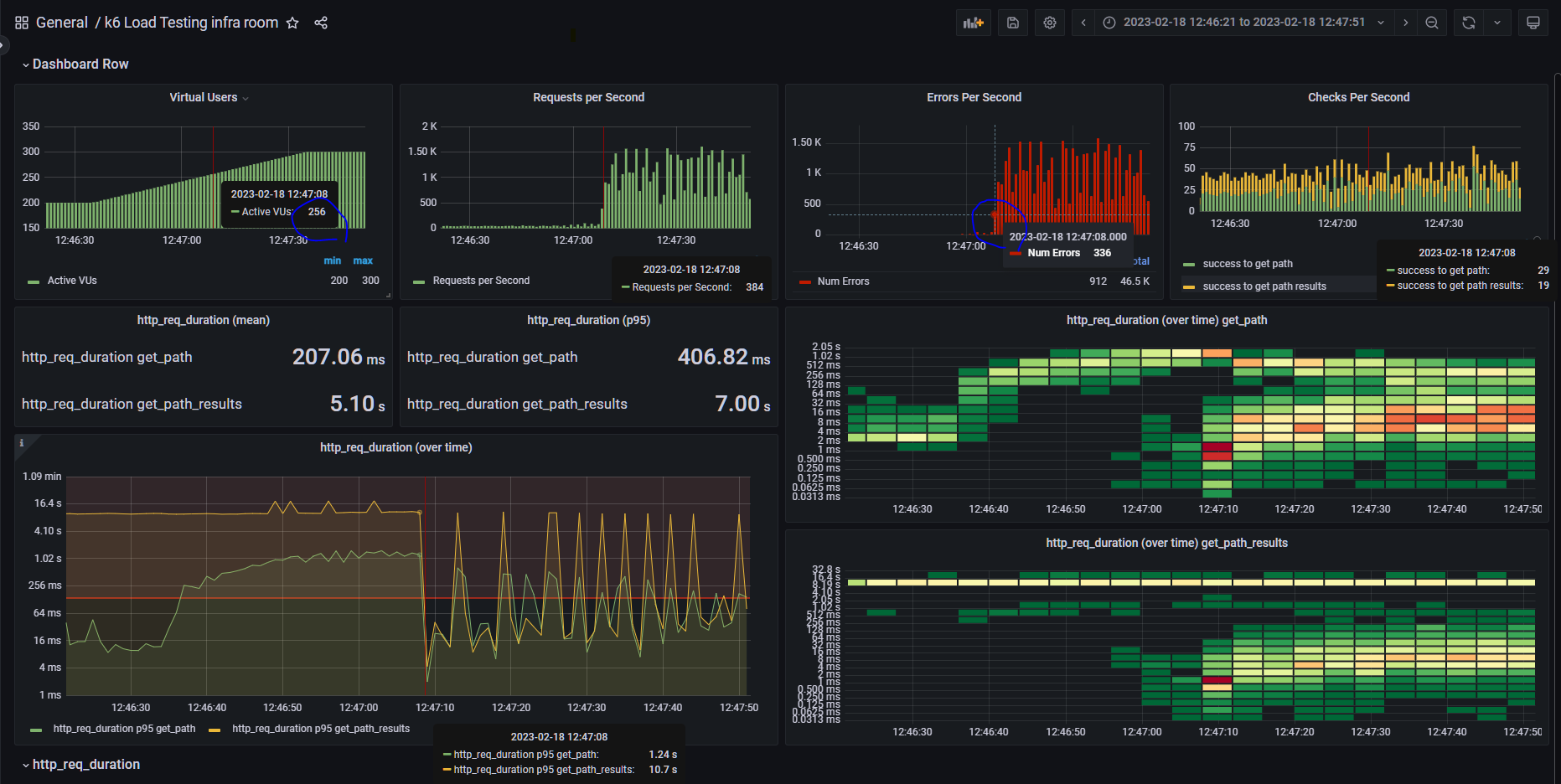
스트레스 테스트를 보면 동시 사용자가 약 250명이 넘어가는 순간부터 요청이 대규모로 실패하고 있습니다.
결과 정리하기
결과에는 현재 서버의 성능(응답 시간과 RPS), 테스트 과정에서의 리소스 사용량 그리고 가장 중요한 찾아낸 문제점 등을 정리해주면 좋습니다.
현재 서버의 성능
stress test의 구간을 좁혀서 보면, Vuser 100인 상황에서 5분간 21600개의 요청을 처리했습니다.

