반 년 공백을 딛고 부활!
AI 코칭 스터디 들어갔으니 3주간 화이팅 🙌
2023-05-13
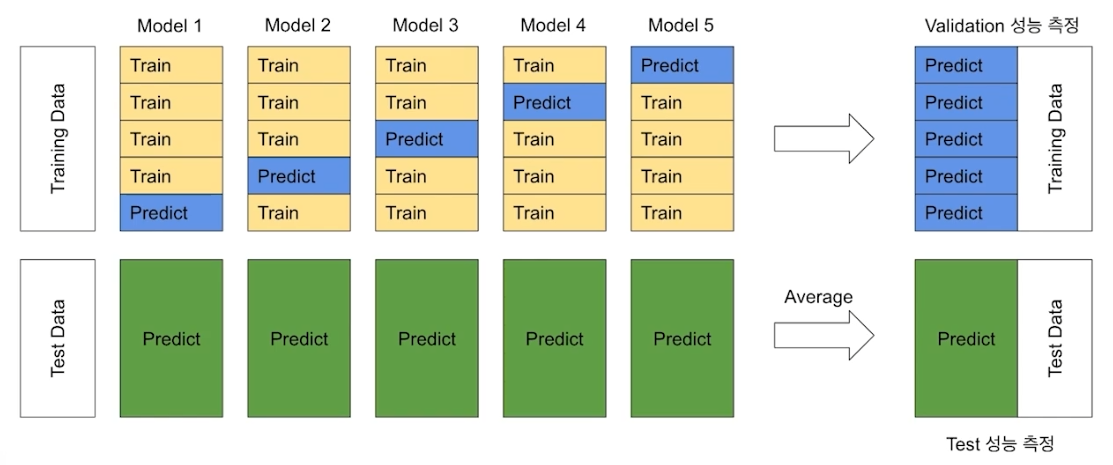
Cross Validation Out of Fold Prediction
-
Cross Validation
데이터를 여러 개의 fold로 나누어 validation 성능을 측정하는 방식. (이전에도 기록했으니까 자세한 설명은 패스) -
Out of Fold Prediction
fold마다 학습한 모델로 데이터를 예측하고 그 결과를 앙상블하여 최종 예측값으로 사용하는 방식. (대기과학에서 쓰는 방법이랑 비슷하다)
'''
코드 출처: BoostCourse
'''
# 테스트 데이터 예측값을 저장할 변수
test_preds = np.zeros(x_test.shape[0])
# Out Of Fold Validation 예측 데이터를 저장할 변수
y_oof = np.zeros(x_train.shape[0])
# 폴드별 평균 Validation 스코어를 저장할 변수
score = 0
# 피처 중요도를 저장할 데이터 프레임 선언
fi = pd.DataFrame()
fi['feature'] = features
# Stratified K Fold 선언
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=SEED)
for fold, (tr_idx, val_idx) in enumerate(skf.split(x_train, y)):
# train index, validation index로 train 데이터를 나눔
x_tr, x_val = x_train.loc[tr_idx, features], x_train.loc[val_idx, features]
y_tr, y_val = y[tr_idx], y[val_idx]
print(f'fold: {fold+1}, x_tr.shape: {x_tr.shape}, x_val.shape: {x_val.shape}')
# LightGBM 데이터셋 선언
dtrain = lgb.Dataset(x_tr, label=y_tr)
dvalid = lgb.Dataset(x_val, label=y_val)
# LightGBM 모델 훈련
clf = lgb.train(
model_params,
dtrain,
valid_sets=[dtrain, dvalid], # Validation 성능을 측정할 수 있도록 설정
categorical_feature=categorical_features,
verbose_eval=200
)
# Validation 데이터 예측
val_preds = clf.predict(x_val)
# Validation index에 예측값 저장
y_oof[val_idx] = val_preds # <-- 이번 fold로 학습한 모델에 validation data를 넣고 예측한 결과를 y_oof에 저장한다.
# 폴드별 Validation 스코어 측정
print(f"Fold {fold + 1} | AUC: {roc_auc_score(y_val, val_preds)}")
print('-'*80)
# score 변수에 폴드별 평균 Validation 스코어 저장
score += roc_auc_score(y_val, val_preds) / folds # <-- 이번 fold의 성적을 평균해서 저장한다.
# 테스트 데이터 예측하고 평균해서 저장
test_preds += clf.predict(x_test) / folds
# 폴드별 피처 중요도 저장
fi[f'fold_{fold+1}'] = clf.feature_importance()
del x_tr, x_val, y_tr, y_val
gc.collect()
print(f"\nMean AUC = {score}") # 폴드별 Validation 스코어 출력
print(f"OOF AUC = {roc_auc_score(y, y_oof)}") # Out Of Fold Validation 스코어 출력
# <-- **이 부분 이해가 잘 안가서 질문 남겨둔 상태** (y랑 y_oof랑 모양이 다른 것 같은데... y는 (n_samples), y_oof는 (n_samples, n_folds) 인 것 같은데 두 개 모양이 다른데 어떻게 이걸 할 수 있는건지??
# 폴드별 피처 중요도 평균값 계산해서 저장
fi_cols = [col for col in fi.columns if 'fold_' in col]
fi['importance'] = fi[fi_cols].mean(axis=1)Early Stopping
-
Early Stopping
과적합을 방지하기 위해 학습을 적합한 시점에서 종료하는 방법. 반복학습을 하는 머신러닝 모델에서 validation 성능이 가장 좋은 하이퍼파라미터가 나온 학습 단계에서 학습을 더 진행하지 않고 종료하는 방법이다. -
방법
LightGBM, XGBoost 등은early_stopping_rounds파라미터로 이 옵션을 제공한다. 부여한 횟수만큼 학습을 하고 그 횟수동안 성능이 개선이 되지 않으면 학습을 종료한다.
예를 들어n_estimators = 10000,early_stopping_rounds = 100으로 잡은 경우, 1~100회를 마친 성능이 0.8인데 101~200회 학습 중에서 성능이 0.8보다 높은 것이 하나도 없으면 학습을 종료한다.
2023-05-14
Feature Engineering
-
Feature Engineering?
원본 데이터로부터 문제 해결에 적합한 feature을 생성, 변환하고 머신러닝 모델에 적합한 형식으로 변환하는 작업을 말한다. 딥러닝은 모델이 데이터의 feature을 찾아낼 수 있지만 머신러닝은 사람이 feature를 찾아야 하기 때문에 feature engineering은 머신러닝 성능에 큰 영향을 준다. -
방법
특별히 새로운 방법이 있는 것은 아니다. sum, min, max, std, skew 등의 통계치를 이용해 새로운 feature을 만드는 것도 freature engineering의 일종이다. -
예시
nunique: 집계하는 condition에서 unique한 값이 몇 번 나왔는지 집계한다.
agg_func = ['mean','max','min','sum','count','std','skew', 'nunique']
test_agg = df.groupby(['customer_id']).agg(agg_func)Feature 중요도
-
feature 중요도?
타겟 변수를 예측하는 데 각 feature가 얼마나 중요한지 측정하는 방법. -
Model-specific vs. Model-agnostic
전자는 머신러닝 라이브러리에서 제공하는 feature 중요도를 사용하는 방법, 후자는 머신러닝 기능을 사용하지 않고 학습 이후에 계산하는 방법을 말한다. -
Permutation feature 중요도
Model-specific은 각 라이브러리에서 제공하는 기능을 사용하면 된다. 그렇다면 Model-agnostic은 어떻게 계산할까? 강의에서는 예시로 Permutation feature 중요도를 설명한다.
Permutation feature 중요도 방식은 feature의 값을 랜덤하게 섞은 뒤에 학습한 뒤 정상적인 학습 결과와 비교하는 방식이다. 중요한 feature라면 정상적인 학습 결과에 비해 에러가 커질 것이고, 그렇지 않다면 에러에 큰 차이가 나지 않을 것이다.
sklearn.inspection의permutation_importance매소드를 이용해서 수행할 수 있다.
Feature Selection
-
Feature Selection?
머신러닝 모델에서 사용할 feature을 선택하는 것을 말한다. 유용하지 않은 feature을 제거하여 과적합을 방지하고 모델 성능을 향상시킬 수 있다.
대표적으로 Filter Method, Wrapper Method, Embedded Method가 있다. -
Filter Method
feature의 통계 특성을 이용하는 방법이다. feature 간의 correlation을 구해 상관계수가 높은 feature을 제거하거나, 각 feature의 variance를 구해 분산이 낮은 feature을 제거하는 등의 방식이 있다. -
Wrapper Method
예측 모델에 여러 feature subset을 넣어가면서 실험하는 방식이다. (비용은 많이 들겠다) -
Embedded Method
Filter Method와 Wrapper Method를 합친 방식으로 학습 알고리즘 자체에서 feature selection을 수행하는 방식이다.
