
성능 개선 시리즈
- 성능 목표 잡기
- 성능 테스트 진행하기
- 문제 원인 파악하기
- 성능 개선하기
성능 개선의 본질
우리 시스템의 성능 목표가 1초에 1만개의 요청이 들어오는 상황에서 95% 요청에 대하여 100ms 이하 시간 안에 응답을 내는 것이라고 해봅시다. 이를 달성하기 위해서는 먼저 단일 요청이 100ms 이하의 응답을 달성해야 합니다. 단일 요청이 100ms를 달성하지 못하면 부하가 심한 상황에서는 당연히 달성하지 못하겠지요. 단일 요청 성능이란 시스템에서 처리하는 요청이 단 하나인 경우의 응답 시간을 말합니다.
단일 요청의 성능을 개선하기 위해서는 비효율적인 프로세스를 개선해야 합니다. 예를 들어 더 낮은 시간 복잡도를 가진 알고리즘을 사용하거나, 매번 계산하는게 아니라 캐시를 사용해서 결과를 재사용하고, 기다릴 필요가 없는 작업은 비동기로 처리하는 것입니다.
여러가지 방법을 사용해서 단일 요청이 100ms 이하의 응답을 달성할 수 있도록 만들었다고 가정합시다. 이제 요청 수를 서서히 늘려가며 테스트해보면 응답 시간이 점점 늘어나는 것을 보게 됩니다. 이런 현상이 발생하는 이유는 요청 수가 늘어남에 따라 요청이 리소스를 얻기 위해 기다리는 시간이 늘어나기 때문입니다.
이전 글에서도 말씀드렸듯이 시스템에는 수많은 리소스가 존재합니다. 크게 CPU, 메모리, 디스크, 네트워크로 대표되는 하드웨어 리소스와 스레드, 커넥션, 락, 파일 디스크립터 등의 소프트웨어 리소스로 나누어볼 수 있었죠. 하나의 요청이 처리되기 위해서는 다양한 리소스가 필요하지만, 리소스는 한정되어 있기 때문에 리소스를 얻지 못한 요청은 기다려야 합니다.
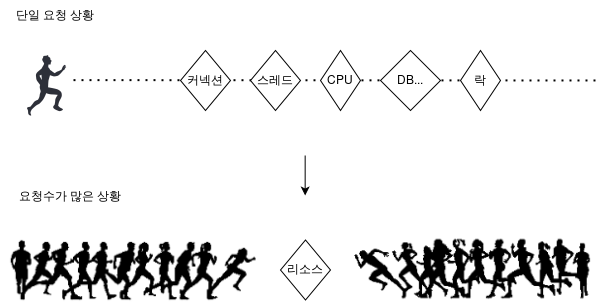
따라서 요청수가 많은 상황에서 떨어지는 성능을 개선하기 위해서는 각 요청의 리소스 대기 시간을 줄여야 합니다. 그리고 대기 시간을 줄이기 위해서는 각 요청이 리소스를 적게 사용하게 하고, 사용 가능한 리소스를 늘려야 합니다.
예를 들어 하드웨어 리소스 입장에서는 단일 요청 때처럼 알고리즘을 개선하여 CPU를 차지하는 시간을 줄일 수 있고, CPU 코어를 더 추가하거나 메모리 용량을 늘릴 수 있습니다. 소프트웨어 리소스 입장에서는 락 범위를 최소화(Lock Splitting)해 락을 잡는 시간을 짧게 가져가거나, 하나의 락을 여러개로 분할(Lock Striping)해볼 수 있습니다. 각각 리소스를 적게 사용하고 리소스를 늘리는 셈이죠.
정리하자면, 성능 문제의 원인은 '비효율적인 프로세스'와 '리소스에 대한 경쟁' 이고 성능 개선은 이 원인을 없애가는 과정입니다. 그리고 비효율적인 프로세스로 인해 가장 오래 걸리는 부분과 가장 리소스에 대한 경쟁이 심한 부분을 '병목 지점'이라고 부릅니다.
따라서 성능 개선의 본질은 '병목 지점'을 없애는 것이라고 할 수 있습니다.
지하철 노선도 서비스 성능 개선하기
먼저 현재까지 진행된 시리즈를 요약하겠습니다.
지하철 노선도 서비스는 사용자가 지하철 경로 검색 페이지에 들어와 출발지와 도착지를 입력하고 지하철 경로 검색 결과를 받아보는 서비스입니다.
서버는 웹 서버 - WAS - DB로 이루어진 3 tier 형태의 아키텍쳐로 이루어져 있으며 각 서버의 스펙은 AWS EC2 t3.medium vCPU 2개 Memory 4GB입니다.
경쟁사인 네이버지도와 카카오맵을 기준으로 다음과 같은 성능 목표를 세웠습니다.
서비스의 예상 최대 트래픽인 925RPS(Request Per Second) 상황에서
경로 검색 페이지의 목표 응답 시간 = 132ms
경로 검색 결과 페이지의 목표 응답 시간 = 138ms 를 달성하는 것.성능 테스트 결과 경로 검색 페이지는 목표 응답 시간을 이미 달성하고 있었고, 경로 검색 결과 페이지는 RPS가 70(Vuser가 5일 때)인 상황부터 목표를 지키지 못하고 있었습니다
그럼 지금부터 지하철 노선도 서비스의 병목 지점을 찾고 성능을 개선해보도록 하겠습니다.