따라서 Vuser가 100인 상황에서 저희 서버의 성능은 21600 / 300 = 72rps 또는 72tps(Transaction Per Second)라고 할 수 있습니다.
이런 방식으로 저희 서비스의 성능을 표현하도록 하겠습니다.
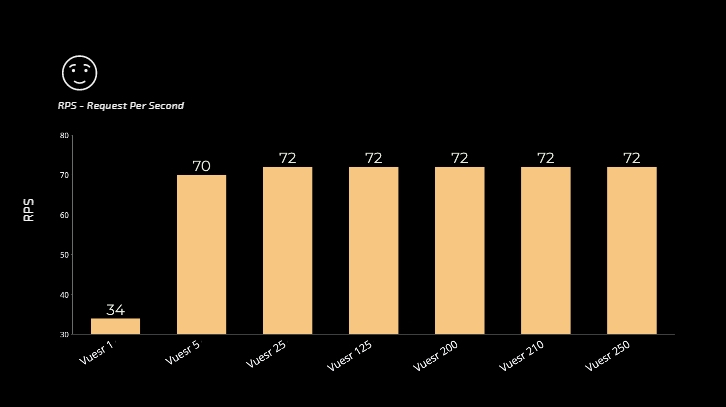
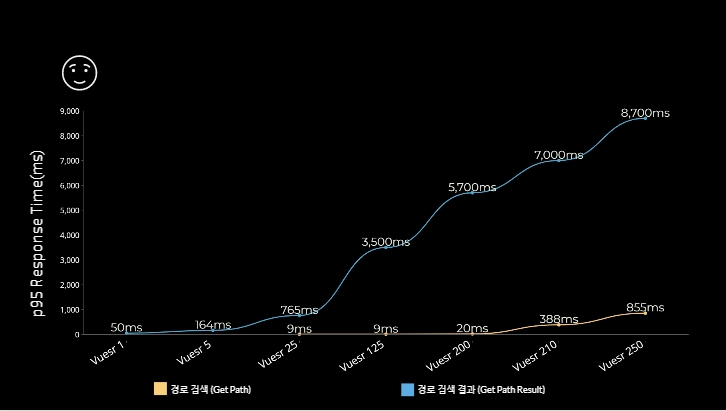
목표로 한 RPS 외에도 특별히 변화가 생기는 부분들에 대해서 좀 더 길게 테스트하고 기록하였습니다. Vuser가 200이 넘어가는 순간부터 경로 검색 페이지의 응답 시간 또한 매우 빠르게 올라가는 것을 보실 수 있습니다.
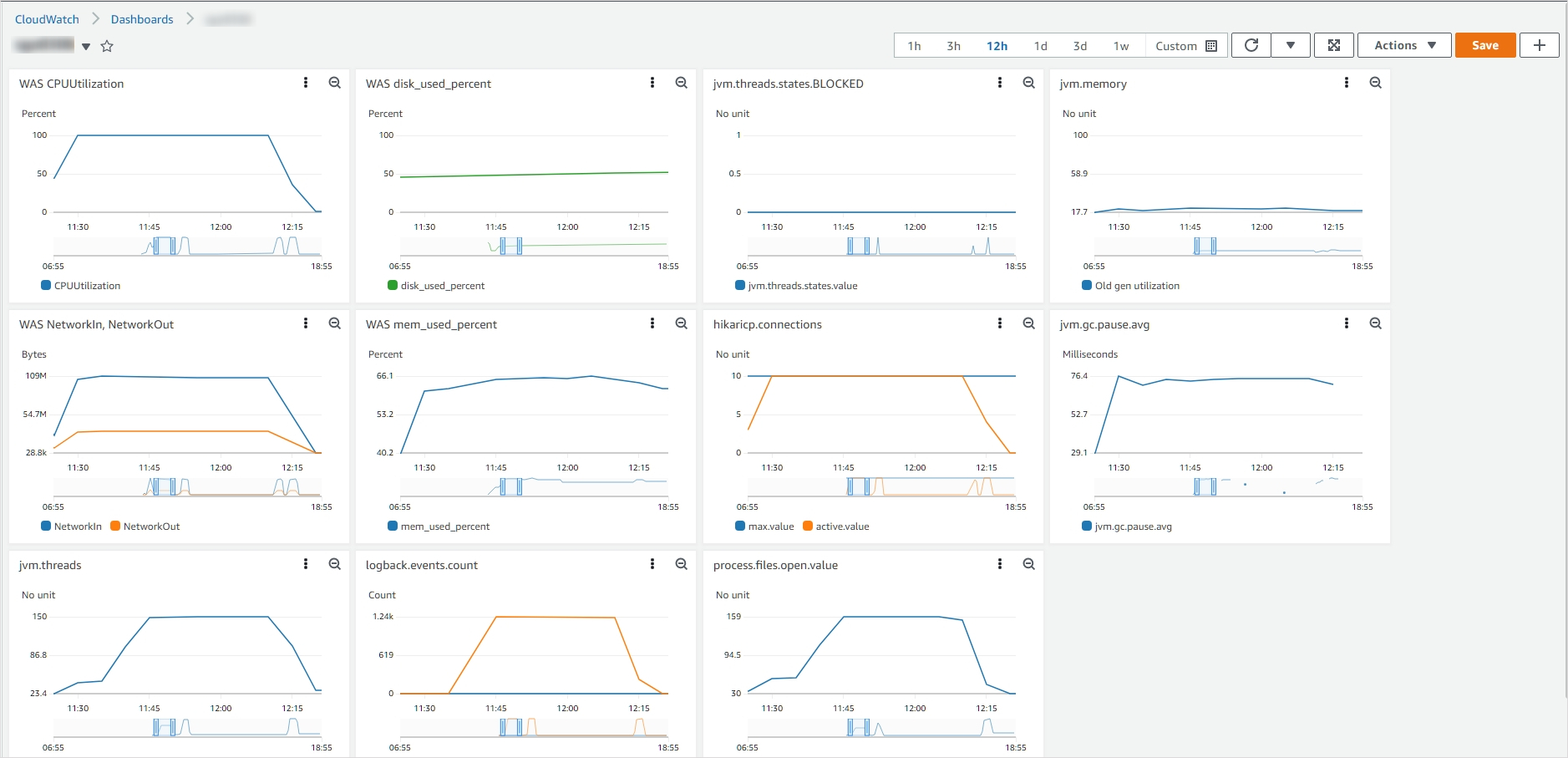
테스트 과정에서의 리소스 사용량
load test
stress test
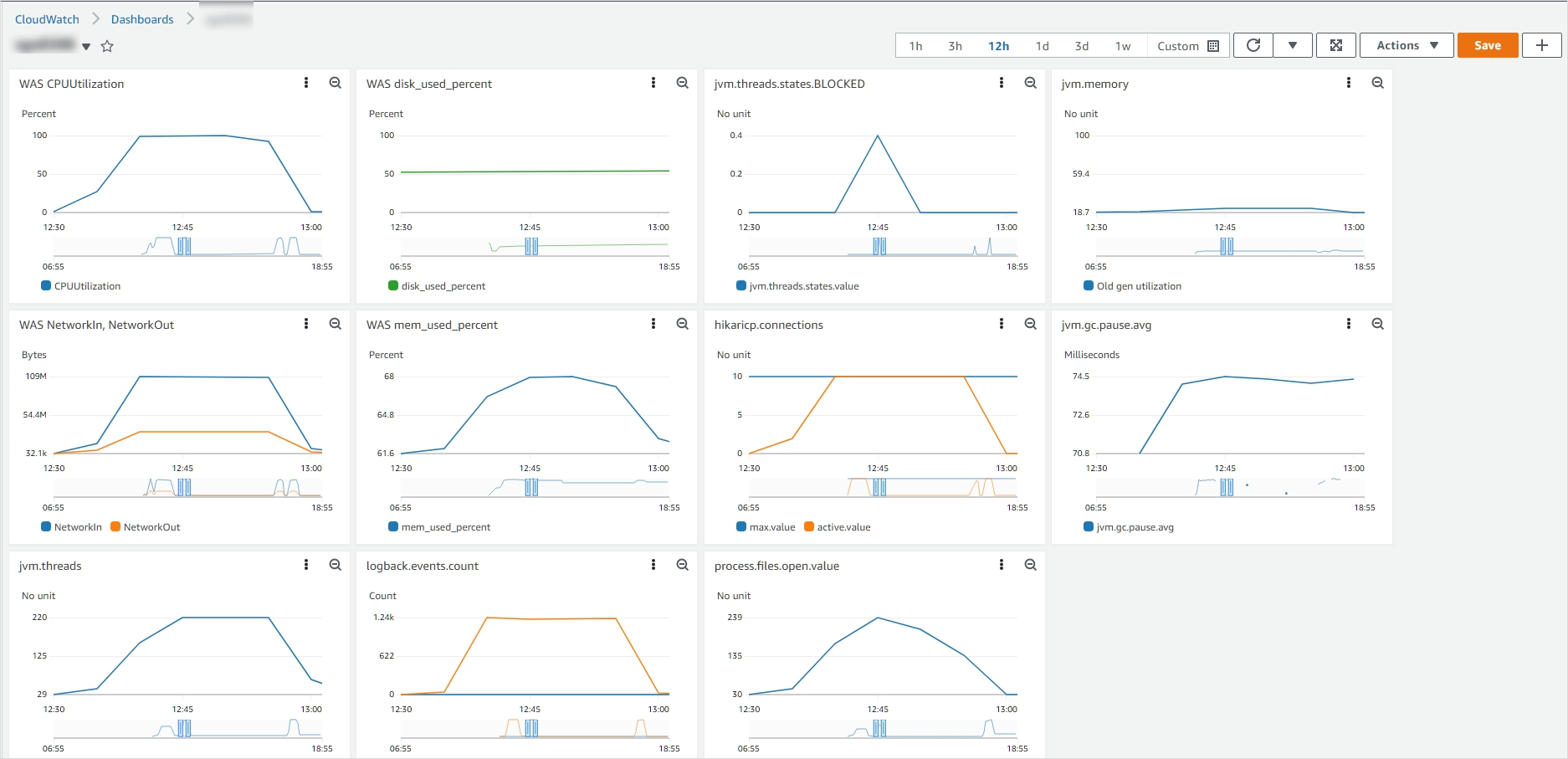
+Web Server나 DB의 리소스 사용량도 같이 보시면 좋아요.
찾아낸 문제점
- Vuser 5명부터 경로 검색 결과 페이지의 목표로 한 응답 시간을 달성하지 못함.
- Vuser 200명부터 경로 검색 페이지의 갑작스런 응답 시간 증가.