2023-05-15
Hyperparameter 튜닝
-
Hyperparameter vs. Parameter
Hyperparamter: 모델 학습 전 사람이 통제하는 값
Parameter: 모델이 학습하면서 스스로 설정하는 값 -
Hyperparameter 튜닝
모델에 적합한 하이퍼파라미터를 찾는 것을 하이퍼파라미터 튜닝이라고 한다. 아래 세 가지가 대표적인 방법이다.
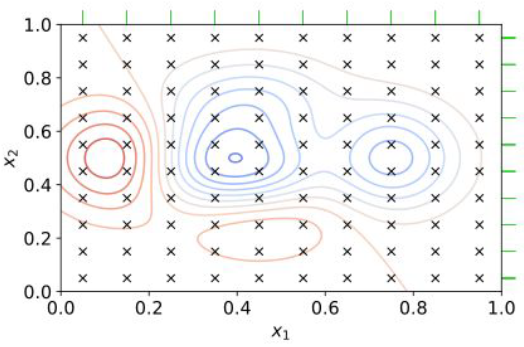
2.1 Grid Search
테스트 가능한 하이퍼파라미터를 모두 실험하는 방법. 하이퍼파라미터 개수가 늘어나면 그다지 효율적인 방법은 아니다. 아래 그림에서 균일한 grid로 초록색 격자마다 실험한 것이다.
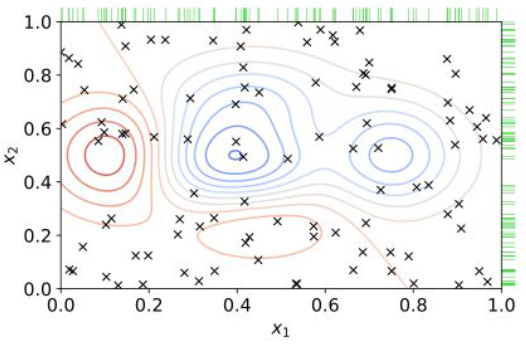
2.2 Random Search
테스트 가능한 하이퍼파라미터 범위에서 랜덤하게 실험하는 방법. Grid Search보다 효율이 좋다. 아래 그림에서 랜덤하게 실험한 것이다.
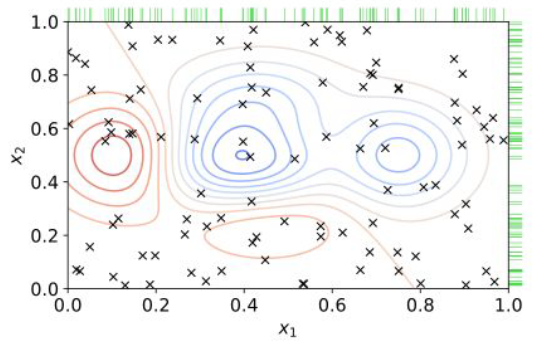
2.3 Bayesian Optimization
최초에는 랜덤한 하이퍼파라미터를 실험하고, 실험을 거듭할수록 성능이 잘 나오는 하이퍼파라미터를 집중적으로 실험한다. 아래 그림에서 성능이 높은 파란색 구간을 집중적으로 실험한 것이다.
- Optuna
하이퍼파라미터 튜닝을 지원하는 프레임워크.
아래는 목적함수 의 값을 최소로 하는 값을 -10~10의 탐색 범위에서 찾는 코드이다.
import optuna
def objective(trial):
x = trial.suggest_uniform('x', -10, 10) # <-- -10~10을 uniform하게 탐색
return (x-2)**2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
study.best_params
'''
출력 예시
'x' : 2.001285023
'''LightGBM에서 optuna로 하이퍼파라미터 튜닝을 하는 예시는 아래와 같다.
'''
고정된 parameter 주는 경우
model_params = {
'objective': 'binary', # 이진 분류
'boosting_type': 'gbdt',
'metric': 'auc', # 평가 지표 설정
'feature_fraction': 0.8, # 피처 샘플링 비율
'bagging_fraction': 0.8, # 데이터 샘플링 비율
'bagging_freq': 1,
'n_estimators': 10000, # 트리 개수
'early_stopping_rounds': 100,
'seed': SEED,
'verbose': -1,
'n_jobs': -1,
}
'''
def objective(trial, label=label_2011_11):
lgb_params = {
'objective': 'binary',
'boosting_type': 'gbdt',
'num_leaves': trial.suggest_int('num_leaves', 2, 256), # num_leaves 값을 2-256까지 정수값 중에 사용
'max_bin': trial.suggest_int('max_bin', 128, 256), # max_bin 값을 128-256까지 정수값 중에 사용
# min_data_in_leaf 값을 10-40까지 정수값 중에 사용
'min_data_in_leaf': trial.suggest_int('min_data_in_leaf', 10, 40),
# 피처 샘플링 비율을 0.4-1.0까지 중에 uniform 분포로 사용
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0),
# 데이터 샘플링 비율을 0.4-1.0까지 중에 uniform 분포로 사용
'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0),
# 데이터 샘플링 횟수를 1-7까지 정수값 중에 사용
'bagging_freq': trial.suggest_int('bagging_freq', 1, 7),
'n_estimators': 10000,
'early_stopping_rounds': 100,
# L1 값을 1e-8-10.0까지 로그 uniform 분포로 사용
'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0),
# L2 값을 1e-8-10.0까지 로그 uniform 분포로 사용
'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0),
'seed': SEED,
'verbose': -1,
'n_jobs': -1,
}
# oof prediction 함수 호출해서 out of fold validation 예측값을 얻어옴
y_oof, test_preds, fi = make_lgb_oof_prediction(train, y, test, features, model_params=lgb_params)
# Validation 스코어 계산
val_auc = roc_auc_score(label, y_oof)
return val_auc
study = optuna.create_study(direction='maximize') # val_auc가 가장 크게 나오도록(maximize) 하이퍼파라미터 탐색
study.optimize(objective, n_trials=10) # 10회 동안 하이퍼파라미터 탐색
# 하이퍼파라미터 탐색 결과 출력/plot
study.best_params # 최적의 하이퍼파라미터 출력
study.trials_dataframe() # 하이퍼파라미터 탐색 결과 출력
optuna.visualization.matplotlib.plot_param_importances(study) # 하이퍼파라미터 중요도 plot
optuna.visualization.matplotlib.plot_optimization_history(study) # 하이퍼파라미터 탐색 히스토리 plot
optuna.visualization.matplotlib.plot_slice(study) # 각 하이퍼파라미터와 val_auc와의 관계 plot
2023-05-16
Ensemble Learning
-
Ensemble Learning?
여러 개의 약한 성능의 모델을 결합하여 강한 성능의 모델을 만드는 기법. 과적합을 줄이고 성능을 개선하는 효과가 있다. -
Ensemble 기법
2.1 Bagging
Bootstrap Aggregation의 약자로, 각 모델이 데이터셋에서 중복을 허용하여 선별된 샘플 훈련 데이터를 이용해 학습하는 방식을 말한다. 대표적인 예시가 Random Forest.
2.2 Pasting
Bagging과 유사하나 중복을 허용하지 않고 샘플링 한다.
2.3 Voting
여러 알고리즘을 투표를 이용해 결정한다. Bagging은 동일한 알고리즘에 다른 학습셋을 이용한 결과를 조합하는 것이고, Voting은 다른 알고리즘에 동일한 학습셋을 이용한 결과를 조합하는 것이다. Hard Vote와 Soft Vote로 나뉜다.
2.3.1 Hard Voting
예측 결과 중 가장 많은 분류기가 예측한 결과를 최종 결과로 사용하는 방식. 소수의 예측 결과는 고려하지 않는다.
2.3.2 Soft Voting
모든 분류기의 예측 결과를 평균하는 방식. Soft Voting을 많이 사용한다.
2.4 Boosting
여러 개의 모델이 순차적으로 학습하는 방식. 이전 모델이 틀린 예측에 가중치를 부여해서 다음 모델이 학습한다. 성능이 뛰어나 Ensemble Learning에서 많이 사용한다. 대표적인 예시가 XGBoost, LightGBM, CatBoost. 단 Bagging보다 속도가 느리고 과적합이 발생할 수 있다.
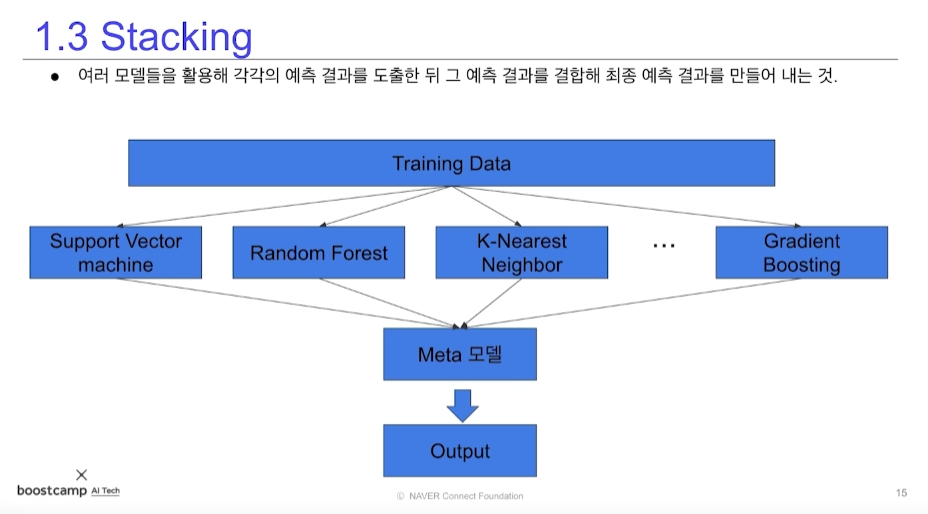
2.5 Stacking
여러 모델을 이용해서 예측한 뒤 그 예측 결과를 결합해 최종 예측을 만드는 방식. 첫 단계 모델을 베이스 모델이라고 하고, 그 모델의 예측값을 이용해 다시 학습하는 모델을 메타 모델이라고 한다. 성능이 뛰어나지만 과적합이 발생할 수 있고 비용이 과다하다.