병목 지점 찾기
병목 지점은 어떻게 찾을 수 있을까요? 단일 요청 상황에서의 병목 지점은 요청이 수행되는 각 과정 중 어떤 지점에서 시간이 많이 걸리는지를 파악해서 알아낼 수 있습니다.
이를 테면 직접 로깅을 통해 각 메소드에 걸리는 시간을 측정하는 것도 하나의 방법이 될 수 있습니다. 또 Tracing Tool이라 하여 이런 작업을 더 잘 해내는 툴이 존재하는데요. 대표적으로 Pinpoint가 있습니다.
요청이 많은 상황에서의 병목 지점은 모니터링을 통해 알아낼 수 있습니다. 여러 리소스들의 사용률을 파악해서 한계에 다다른 리소스를 식별하는 것이죠.
저는 Pinpoint를 이용해서 경로 검색 결과에 대한 단일 요청을 처리하는 과정에서 가장 오래 걸리는 부분을 찾아보도록 하겠습니다. (Pinpoint는 이 글에서 자세히 설명해주고 있어서 참고하시면 좋을 듯 합니다.)
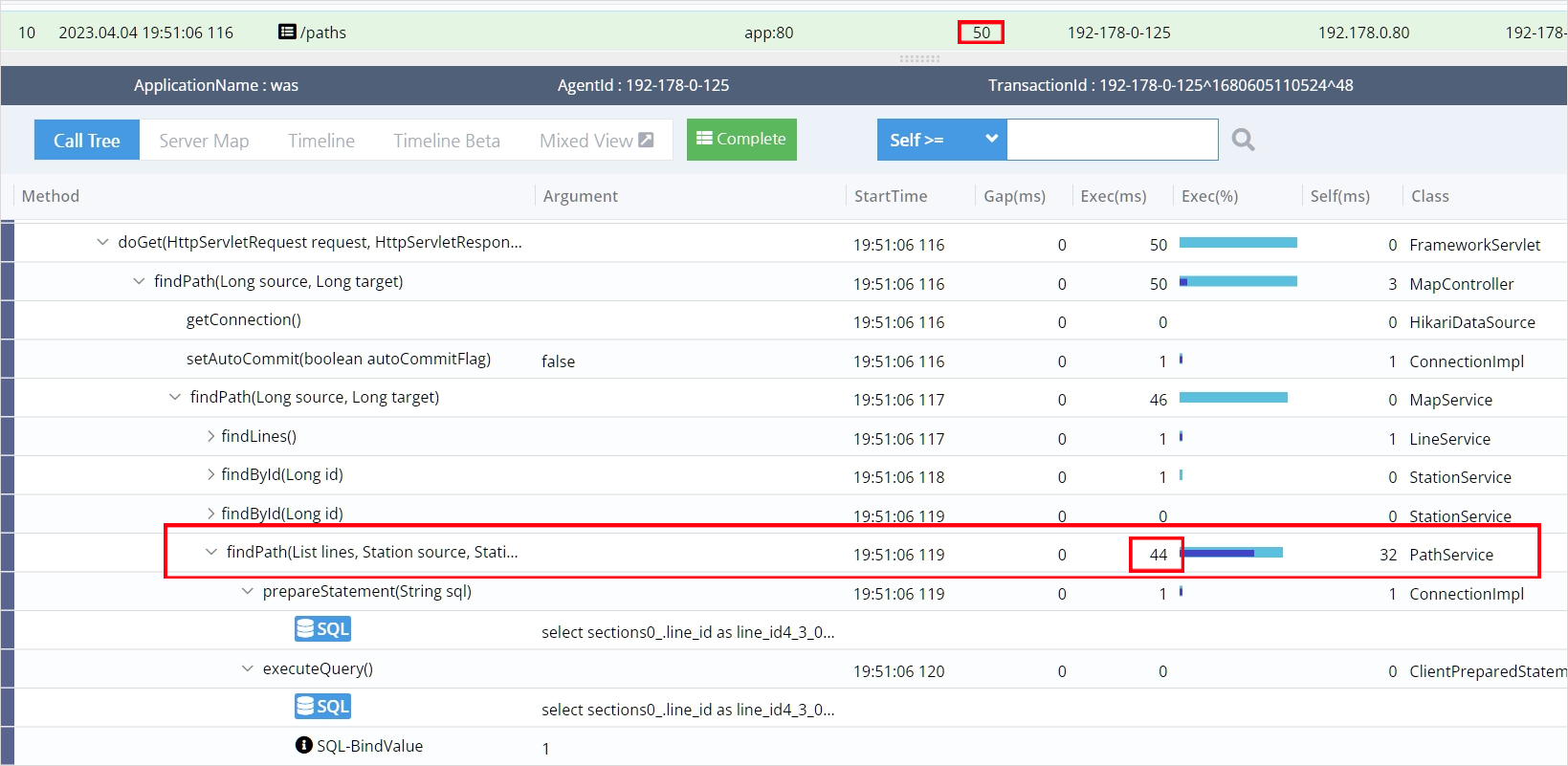
위 이미지는 Pinpoint에서 /paths의 경로로 오는 여러 요청 중 하나의 요청에 대해서 분석한 결과입니다. 이 요청에 응답하기 위해 수행된 각각의 메소드마다 걸린 시간을 보여줍니다.
이 요청을 처리하는데 총 50ms가 걸렸고 PathService 클래스의 findPath라는 메소드에서 무려 44ms나 차지한 것을 확인하실 수 있습니다.
경로 검색 결과는 출발역부터 도착역까지의 최단 거리와 그 사이에 거쳐가는 다른 역들로 이루어져 있습니다.