- Vuser 약 250명부터 요청이 대규모로 실패하기 시작.
과연 문제의 원인은 무엇일까요?
다음 글에서는 JVM 기반의 WAS에서 발생할 수 있는 여러 문제 상황과 그 원인에 대해서 알아보고, 이번 성능 테스트로 찾아낸 문제의 원인은 무엇이었을지 알아보도록 하겠습니다 :)
부록
Vuser 계산 공식 설명
Vuser 계산 공식
Vuser = 목표rps x (한번의 시나리오를 완료하는데 걸리는 시간) / (시나리오 당 요청수)
Vuser = 목표rps x (요청1 목표 시간 + think time1+ 요청2 목표 시간 + think time2+ .. +N) / N
Vuser는 결국 목표한 트래픽 상황을 만들어내기 위해 필요합니다. 따라서 목표한 트래픽 상황을 만들어냈는지? 아닌지?를 기준으로 생각해보면 계산하기 용이합니다.
다음 예제를 기준으로 설명해보겠습니다.
목표 rps : 100rps
get 요청 1의 목표 응답 시간 : 0.1s
요청1과 2 사이의 think time : 0.8s
get 요청 2의 목표 응답 시간 : 0.1s
저희는 100 rps 상황을 만들어야 합니다.
즉 Vuser들이 1초에 100번의 요청을 보내야 합니다.
저희가 목표한 응답 시간에 맞추어 응답을 할 수 있다면 Vuser 1명은 1초 (0.1 + 0.8 + 0.1)에 두 번씩 요청보낼 수 있습니다.
따라서 Vuser가 50명이면 1초 동안 50개의 요청을 보낼 수 있습니다.
공식 자체로 설명해보면,
Vuser 수 x (1초당 요청 횟수) = rps
Vuser 수 = rps x ( 1 / (1초당 요청 횟수) )
Vuser 수 = rps x (요청 하나당 걸리는 평균 시간)
Vuser 수 = rps x (한번의 시나리오를 완료하는데 걸리는 시간) / (시나리오 당 요청수)
Grafana + InfluxDb를 이용해 대시보드 구성하는 법
이 가이드와 아래 가이드를 참고해서 구성해 봅니다.
- K6를 다운 받은 컴퓨터에 InfluxDB를 설치한다.
- InfluxDB를 실행한다.
$ nohup influxd 1>influxdb.log 2>&1 &-
Grafana를 내 로컬 컴퓨터에 다운로드 한다. (이렇게 로컬로 쓰면 무료이고 클라우드로 쓰면 유료입니다.)
-
브라우저로 http://localhost:3000 에 접속한다.