2023-05-21
딥러닝 핵심 요소
- 데이터
모델이 배우는 데이터. 어떤 문제를 푸는지에 따라 타입이 달라진다. - 모델
데이터로부터 결과를 반환하는 도구. - Loss Function
데이터와 모델이 정해져 있을 때 모델의 성능을 측정하는 값. Regression Task에는 MSE, Classification Task에는 CE... 등이 대표적이다. - 알고리즘
Loss Function을 최소화하는 방식. 일반적으로 Loss Function의 1차 미분값을 사용한다. (아마 gradient 얘기인듯...?)
Neural Networks & Multi-Layer Perceptron
- Neural Networks
비선형적인 연산을 수행해서 목적으로 하는 함수에 근사시키는(function approximators) 도구. - Linear Neural Networks
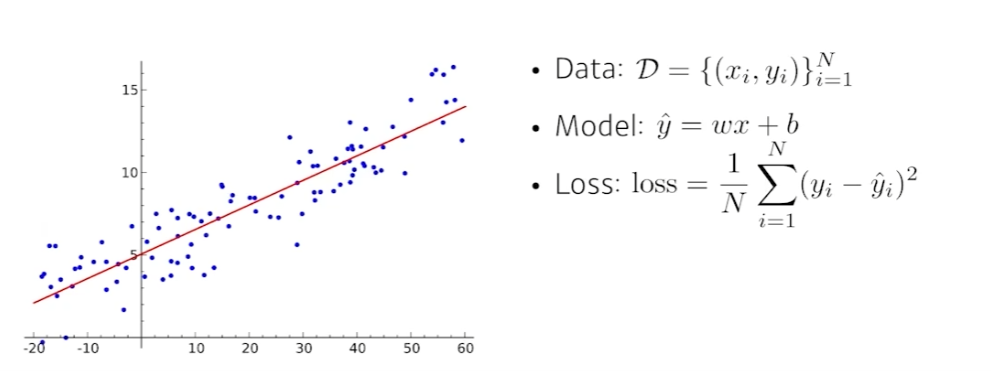
가장 간단한 선형회귀 모형을 생각하자. Loss Function은 MSE이고, 우리가 찾고 싶은 파라미터는 Loss Function을 최소화하는 와 이다.
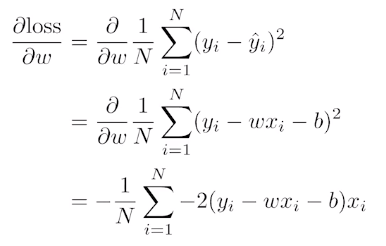
따라서 Loss Function을 최소화하기 위한 을 찾으려면 위와 같이 편미분하여 을 구하면 된다. 같은 방법으로 도 구할 수 있다.
이 방식을 gradient descent라고 부른다. - Multi-Layer Perceptron
Linear transform은 다음과 같이 행렬로 변환이 가능하다.만약 우리가 Linear transform을 여러 번 수행하면 로 표현이 될 것이다. 하지만 이것은 은 사실상 한 번의 Linear transform과 동일하다.
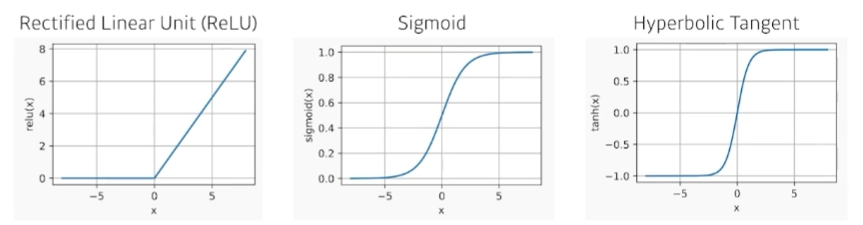
따라서 여러 단의 transform을 수행하려면 Nonlinear transform이 포함되어야 한다.여기에서 가 Nonlinear transform, Activation Function이다. 이 함수로 인해 모델이 출력할 수 있는 결과의 범위는 더 넓어진다. 이렇게 구성된 Network를 Multi-Layer Perceptron라고 부른다.
아래는 대표적인 Activation Function 의 예시이다.
2023-05-22
최적화 용어
- Generalization
학습을 반복할수록 학습셋 에러는 줄어들지만 테스트셋 에러는 어느 시점부터 증가할 수 있다. Generalization Gap은 이 둘 간의 차이를 의미한다. 테스트셋에서도 성능이 우수한 경우 Generalization Performance가 우수하다고 표현한다.
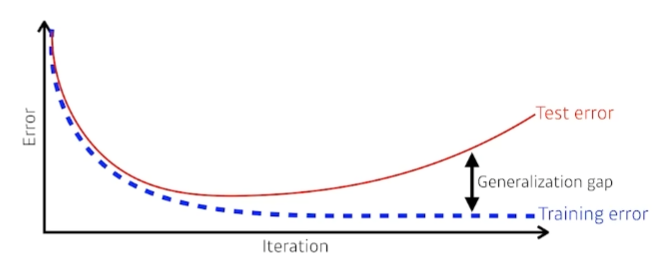
- Bias & Variance
- Variance: Input으로 인한 Output이 얼마나 분산이 되어있는지?
- Bias: 목적으로 하는 Output과 Input으로 인한 Output이 얼마나 차이가 나는지?
- Bootstrapping
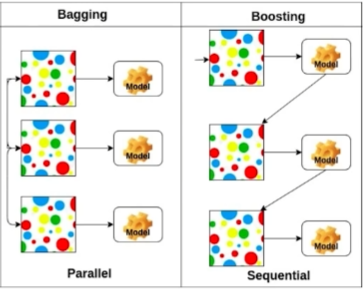
학습셋에서 여러 개의 subset을 만들고 여러 개의 모델을 만드는 기법. - Bagging vs. Boosting
- Bagging(Bootstrapping Aggregation): Bootstrapping을 통해 여러 모델을 학습하고, 여러 모델에서 나온 결과를 집계해서 최종 결과를 내는 방식. (앞에서는 Bagging vs. Voting을 했었는데 좀 헷갈리는구만...)
- Boosting: 여러 개의 모델(weak learner)이 순차적으로 학습하여 성능이 좋은 하나의 모델(strong learner)을 구현하는 방식. 자세한 설명은 앞에서 적었기 때문에 생략!
Gradient Descent
이전 Linear Regression 강의에서 본 것처럼 Loss Function을 최소화하는 파라미터를 편미분을 이용해 학습하는 방식. 아래 그림에서 Local Minimum을 만족하는 해 를 찾는다.
- Batch Gradient Descent
한 번에 모든 데이터를 사용해 gradient를 계산한다. - Stochastic Gradient Descent
데이터 중 하나의 subset만 이용해 gradient를 계산한다. (병렬 계산에서 주로 쓰인다.) - Mini-batch Gradient Descent
BGD와 SGD의 절충안으로 여러 subset을 이용해 gradient를 계산한다. - Gradient Descent Methods
4.1 Gradient Descent
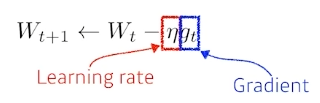
가 Neural Network의 weight(파라미터)라고 할 때, gradient descent는 gradient 를 learning rate 만큼 곱해서 빼주어 파라미터를 조정한다. 즉 Loss Function을 최소화하는 방향으로 파라미터를 이동시키는 것이다.
문제는 를 결정하는 것이 어렵다는 것이다. 너무 크면 최적값을 찾지 못할 수도 있고, 너무 작으면 수렴하지 않을 수 있다.
이러한 단점을 보완하기 위한 여러 가지 방법을 아래에서 다룬다.
4.2 Momentum
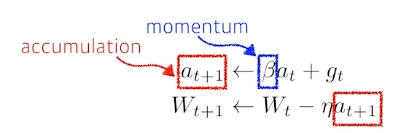
문자 그대로 '관성'을 이용한 방식. 이전 gradient 방향이 정해지면 다음 gradient 방향도 영향을 받는다.
gradient 만 이용하는 것이 아니라 이전 gradient 를 일부 가지고 있는 를 같이 이용해서 (accumulated) gradient descent한다.
gradient가 매 step마다 발산해도 어느 정도 방향성을 유지시켜준다는 장점이 있다.