{
"stations": [
{
"id": 3,
"name": "용산"
},
{
"id": 4,
"name": "노량진"
},
{
"id": 5,
"name": "대방"
}
],
"distance": 12
}이 결과를 얻기 위해 각 노선(ex 4호선)에 등록된 모든 역들을 DB로부터 가져온 후 findPath() 메소드를 통해 가장 짧은 경로를 계산하게 됩니다.
이 때 다음 과정을 거치게 됩니다.
public PathResponse findPath(Long source, Long target) {
List<Line> lines = lineService.findLines();
Station sourceStation = stationService.findById(source);
Station targetStation = stationService.findById(target);
SubwayPath subwayPath = pathService.findPath(lines, sourceStation, targetStation);
return PathResponseAssembler.assemble(subwayPath);
}
List<Line> lines = lineService.findLines()- 모든 노선을 가져온다. => 쿼리 1번
SubwayPath subwayPath = pathService.findPath(List<Line> lines, ...)- 전달 받은 lines를 반복문을 돌면서 Line(노선)에 연결된 역들을 찾아온다.
=> 쿼리 23번(총 노선 수) - 모든 역들을 그래프에 할당하고 그래프를 바탕으로 다익스트라 알고리즘으로 최단 경로를 찾는다.
- 전달 받은 lines를 반복문을 돌면서 Line(노선)에 연결된 역들을 찾아온다.
이런 과정을 거쳐서 수많은 쿼리가 findPath 메소드에서 나가게 되고 그 과정에서 많은 시간이 걸리고 있었습니다.
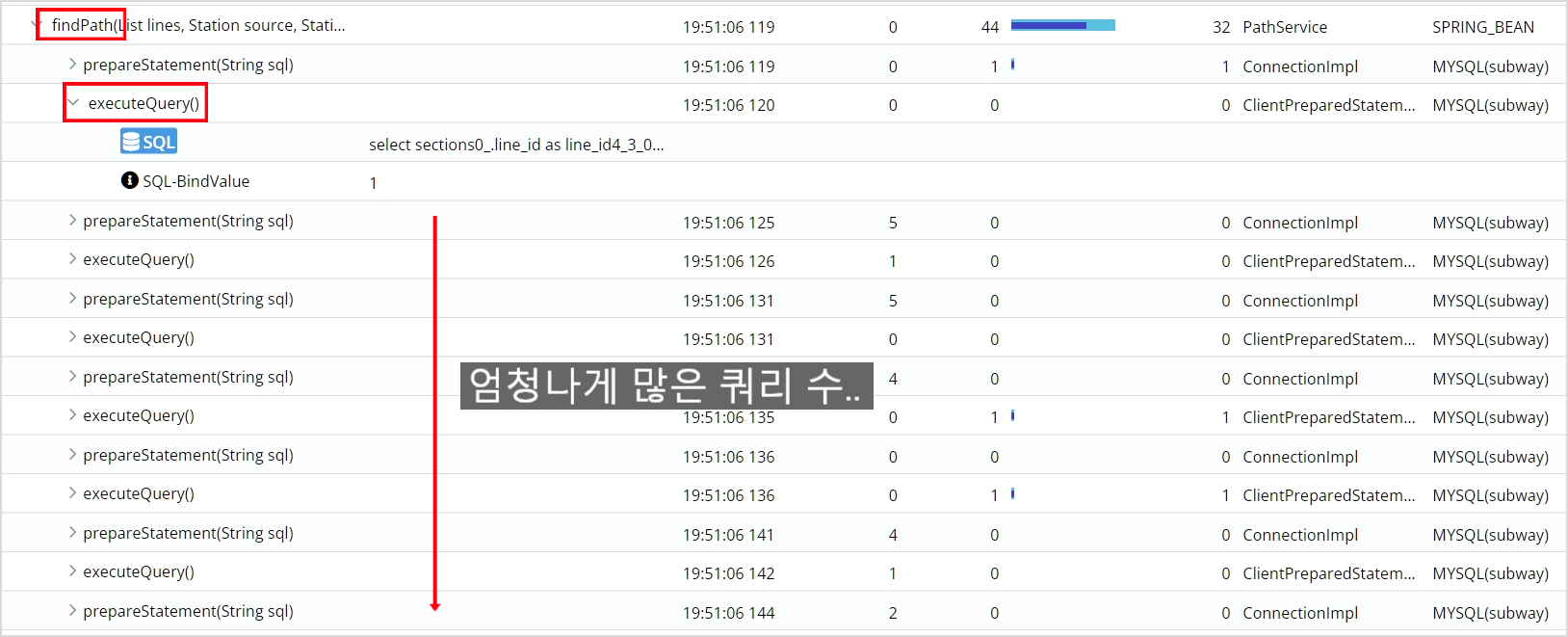
이 과정이 아무래도 비효율적으로 느껴지지 않나요? 23번이나 네트워크를 왕복합니다.
또 최단 경로를 매번 계산하는 것도 저는 비효율적으로 느껴집니다.
캐싱 대상은?
제가 생각할 때는 최단 경로 계산 결과를 메모리에 저장해 놓으면 훨씬 효율적일 것 같습니다. 계산했거나 이미 찾은 데이터를 다시 재사용하는 것, 아마 다들 아시겠지만 이런 것을 '캐싱'한다고 하죠.
캐싱 대상으로는 자주 접근하고, 변하지 않는 데이터가 적합합니다. 최단 경로 계산은 경로 검색 결과를 요청할 때마다 매 번 수행되고, 지하철 역은 자주 추가되거나 삭제되지 않기 때문에 계산 결과가 잘 바뀌지 않습니다. 따라서 최단 경로 계산 결과(PathResponse)는 캐싱 대상으로 적합해 보입니다.