-
로그인 화면이 뜨면 id : admin pw : admin을 입력하고 들어간다.
-
Add Datasource를 찾아서 클릭하고 influxDB를 아래와 같이 등록한다.
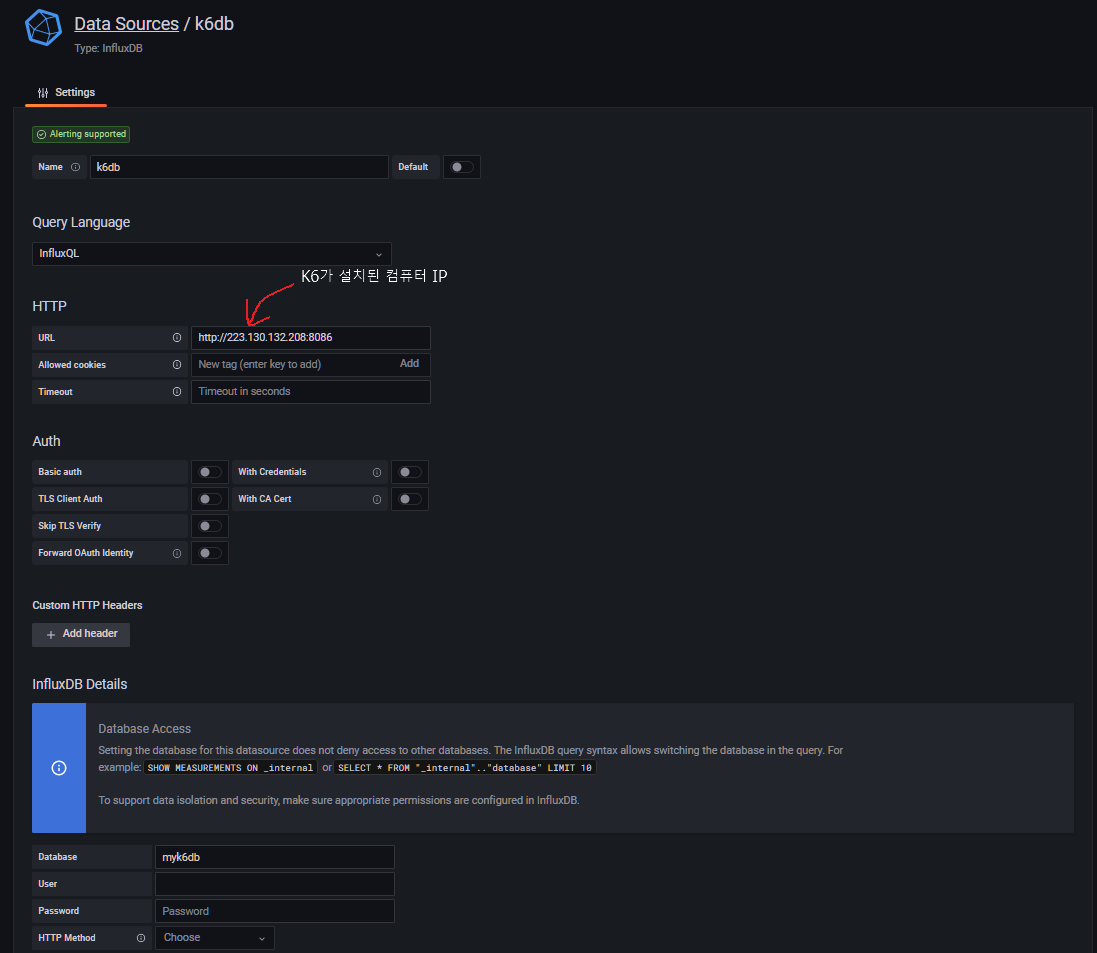
-
미리 만들어져 있는 대시보드를 import 해준다.
* Dashboards > import > Grafana.com Dashboard 항목에 2587입력하고, datasource로 influxdb를 설정한 후 import -
테스트를 수행하고 결과 데이터를 InfluxDB로 넣는다. (myk6db라는 데이터베이스를 만들지 않아도 알아서 K6가 만듭니다.)
$ k6 run --out influxdb=http://localhost:8086/myk6db script.js- 넣어진 데이터들이 아래와 같이 Grafana를 통해 예쁘게 출력된다.
현재 K6 대시보드가 업데이트된지 오래된 관계로 Error Per Second 부분은 출력이 안됩니다. Error Per Second의 판넬 설정 들어가서 쿼리를 아래와 같이 만지면 제대로 보실 수 있습니다.