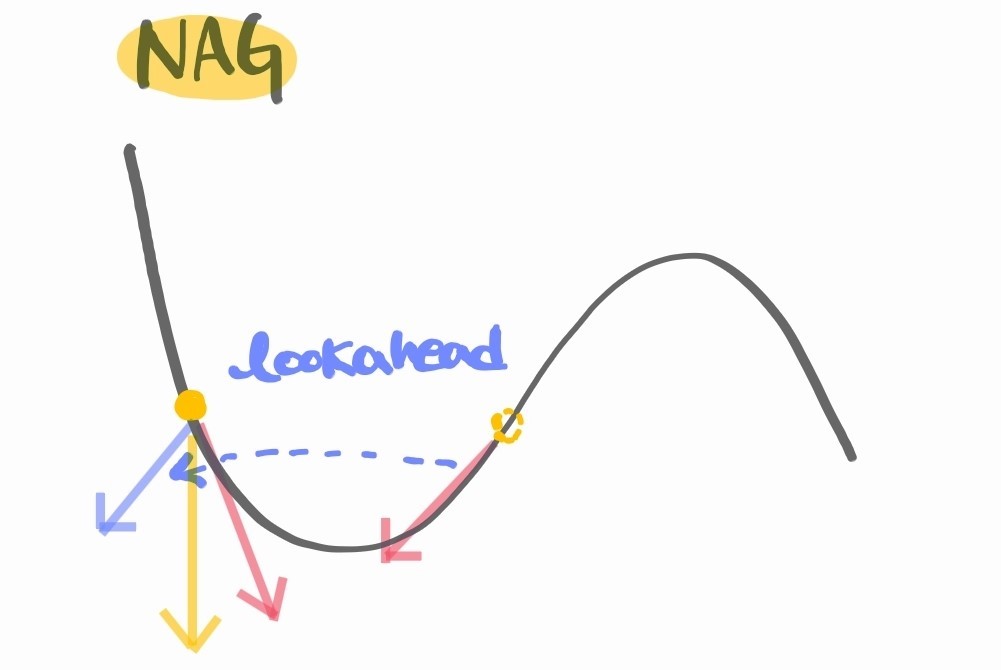
4.3 Nesterov Accelerated Gradient
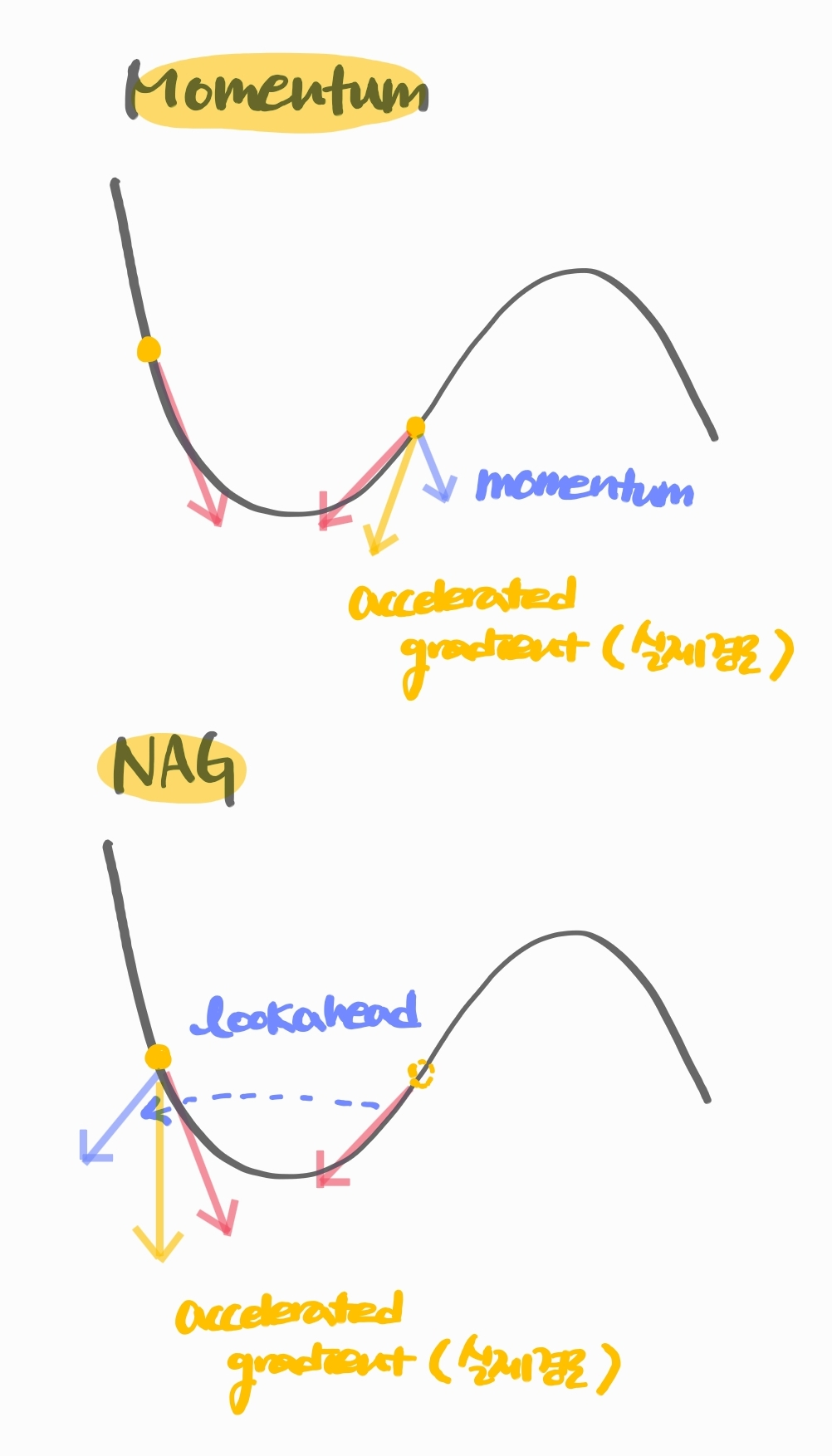
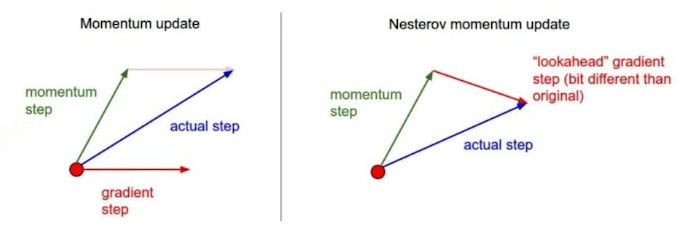
Momentum과 유사하게 accumulated gradient descent하는 방식이지만 lookahead gradient를 상용한다는 점이 다르다.
Momentum은 실제로 descent를 한 다음에 그 지점에서의 gradient를 계산하여 를 계산하지만, NAG는 실제로 이동하는 대신 그 예상 도착 지점의 gradient를 구해서 그것을 보정한만큼 를 계산한다.
Momeuntum보다 빠르게 수렴한다는 장점이 있다.
4.4 Adagrad
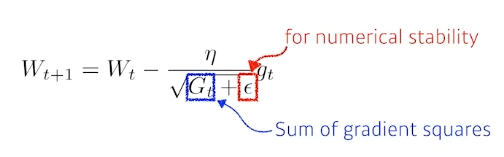
각 파라미터가 얼마나 변동했는지 저장한 다음, 지금까지 많이 변한 파라미터는 적게 변화시키고 적게 변한 파라미터는 많이 변화시키는 방법이다.
위 식에서 가 이전 gradient의 제곱 합이다. 즉 이전에 많이 변동했을수록 gradient descent가 줄어드는 방식이다.
결국 는 커질수밖에 없기 때문에, 시간이 지날수록 학습이 느려지는 단점을 가진다.
4.5 Adadelta

Adagrad의 가 무한히 커지는 것을 방지하는 방법이다. 과거의 gradient를 모두 합산하는 방법 대신 gradient 이동평균을 사용해 를 계산한다. 즉 최근의 gradient가 더 많이 반영되고, 오래된 gradient의 비중은 지수적으로 감소함으로써 Adagrad의 단점을 보완할 수 있다.
또다른 특징은 learning rate 가 없다는 점이다.
2.5 Adam

momentm과 이전 gradient의 제곱 합을 모두 혼합한 방법이다. 일반적으로 많이 사용하는 방식이다.
2023-05-23
Regularization
학습을 방해함으로써 과적합을 방지하는 기법.