어디에 캐싱할까? Local vs Remote
로컬 캐시는 캐싱을 WAS에 하는 것을 의미하고 리모트 캐시는 Redis나 Memcached 등 다른 캐시 서버에 캐싱하는 것을 의미합니다.
둘 사이의 선택의 기준은 결국 캐싱 대상 사이즈와 잦은 업데이트 여부로 귀결됩니다.
왜냐하면 로컬 캐시의 경우 WAS의 메모리에 저장하는 것이기 때문에 비교적 여유 공간이 적습니다. 캐시 사이즈가 너무 크게 되면 JVM 기반의 애플리케이션의 경우 GC 빈도가 늘어나 성능이 안 좋아질 수 있습니다.
또 로컬 캐시는 WAS가 여러 대인 상황에서 서로간의 캐시 동기화를 이루기가 까다롭습니다. 예를 들어 한 서버에서 캐싱 대상에 업데이트가 일어날 때 업데이트 사실을 각 서버에 전달하는 방식이라고 해봅시다. 그렇다면 매 업데이트마다 네트워크를 사용하게 되고, WAS가 늘어날수록 이 비용은 커질 것입니다. 만약 캐싱 대상에 대한 업데이트 사실을 알리지 않는 모델이라면 각 서버의 캐싱된 데이터가 얼마간 불일치 하게 됩니다. 따라서 캐싱 대상의 업데이트가 잦다면 로컬 캐싱은 어울리지 않습니다.
리모트 캐싱은 이러한 문제가 없죠. 대신에 리모트 캐싱을 적용할 경우 캐싱 저장소가 다운될 경우를 대비한 이중화 구성 등 시스템에 복잡도가 늘어납니다. 캐싱 저장소를 유지하는데 드는 비용 문제도 있습니다. 또 매번 캐싱 저장소에 네트워크를 타고 접근해야 하므로 로컬 캐싱에 비해 성능이 떨어집니다.
캐싱 대상의 사이즈는?
지하철 역 정보 같은 경우 업데이트가 정말 가끔 일어나기 때문에 저는 사이즈만 고려하였습니다.
수도권의 638개의 지하철 역을 각각 출발역,도착역으로 한 638 x 638 = 407044개의 결과를 모두 캐시에 등록 후 크기를 확인해보니 478MB를 차지하고 있었습니다.

(Intellij로 힙 덤프를 떴을 때의 이미지입니다.)
근데 478MB 정도면 로컬 캐시에 저장해도 되는 걸까요? 이게 큰건지 작은건지..
제 생각에는 478MB를 저장했을 때 애플리케이션 동작의 큰 무리가 없다면 괜찮다는 생각이 듭니다. 무리가 있다는 것은 캐시로 인해 가용가능한 힙 공간이 너무 작아 Full GC가 자주 일어나 애플리케이션 성능에 문제가 생기거나, OutOfMemoryError가 뜨는 경우겠죠?
하지만 Full GC가 자주 일어난다고 해도 추가적인 네트워크 접근이 없기 때문에 리모트 캐시보다 여전히 빠를 수도 있습니다. 결국은 로컬과 리모트 캐시를 둘 다 구현한 후 성능을 테스트해봐야 알 것 같다는 생각이 듭니다. 테스트 후 성능이 괜찮은 쪽을 선택하거나 비슷하다면 비용과 시스템 복잡도가 낮은 로컬 캐시를 사용하는 것이죠.
Local vs Remote 성능 테스트
로컬 캐시로는 가장 유명한 Caffeine 캐시와 리모트 캐시로는 가장 유명한 Redis를 이용하여 성능 테스트를 진행해 보겠습니다. Redis Client는 Spring의 default Redis Client인 Lettuce를 이용하겠습니다.