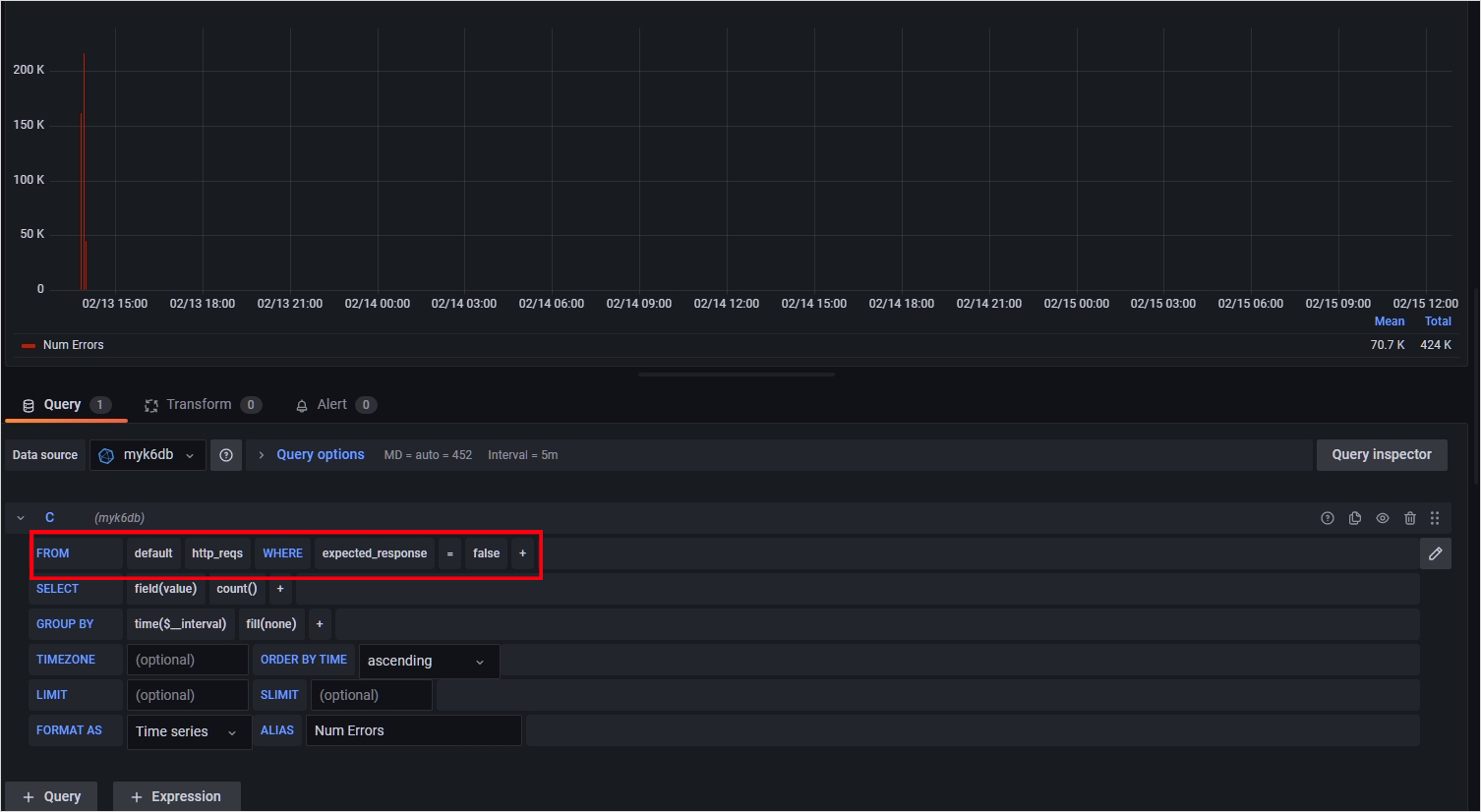
만약 제 결과의 대시보드와 동일하게 구성하고 싶으시다면 Grafana.com Dashboard 항목에 2587 대신 18105를 넣어주면 됩니다.
Reference
넥스트스텝 - 인프라 공방
이상민, 자바 개발자도 쉽고 즐겁게 배우는 테스팅 이야기, 한빛미디어, 12장-15장, 2009
Calculating RPS with K6
Think Time






막연했던 성능테스트에 고민의 방향성과 이미지를 제공해 주셨습니다. 대단히 감사합니다.