- Early Stopping
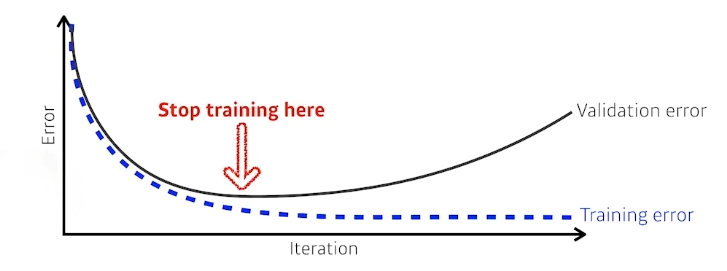
validation error가 커지는 시점에서 학습을 멈추는 방법. - Parameter Norm Penalty
파라미터가 너무 커지지 않게 조절하는 방법으로, 전체 파라미터의 제곱 합이 일정 크기를 넘지 않도록 한다. - Data Augmentation
(어라 네이버 강의인데) 데이터는 다다익선이기 때문에 데이터를 변형해서 학습셋으로 추가하는 방법. - Noise Robustness

학습셋에 노이즈를 추가하는 방법. Data Augmentation과 다른 점은 노이즈를 입력 데이터에만 넣는 것이 아니라 파라미터에 넣기도 한다. - Label Smoothing

학습데이터 두 개를 뽑아서 섞는 것. 분류 문제에서 많이 쓰이는 방법. - Dropout
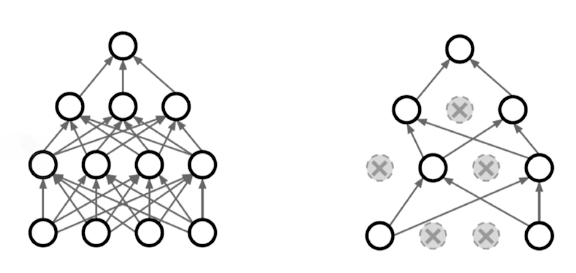
임의의 뉴런을 0으로 바꾸는 것. 각각의 뉴런의 robust feature을 얻을 수 있다. - Batch Normalization
특정 레이어의 파라미터의 통계치를 정규화하는 것. 예를 들어 한 레이어가 천 개의 파라미터를 가지는데, 이 파라미터를 정규화하는 것이다(평균 빼고 표준편차 나누고).
2023-05-25 (복습)
Non-linear Activation Function
- 선형 변환:
- affine 변환:
- Non-linear Activation Function:
→ Non-linear Activation Function이 딥러닝의 하나의 레이어가 된다.
레이어를 거치면 Non-linear term을 거치면서 X 공간이 찌그러진다. 공간을 적절히 찌그러트려서 (classification의 경우) 선형 함수로도 X를 분류할 수 있도록 만드는 것이 딥러닝이다.
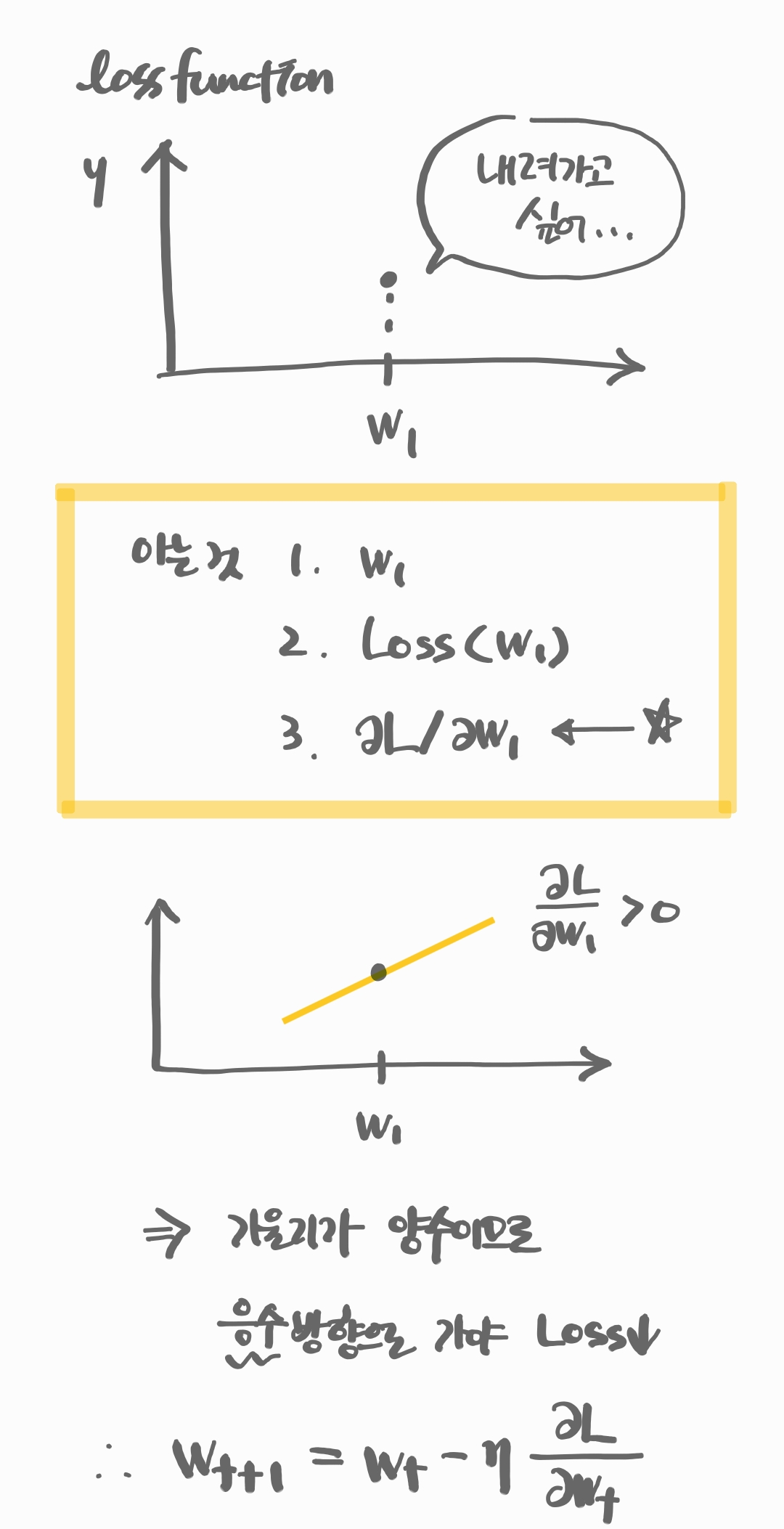
Gradient Descent
loss function을 줄이기 위한 를 찾는 Gradient Descent는 아래 그림으로 설명할 수 있다.
2023-05-27
Convolution
CNN의 Convolution은 signal processing에서 사용하는 도구를 말한다. 두 가지 신호의 시간 지연된 합을 구하는 것을 의미하고, 노이즈 제거나 주파수 변환하는 등의 작업에 사용한다.
이미지에서의 Convolution은 입력 이미지를 '필터'에 곱하는 것을 말한다.
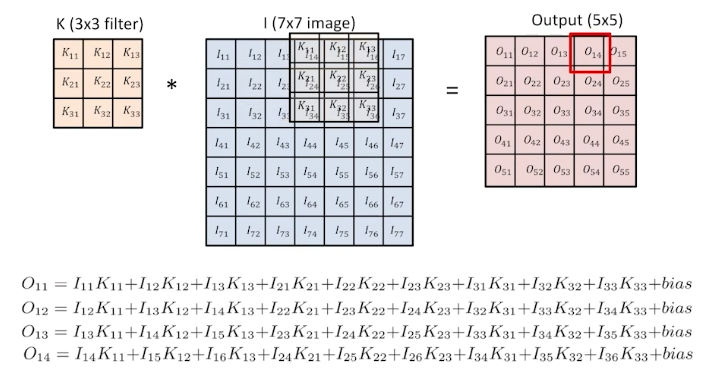
그림에서 3x3 필터를 7x7 이미지에 곱함으로써 5x5의 convolution된 이미지를 얻을 수 있다.
필터의 모양에 따라서 output은 달라질 수 있다. 예를 들어 3x3 필터 내 값이 모두 1/9이라고 생각해보자. 그러면 하나의 output 셀은 아홉 개의 칸의 평균값이 들어가 있다. 이 필터를 사용하면 이미지는 blur 처리가 되어 나올 것이다.
이런 식으로 필터를 조정하면서 이미지를 흐리게 하거나, 외곽선을 강조하는 등의 output을 얻을 수 있다.
RGB Image Convolution
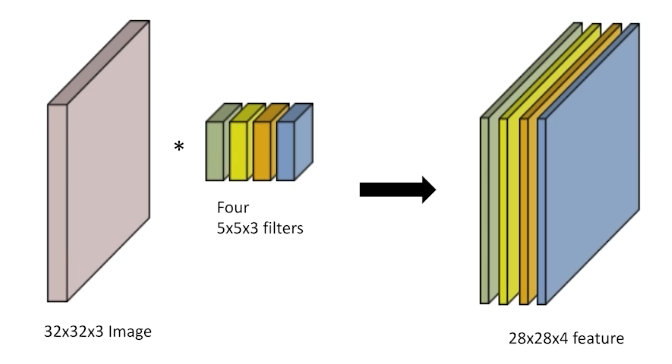
RGB는 R/G/B 3가지 채널을 가진다. 이 경우 필터도 3가지 채널을 가지게 하면 하나의 채널 output을 얻을 수 있다.