application-caffeine.yml - 로컬 캐시(Caffeine) - Spring Boot 설정
spring:
cache:
type: caffeine
caffeine:
spec: "maximumSize=500000,expireAfterWrite=3h"
cache-names:
- path로컬 캐시(Caffeine) - 성능 테스트 결과
application-redis.yml - 리모트 캐시(Redis) Spring Boot 설정
spring:
cache:
type: redis
cache-names: "path"
redis:
time-to-live: "3h"
redis:
host: 192.168.100.134
port: 6379
리모트 캐시(Redis) - 성능 테스트 결과
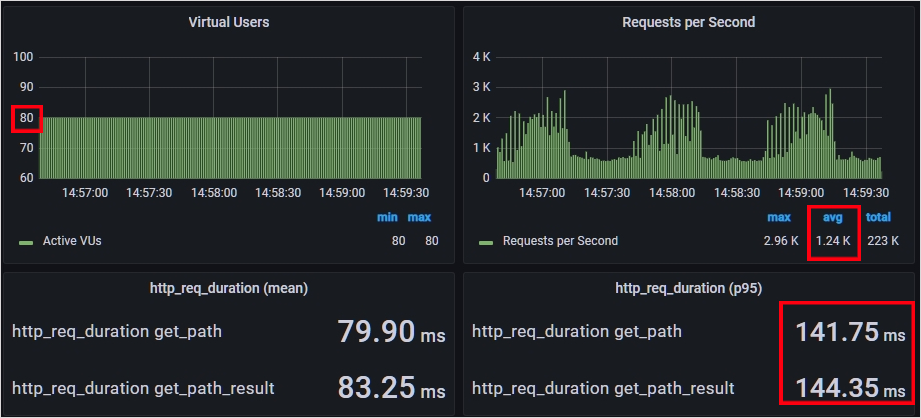
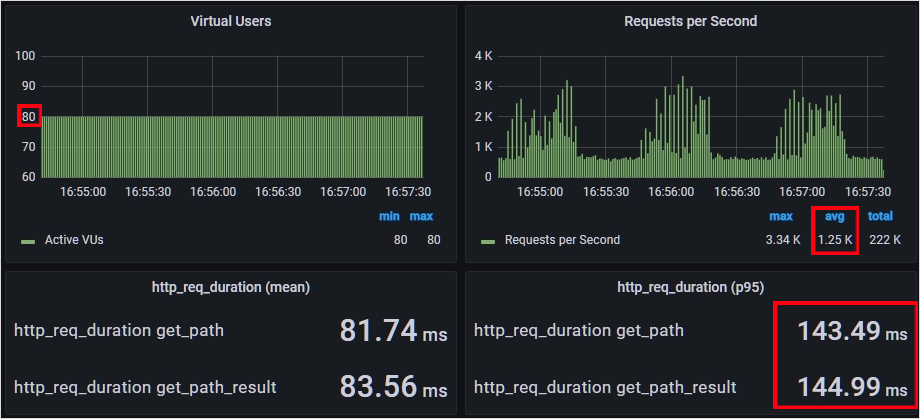
성능 테스트 결과 둘 다 비슷한 성능이 나왔습니다. 둘 다 Vuser 80, RPS 1250정도부터 목표 응답 시간인 138ms를 벗어났고, 최대 RPS도 1250이 한계였습니다.
현재 지하철 노선도 서비스는 G1GC를 사용하고 JVM의 힙 사이즈가 1GB로 설정되어 있는데요. G1GC의 경우 전체 힙 영역의 45%가 넘으면 Old 영역에 대한 GC 작업을 시작합니다. 캐시로 인해 힙 영역의 45%가 계속 넘어서 GC를 자주했을텐데, 리모트 캐시보다 크게 뒤떨어지지 않는 성능을 보여주었네요.
그런데 로컬 캐시 성능테스트를 진행하면서 힙 영역을 지켜보니 최대 800mb까지 차지되는 것을 볼 수 있었습니다.
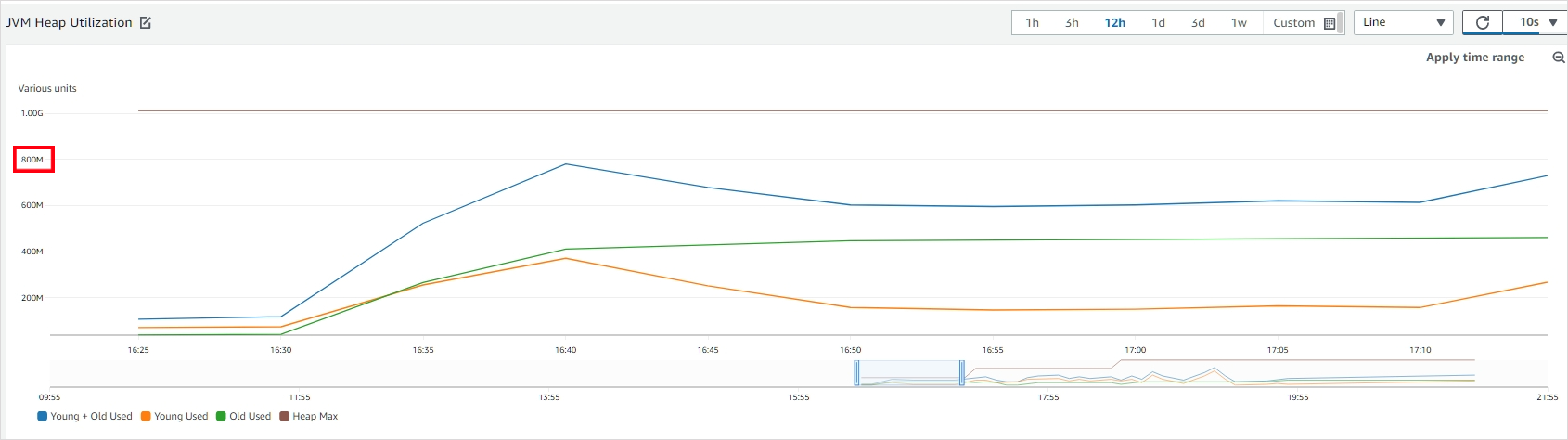
여유 공간으로 200MB만 남는 것은 아무래도 부족하다 생각해 힙 영역을 늘려보면서 테스트를 더 진행했습니다. 2GB와 3GB를 이용해 테스트했고 결과적으로 3GB일 때 가장 성능이 가장 좋았습니다.

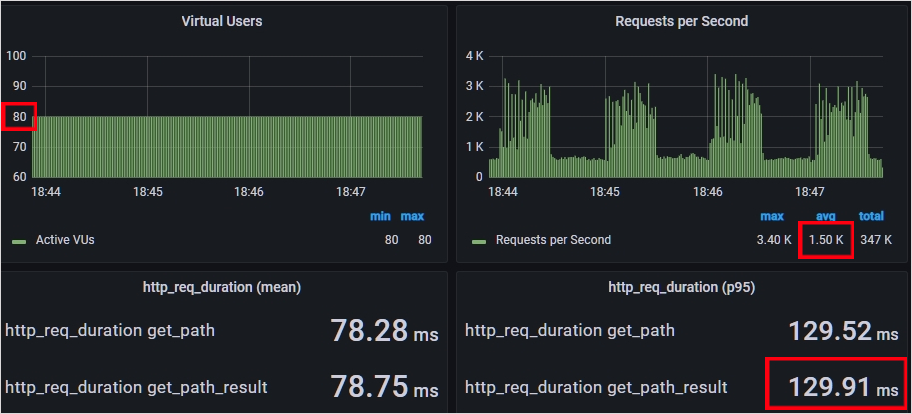
Vuser 80명에 RPS 1500인 상황까지 목표 응답 시간인 138ms 이하를 지켜주었습니다.
따라서 성능이 좀 더 나으면서 시스템 복잡도가 낮은 로컬 캐시를 선택하도록 하겠습니다.
캐시 삭제 정책 (Cache Eviction Policy) 결정
일반적으로는 캐시의 Key 갯수나 캐시의 크기를 기준으로 제한하여 너무 많은 메모리가 캐시에 의해 사용되는 것을 막습니다. 기준점에 닿았을 때 캐싱된 데이터 중 무엇을 삭제할지 결정하는 것이 캐시 삭제 정책인데요. 다음과 같은 방식들이 있습니다.
- LRU - 가장 오래 사용 안된 캐시 쫓아내기
- LFU - 가장 덜 사용된 캐시 쫓아내기
- FIFO - 가장 처음에 등록된 캐시 쫓아내기
- LIFO - 가장 마지막에 등록된 캐시 쫓아 내기
- Random - 아무거나 삭제하기
저 같은 경우는 모든 경우의 수에 대해서 캐싱을 진행하고 사이즈 제한을 두지 않았기 때문에 특별히 삭제 정책을 고려하지는 않았는데요. 만약 운영하게 되었을 때 사이즈를 더 작게 조절하는 것이 필요하다 판단되면, LFU 방식을 적용할 것 같습니다. 왜냐하면 지하철 노선도 서비스의 경우 패턴이 일정하기 때문에 많이 접근된 대상은 미래에도 많이 접근될 가능성이 높다고 생각하기 때문입니다. 하지만 이것은 추측이기 때문에 LFU 방식과 LRU 방식을 노드별로 다르게 적용한 후 캐시 히트율을 비교해서 더 높은 방식을 적용하면 좋을 것 같습니다.
분산 서버 환경에서 일관성에 대한 고민
로컬 캐시를 사용할 경우 앞서 말씀드렸듯이 캐싱하는 데이터의 일관성에 대한 문제가 있습니다. 캐시가 다른 서버에서 업데이트되었는데 여전히 다른 한 쪽 서버에서는 업데이트되지가 않는 문제입니다.
이 문제를 해결하기 위해서는 캐시가 저장된 후 일정 기간이 지나면 만료되는 TTL(Time To Live)값을 작게 설정하는 방법이 있습니다. 만약 1시간 정도로 설정하면 다른 서버에서 업데이트가 일어났을 때, 최대 1시간 동안은 일관되지 않은 값을 갖지만 1시간 후에는 캐시가 만료되어 업데이트된 값을 다시 DB로부터 불러오게 됩니다.
다른 방법으로는 서버끼리 메세지를 전달하는 방식입니다. 한 쪽 서버에서 캐시 업데이트가 일어날 경우 다른 서버들로 캐시 업데이트에 대한 메세지를 전달합니다. 메세지를 전달 받은 각 서버는 캐시를 업데이트하면 됩니다.
지하철 노선도 서비스의 경우 업데이트된 역에 대한 정보를 빠르게 보지 못한다는 것은 꽤 큰 문제라 생각됩니다. 그렇다고 TTL을 매우 짧게 잡는 것은 캐시 미스가 자주 일어나기 때문에 좋은 방식은 아니라 생각되구요.
따라서 저는 TTL은 12시간으로 길게 잡고 서버끼리 메세지를 전달하는 방식으로 캐시 일관성 문제를 해결하기로 하였습니다.
어떤 캐시 라이브러리를 사용할까?
- 로컬 캐시가 가능해야 한다.
- 무료여야 한다.
- Clustering - 캐시 업데이트시 캐시 만료 메세지를 각 서버에 보낼 수 있는 캐시 클러스터링 기능을 제공한다.
- Peer to Peer - 위 기능을 특별한 중앙 서버 없이 Peer to Peer 방식으로 제공해야 한다.
(애초에 로컬 캐시를 사용하는 주된 이유가 단순한 서버 구성을 원했기 때문) 성능- 눈치채셨는지 모르겠지만 앞서 성능테스트를 진행할 때 이미 목표 성능을 오버해서 달성했기 때문에 이 부분은 크게 고려하지 않았습니다.
Spring이 지원하는 캐시 라이브러리 중 위 기능을 제공하는 캐시 라이브러리를 찾아보았습니다. (각 라이브러리의 공식 다큐먼트에서 기능을 제공하는지 찾아보고 못 찾은 것들은 기능을 제공하지 않는다고 표시했습니다.)