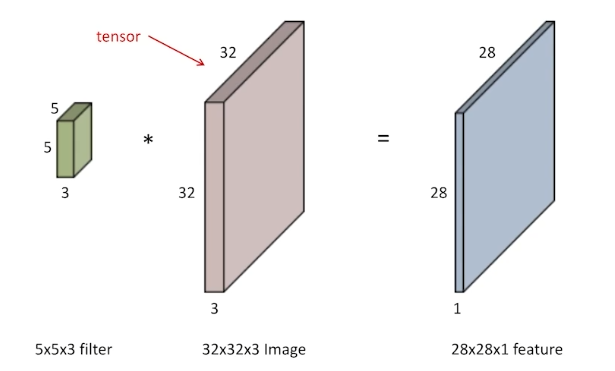
여러 개의 채널을 가지는 output(feature map)은 어떻게 얻을 수 있을까? 필터를 여러 번 적용하면 된다. 필터의 채널 수는 input과 동일하고, 그 필터를 몇 개를 사용하느냐에 따라 output의 채널 수가 결정된다.
아래의 경우 convolution에 필요한 parameter 개수는 5x5x3x4개이다.
non-linear activation을 적용하는 경우도 있다.
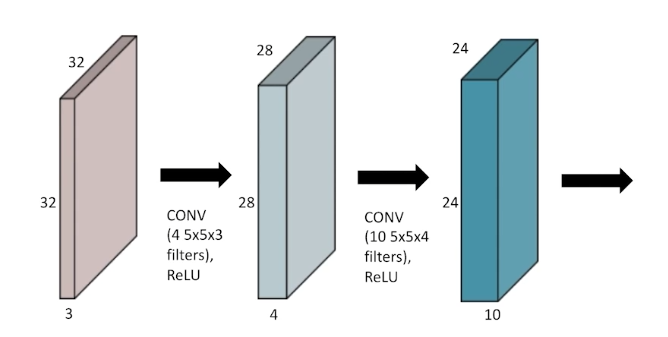
CNN
CNN은 이미지의 특징을 추출한 convolution layer, 이미지의 사이즈와 특징을 축소하는 pooling layer, 이미지 분류에 최종적으로 사용하는 fully connected layer로 구성되어 있다.
이 때 fully connected layer의 채널이 굉장히 크기 때문에 이 과정에서 parameter 개수가 엄청나게 늘어난다. 그래서 최근에는 fully connected layer의 크기를 줄이려는 노력을 하고 있다.
그럼 convolution layer에서 분류하면 안돼?
convolution layer 대신 fully connected layer을 사용하는 이유는 과적합을 방지할 수 있기 때문이다. convolution은 특징만을 강조하기 때문에 이 layer을 사용해서 분류를 하면 노이즈에 취약해진다. fully connected layer을 사용하면 이미지의 특징과 이미지의 전체적인 구조를 고려할 수 있어 과적합을 방지할 수 있다.
stride
stride는 필터가 이미지 상에서 한 번 이동할 때 얼마나 이동하는지를 의미한다. moving average의 window를 생각하면 된다.
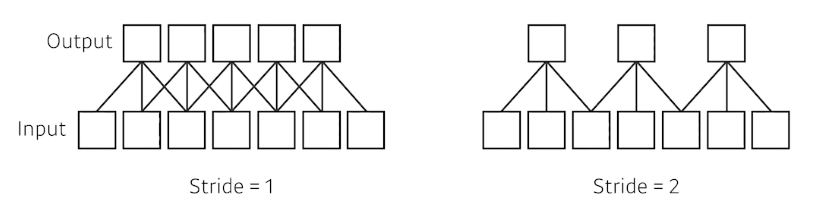
input이 7이고, 필터가 3이라고 가정하자. stride=1일 때에는 한 칸씩 움직이기 때문에 output이 5가 나온다. 반면 2일 때에는 두 칸을 이동해서 output이 3이 된다.
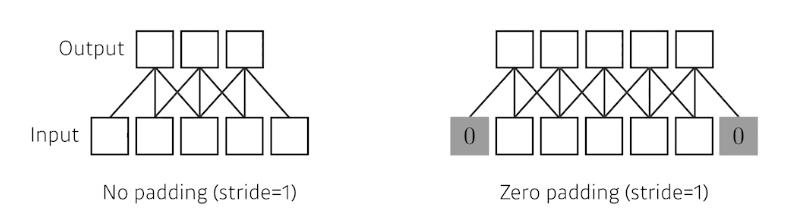
padding
필터를 적용하면 불가피하게 이미지의 가장자리 정보를 잃게 된다. 이 때 정보 손실을 막기 위해 맨 끝에 가상의 정보를 추가하는 것을 padding이라고 한다. 이렇게 하면 output의 dimension이 input과 동일하게 유지된다.
2023-05-28
Modern CNN
CNN 발전단계에서 얻은 교훈들(갈수록 layer의 개수는 많아지고 parameter 개수는 줄어듬)
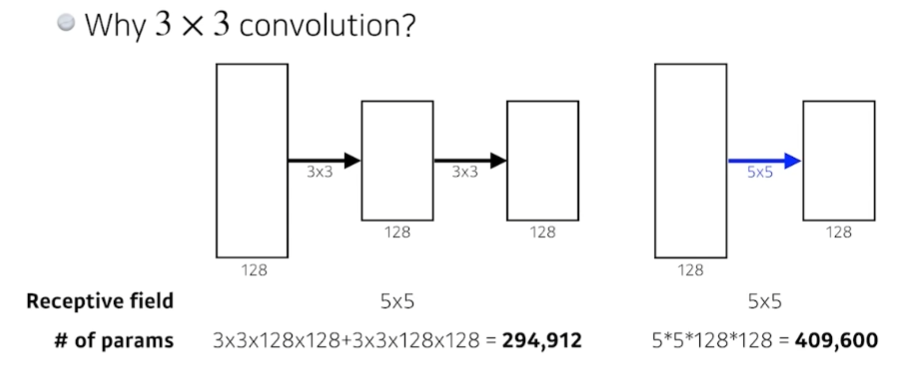
- 동일한 size의 output을 얻을 때, parameter 개수 관점에서 5x5 필터를 한 번 사용하는 것보다 3x3 필터를 두 번 사용하는 것이 이득이다(5x5>3x3x2).
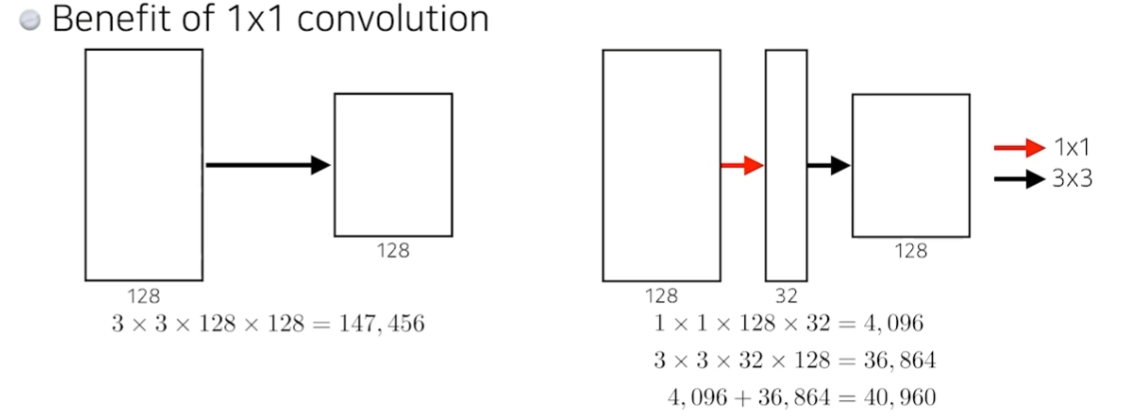
- 동일한 size의 output을 얻을 때, 1x1 convolution을 이용해 채널 개수를 줄이면 parameter 개수를 줄이는 데 유리하다(3x3x128x128>1x1x128x32+3x3x32x128).
Semantic Segmentation
- semantic segmentation란?