- Hazelcast
- Infinispan
Geode: Clustering 기능을 제공하지만 Locator라는 중앙 서버 필요Redis: Client Caching이라는 이름으로 로컬 캐시를 제공하지만 중앙 서버 필요EhCache: Clusering 기능을 제공하지만 Terracotta라는 중앙 서버 필요Caffeine Cache: Clustering 기능을 제공하지 않음Couchbase: 로컬 캐시 기능을 제공하지 않음Cache2k: Clustering 기능을 제공하지 않음
Hazelcast와 Infinispan 2개가 남았는데요. Spring은 캐시 기능을 추상화하여 기존 코드의 변경 없이 캐시 저장소의 구현체를 쉽게 변경할 수 있습니다. 따라서 크게 고민하지 않고 관련 문서(구글 자료, Stackoverflow 자료 등)도 많고 더 널리 사용되는 Hazelcast를 선택하도록 하겠습니다.
Hazelcast로 캐싱 구현 후 테스트
그럼 Hazelcast로 캐시를 구현 후 성능 테스트를 진행해보겠습니다.
hazelcast.yaml - Hazelcast 캐시 설정
hazelcast: # hazelcast-full-example.yaml에서 모든 설정에 대한 설명 찾을 수 있음
cluster-name: path # 클러스터 이름
network:
port: 5701 # 클러스터 간 통신에 쓰이는 포트 번호 (Inbound)
auto-increment: true # port에 설정된 값부터 1씩 증가하며 가능한 포트 찾음
port-count: 100 # 총 100개까지 찾음 (5701~5801).
outbound-ports: # 클러스터 간 통신에 쓰이는 포트 번호 (Outbound)
- 0 # 0은 시스템이 제공하는 포트를 그대로 사용
join: # 동일한 클러스터에 있는 멤버를 찾는 방식에 대한 설정
multicast:
enabled: false
tcp-ip:
enabled: true
member-list:
# 클러스터 핵심 멤버 IP, 새로운 멤버는 멤버 중 최소 하나와 연결되면 된다.
- 192.78.0.50
cache:
path: # 캐시 이름
eviction: # 캐시 삭제 정책에 대한 설정
size: 500000
max-size-policy: ENTRY_COUNT # 캐시 갯수를 기준으로 삼음
eviction-policy: LFU
expiry-policy-factory: # 언제 캐시가 만료될 것인지
timed-expiry-policy-factory:
expiry-policy-type: CREATED # 캐시가 생성된 후
time-unit: HOURS
duration-amount: 12 # 12시간이 지나면 만료application-prod.yml
spring:
cache:
type: jcache
# jcache는 java가 제공하는 cache 추상화, hazelcast는 이 추상화의 구현체를 제공
jcache:
provider: com.hazelcast.cache.HazelcastMemberCachingProvider
# Cache를 관리하는 CacheManager를 관리하는 CachingProvider설정
# 로컬 캐시일 경우 - HazelcastMemberCachingProvider
# 리모트 캐시일 경우 - HazelcastClientCachingProvider
hazelcast:
config: "classpath:cacheconfig/hazelcast.yaml" # 설정 파일의 위치MapService.java - 경로 검색 결과 코드에 캐시 적용
// "path" 이름의 캐시 적용, 캐시를 찾을 때는 "source,target" 형태의 key로 찾는다.
@Cacheable(cacheNames = "path", key = "#source + ',' + #target")
public PathResponse findPath(Long source, Long target) {
List<Line> lines = lineService.findLines();
Station sourceStation = stationService.findById(source);
Station targetStation = stationService.findById(target);
SubwayPath subwayPath = pathService.findPath(lines, sourceStation, targetStation);
return PathResponseAssembler.assemble(subwayPath);
}스프링을 사용하면 이렇게 간단한 어노테이션만으로 캐싱 적용이 가능합니다. Spring 캐싱의 기본 전략은 캐싱이 설정된 메소드를 호출하기 전에 캐시저장소를 먼저 확인합니다. 그리고 캐싱된 것이 있다면 그 데이터를 사용합니다. 만약 이 메소드의 파라미터로 source = 1, target = 2가 왔다면 Map<String, Map<String, PathResponse>> 이런 형태의 자료구조에서 "path"를 key로 캐시(Map)를 찾고, 다시 "1,2"를 key로 캐싱 대상(PathResponse)을 찾습니다.