이미지를 통째로 강아지/고양이로 분류하는 것이 아니라, 이미지 중에서 특정 부분이 강아지이고/특정 부분이 사람이고...를 분류하는 문제. 자율주행 등에서 많이 사용한다. - Fully Convolutional Network
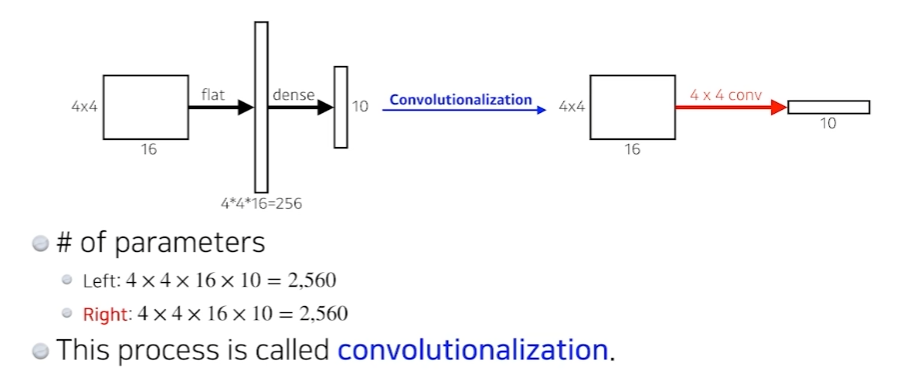
기존 CNN에서 fully connected layer을 제거하는 것. 좌측은 입력 이미지의 특징을 1차원 배열로 변환해서(flat) fully connected layer(dense)를 만든다. 우측은 1차원으로 변환하지 않고 convolution을 이용해서 만든다. 사실상 parameter의 개수는 차이가 없다.
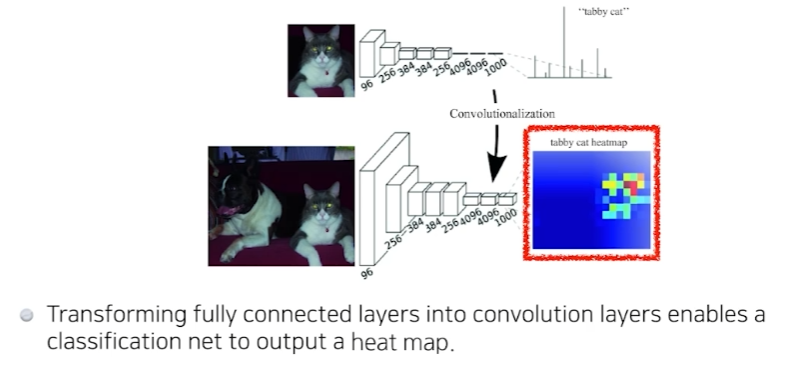
왜 굳이 fully convolution layer을 만드는걸까? convolution layer는 입력 이미지와 동일한 크기의 feature map이다. 이렇게 하면 heatmap처럼 입력 이미지에서 어느 픽셀에 분류 대상이 있는지 강조가 된다.
2023-05-29
Sequential Model
sequential data는 대화, 동작 등 연속된 데이터를 말한다. 데이터의 길이가 정해지지 않았기 때문에 CNN과 같은 방법을 사용할 수 없다.
- Autoregressive model
다음에 오는 데이터를 예측한다고 하면 가장 대표적인 방법이 Autoregressive model이다. 이전의 n개 step 데이터를 고려하는 방법이다. n=1로 두는 것을 Markov model이라고 한다. - Latent autoregressive model
과거의 정보를 요약한 hidden state를 두고 여기에만 의존하여 다음 step을 예측하는 모델이다.
Recurrent Neural Network
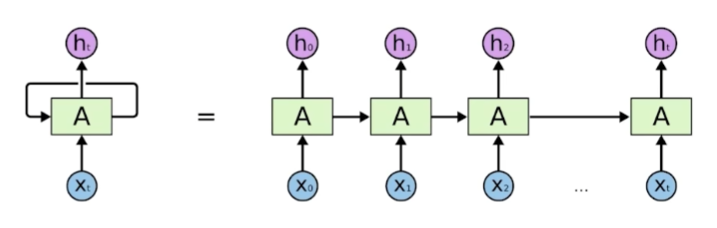
이전 step의 정보를 이어받아서 학습하는 구조이다. RNN의 가장 큰 단점은 short-term dependencies를 가진다는 점이다. step을 반복할수록 먼 과거의 정보는 희석된다. 즉 장기기억이 어렵다.
Long Short Term Memory
기존 RNN의 short-term dependency 문제를 해결하기 위해 나온 모델. 기존 모델은 이전 step의 hidden state()이 다음 step 계산에 쓰이지만, 이 모델에서는 와 함께 모델 output으로 출력되지 않는 'cell state'를 함께 사용한다. 'cell state'는 이전 time step의 내용을 요약한 정보이다.
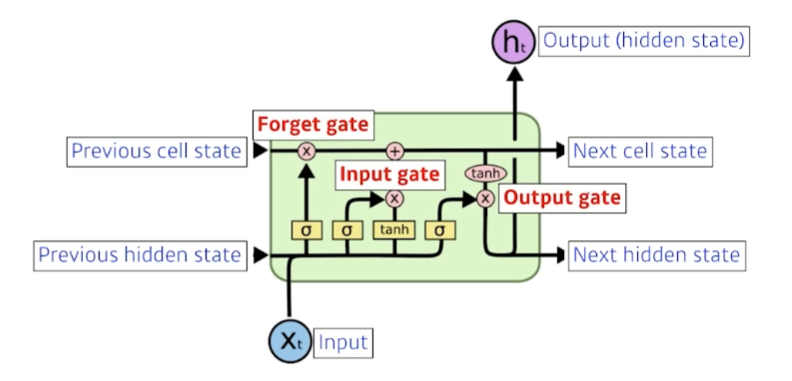
LSTM에는 gate라는 개념이 있는데, 각각에 대해서 알아보자.
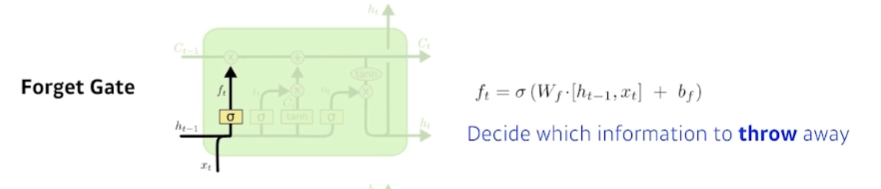
- Forget gate
어느 정보를 버릴지 결정한다. 이 gate에 들어가는 것은 현재 step의 input 와 이전 step의 output 이다. activation function을 통해 둘을 조합하여 이전 step 정보 중 어떤 것을 버릴지 결정한다.
- Input gate
어느 정보를 cell state로 저장할지 결정한다. 마찬가지로 현재 step의 input 와 이전 step의 output 이 gate에 들어간다.

- Output gate
input gate를 통과한 정보를 이용해 cell state를 업데이트한다. 그리고 업데이트된 cell state에서 어떤 것을 출력할지 output gate에서 결정한다.
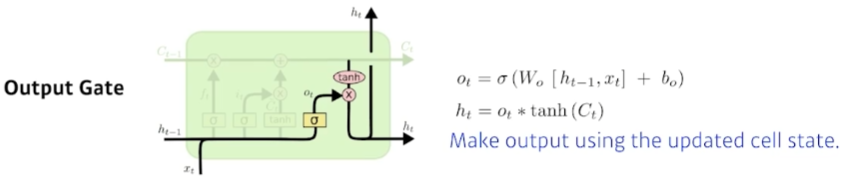
Gated Recurrent Unit
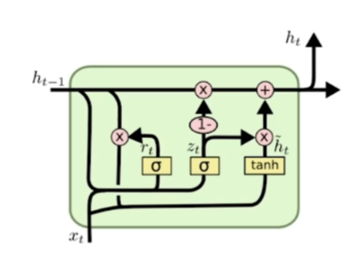
LSTM과 달리 gate가 2개 이고, cell state를 별도로 생성하지 않고 hidden state를 곧바로 다음 cell에서 사용한다. LSTM보다 적은 parameter을 사용한다.
2023-05-30
Transformer
'attention'이라는 개념을 사용하는 모델. sequnetial data 뿐 아니라 이미지 분류 등 광범위하게 쓰인다.
RNN과 다르게 이전 step을 정보를 받아 다음 step을 계산하는 방식이 아니다. 그래서 'I am a student'라는 입력을 받으면 RNN은 'I', 'am', 'a', 'student'를 하나씩 step으로 처리하지만 Transformer는 'I am a student'를 통째로 처리한다.
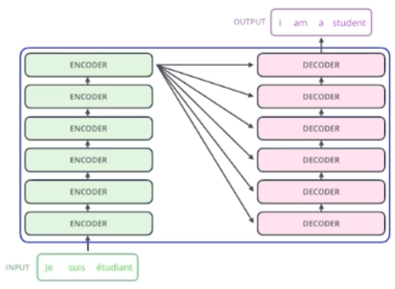
번역하는 문제를 생각하면 input을 다른 언어의 output으로 만드는 모델이 필요하다.
input을 처리하는 encoder와 output을 연산하는 decoder가 서로 parameter는 공유하지 않고 각각 stack 되어있는 구조로 되어있다.