단일 요청에 대한 성능
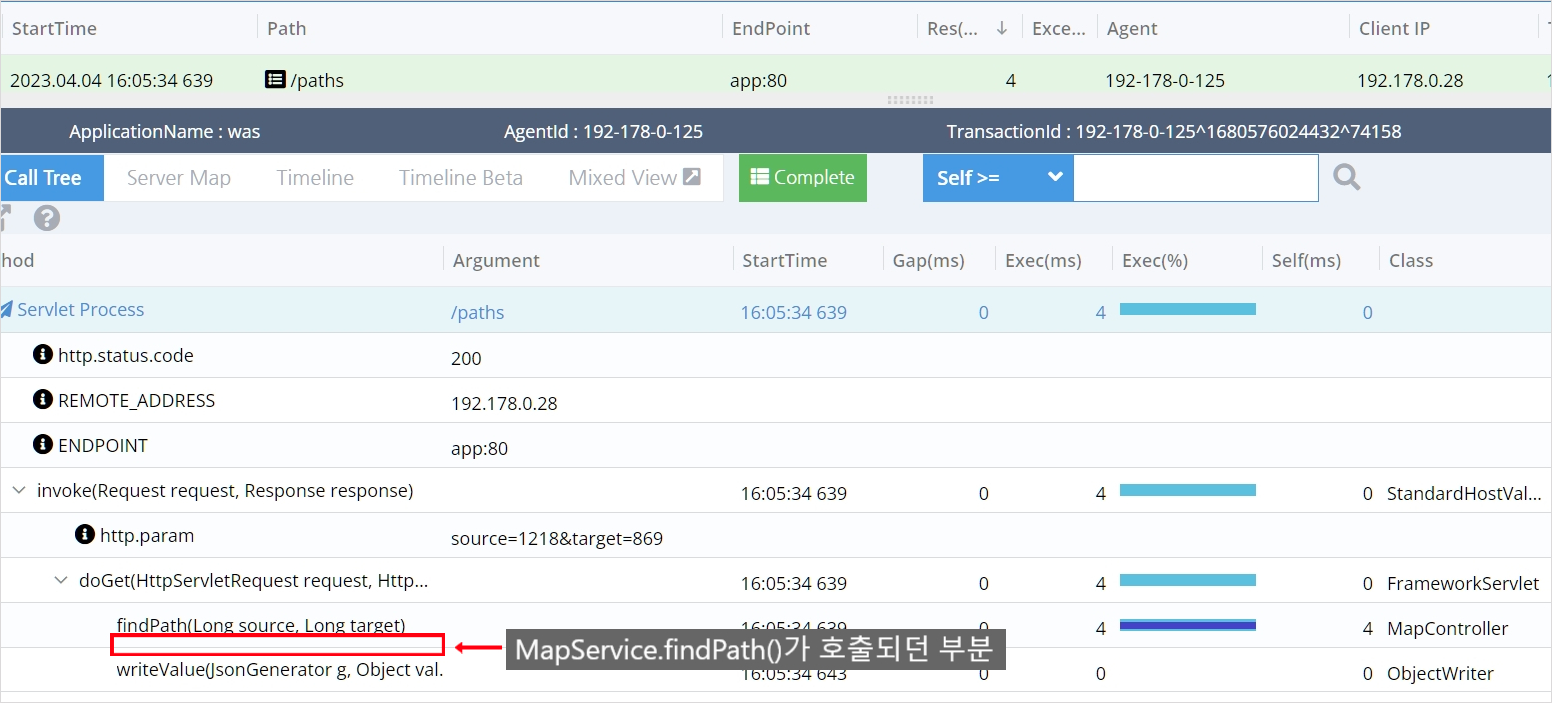
MapController의 findPath() 이 후 호출되던 MapService의 findPath 메소드가 캐시 히트로 인해 호출조차 안된 것을 보실 수 있습니다. 덕분에 단일 요청에 대한 성능이 50ms -> 4ms로 거의 10배가 빨라졌습니다.
요청 수가 많을 때 성능
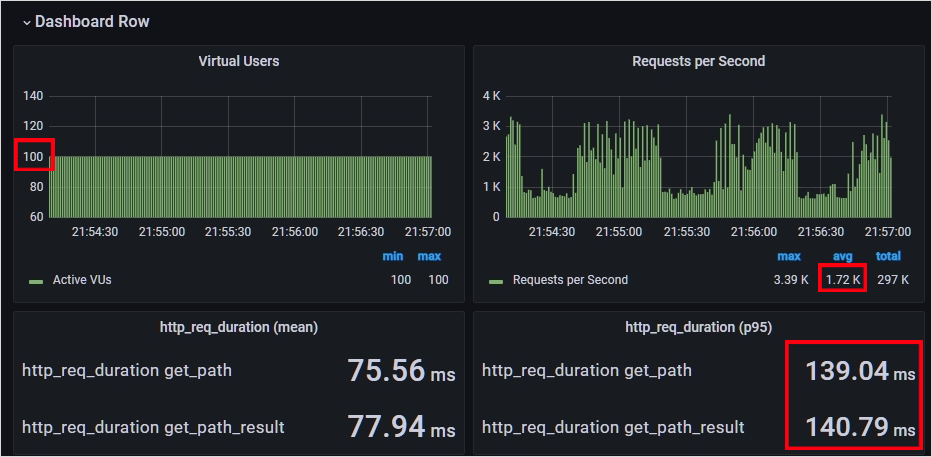
목표 성능인 '925RPS 상황에서 95% 요청에 대하여 138ms 이하의 응답 시간을 내는 것'을 한참 초과해버렸습니다 ! 1720RPS 상황에서 95% 요청에 대하여 140ms의 응답 시간을 보여주고 있네요.
마무리
시리즈 앞에서부터 열심히 빌드업한거 치고는 캐싱 하나로 생각보다 간단하게(?) 목표 성능을 달성하였습니다.
사실 이 글에 서버 스케일 아웃, DB Replication을 통한 읽기 부하 분산 등 성능 관련 많은 내용을 담고 싶었는데요. 캐싱 하나만으로도 분량이 꽤 나오기도 하고, 이미 목표 성능을 달성해버려서 이 부분에 대해서는 다음에 기회가 되면 더 알아보도록 하겠습니다.
지금까지 긴 시리즈 읽어주셔서 감사합니다~!
PS
시리즈를 처음부터 읽어오신 분이라면 2번째 문제였던 'Vuser 200명부터 경로 검색 페이지의 갑작스런 응답 시간 증가'는 왜 해결하지 않는지 궁금하신 분들도 있으실 것 같은데요. 이 문제는 스레드풀이 200개로 제한되어 있어서 발생한 문제였습니다. 글의 흐름상 넣을만한 부분이 딱히 없어서 다루지 않았습니다 ^^;
앞으로 시리즈 글을 작성할 때는 모두 쓴 다음에 한꺼번에 업로드 해야겠어요..
Reference
넥스트스텝 - 인프라공방
Software Architecture & Technology of Large-Scale Systems | Udemy
Hazelcast


많은 도움 되었습니다 . 감사합니다!