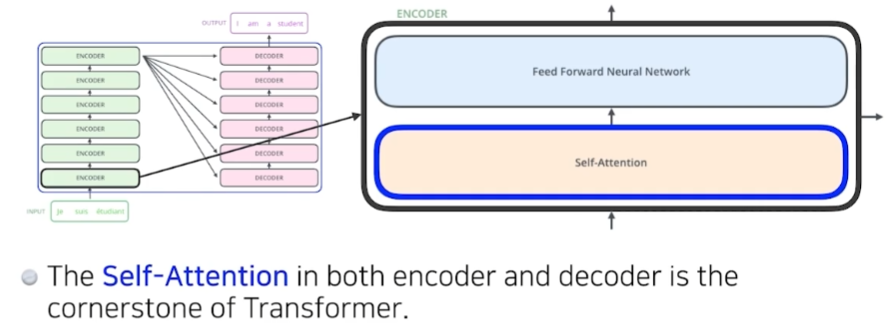
이 때 encoder 내부에는 self-attention이 있다. self-attention은 연속된 데이터 각각을 vector로 변환하는데, 이 때 데이터 하나만 사용하는 것이 아니라 뒤에 나오는 데이터를 함께 사용한다. 즉 'I'를 벡터로 변환할 때 'am', 'a', 'student'도 고려한다는 것이다.
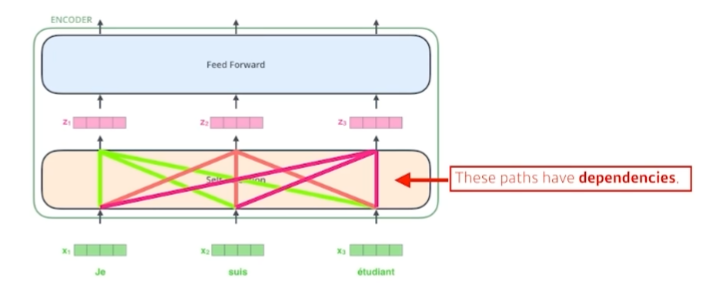
이것이 중요한 이유는 'Soo is tired because she slept late last night.'이라는 문장이 올 때 'she'가 앞의 문장 중 어떤 단어와 연관이 깊은지 self-attention을 통해 학습하기 때문이다.
(여기부터는 진짜 무슨 소리인가 싶은...)
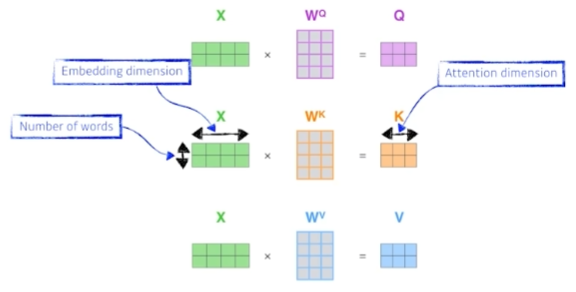
단어를 벡터로 변환한 것을 라고 하면 self-attention 내부에서 각각 적절한 행렬을 곱해 queries , keys , values 라는 벡터를 만든다. 그리고 이 벡터 간의 연산을 이용해 각 단어(벡터)가 서로 어느 정도의 중요도를 가지는지 점수 를 연산한다.
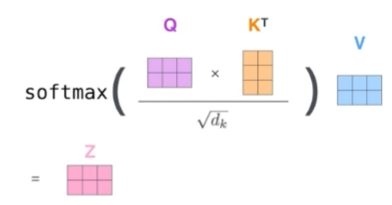
이러한 특성 때문에 input이 정해지면 output도 고정되어 있는 CNN 등과 다르게 Transformer는 input 옆에 어떤 input이 함께 들어오느냐에 따라 output이 달라질 수 있다.
이렇게 데이터 간의 상관성을 연산하는 방식 때문에 n개의 단어가 들어왔을 때 RNN은 연산을 n번 하면 되지만, Transformer는 n의 제곱 번을 연산해야 한다.
Transformer는 처음에 자연어 번역에 주로 쓰였지만 요즘은 이미지 처리 등에도 사용하고 있다.
2023-06-01(복습)
- CNN
- Convolution: 필터를 sliding window로 이동하면서 이미지의 특징을 추출한다.
- Pooling: AVG Pooling, MAX Pooling 등을 이용해서 정보 손실을 최소화하면서 이미지의 사이즈를 줄인다.
-> 듣다보니 Convolution이랑 Pooling이 약간 헷갈리는데(둘 다 사각형으로 필터거는 것처럼 보여서), 이 블로그를 보고 좀 더 내 방식대로 정리를 하면
- Convolution: '합성곱'이라는 말 그대로 이미지를 특정 행렬과 곱하는 것. 그리고 sliding window로 stride마다 움직여가면서 곱한다.
- Pooling: 사이즈를 줄이기 위해 이미지의 구간을 적당히 나눈 다음 그 구간마다 최대값/평균값/최소값 등 하나의 값만 꺼내서 그 이미지 구간을 대표하게 만드는 것. Convolution처럼 곱하거나, sliding window로 이동하는 것이 아니다.
- RNN
- 이전 학습에서 연산한 hidden 값을 다음 step의 input으로 넣는 방식
- LSTM
- RNN의 hidden에 장기기억을 추가하는 개념(RNN의 hidden은 시간이 지날수록 back prop으로 초기 기억이 급격히 사라짐)
- 모든 기억을 장기 저장할 수 없기 때문에 적절히 삭제/추가해서 장기기억을 선별한다.
- 그 장기기억을 hidden에 고려해서 다음 step에 사용한다.
- Attention
...이번에도 이해를 못했다... 토요일에 다시 들어보자 😇
2023-06-20
양자컴퓨팅
모두의연구소 오픈 강연을 듣고 왔다! 시작 5분만에 이해가 안 되었지만 ^.^ ... 챗지피티와 함께 정리~
- 양자컴퓨터
양자역학 기반의 알고리즘을 가지는 컴퓨팅을 말한다. 전자기학 기반의 Bit와 다르게 Qubit을 기본 단위로 가진다. Qubit은 0, 1 대신 '중첩'된 값을 가질 수 있다. 양자역학과 마찬가지로 측정을 하는 순간 Qubit의 값은 하나로 결정이 된다.
'중첩'된 값이 정확히 뭐야? 여러 개의 값을 하나의 메모리에 넣는다는 거야?
여기서 '중첩'은 고전적인 의미에서 여러 개의 값을 저장한다는 의미가 아니다. 파동함수를 이용해 Qubit의 state에 확률 진폭 함수를 할당한다. 그리고 측정을 하는 순간 확률 진폭에 의해 확률이 결정되어 하나의 possible state로 '붕괴collapse'되고 Qubit는 고전적인 의미의 Bit 값을 가지게 된다.
(여기서 더 파고들어도 이해는 안 되니 이 선에서 정리하자)
만약 이미지 분류 문제를 양자컴퓨터로 푼다면?
1. Qubit 수 결정: 이미지의 각 픽셀의 값(0~255)을 Qubit state에 매핑해야 한다. 필요한 Qubit의 수는 픽셀 값의 범위보다 크거나 같은 2의 거듭제곱값을 통해 결정한다. 이 경우 2^8=256이므로 8개의 Qubit가 필요하다.
2. Qubit 초기화: 상태 |0⟩로 초기화된 8개 Qubit 세트가 있다.
3. Quantum Encoding: 0~255 사이의 픽셀 값을 Qubit의 quantum state에 매핑한다. 예를 들어 픽셀 값 128을 이진 표현 |10000000⟩로 인코딩한다.
4. Quantum Processing: 이미지가 Qubit로 인코딩 된 후 quantum 알고리즘과 quantum gates를 이용하여 quantum state를 계산할 수 있다(하나하나가 인코딩된 게 어떻게 중첩이 된다는건지 왜 빠르다는건지 알아보려고 했으나 모르겠다... 감이 안온다...).
5. 문제 풀이: Quantum Processing이 완료되면 Qubit로부터 classical information(아마도 Bit)을 얻기 위해 측정measurement을 수행한다. 측정한 결과를 이용해 분류 문제를 푼다.
-
왜 빠를까?
고전컴퓨터에서는 Bit로 기본 논리 게이트를 처리하면서 알고리즘을 구현한다. (똑바로 이해한 게 맞나) 문제가 복잡해지면 알고리즘의 복잡도가 올라가고 연산 시간이 오래 걸린다.
양자컴퓨터는 Qubit을 사용해서 고전컴퓨터의 논리 게이트를 더 단순하게 표현할 수 있기 때문에 연산 시간이 더 적게 걸린다.
고전컴퓨터보다 시간복잡도 면에서 성능이 좋다고 알려진 알고리즘은 (1) 소인수 분해, (2) 검색, (3) 선형연산()이다. -
정말 빠를까?
'양자컴퓨터를 사용하면 고전컴퓨터가 xxx년 걸리는 문제를 xx초만에!'라는 문구로 유명하지만 실제 상황과는 약간의 괴리가 있다고 한다. 일부 알고리즘에서 성능이 좋다고 수학적으로 증명이 되었지만 exponential한 수준이 아니라 polynomial한 수준이라고 알려져 있고, 고전컴퓨터에서도 어느 정도 따라잡을 수 있어 둘 간의 격차가 매우 크다고 보기는 어렵다.
그래서 최근에는 이론적인 복잡도 연구보다도 실증적인 문제(예: 실제로 실험을 해야만 하는 sampling 같은)에 집중하는 추세라고 한다.
