
" 결과 ⊂ 사건 ⊂ 표본공간 "
결과(Outcome, 결과값)
- 한 번의 시행에서 실제로 관측되는 값
- ex) 주사위를 던져서 3이 나온 것
사건 (Event)
- 결과들의 집합
- 사건은 결과 여러 개를 묶어서 정의할 수 있고, 우리가 확률을 구하고 싶은 대상
- ex) 주사위를 던져서 홀수가 나오는 사건 = {1,3,5}
표본공간 (Sample Space, Ω)
- 가능한 모든 결과들의 집합
- 사건은 항상 표본공간의 부분집합
- 주사위 던지기 → Ω = {1,2,3,4,5,6}
- 표본공간을 잘못 설정하면 결과가 왜곡됨
- 조건부확률, 독립성, 추론 등 전부 틀어짐
- ex) 구매고객만 포함하면 미구매 고객은 무시됨
관계 정리
- 결과 ⊂ 사건 ⊂ 표본공간
- 결과 : 표본공간 속의 하나의 원소
- 사건 : 표본공간의 부분집합
- 표본공간 : 가능한 모든 결과들의 전체 집합
" 확률 "
확률
- 어떤 사건이 일어날 가능성을 수치로 나타낸 것
- 미래의 불확실성을 수치로 표현한 것
- 값의 범위 : 0 ~ 1
- 확률 0 : 가능성 없음이 아니라, 일어날 가능성이 매우 희박한 것
- 확률 0 : 너무 희박해서 특정 값 하나로 잡히지 않음
- 데이터 분석가에겐 전략 제안을 위한 근거로서 필요
계산
- 확률은 원하는 사건의 경우의 수 ÷ 전체 경우의 수로 계산할 수 있음
특징
- 항상 0 ≤ P ≤ 1
- 전체 사건의 합은 1
- 확률이 클수록 그 사건이 일어날 가능성이 높음
확률변수
- 사건을 숫자로 표현한 변수
- 수학적으로 다루기 편리
- 실현값(Realization)
- 확률변수의 실제 관측된 값
- ex) X = { 빨강, 흰색 }
- 확률변수 X를 “빨강=1, 흰색=0”으로 정의
- P(X=1) = 0.8, P(X=0) = 0.2
- 확률변수 X = 1,0 (구슬의 색을 숫자로 정의한 것)
- 실현값 = 실제로 뽑힌 색 (빨강, 흰색)
- 확률 값 = 사건이 일어날 가능성을 나타내는 수치 (0.8, 0.2)
유형
- 이산형 확률변수(Discrete)
- 값이 뚝뚝 끊겨 있음, 세어지는 값
- ex) 주사위 눈 (1~6), 동전 (앞=1, 뒤=0), 하루 방문자 수 등
- 값이 뚝뚝 끊겨 있음, 세어지는 값
- 연속형 확률변수(Discrete)
- 값이 무한히 이어짐, 줄자로 재는 값
- ex) 키(161.1cm), 몸무게 (48.5kg) 등
- 값이 무한히 이어짐, 줄자로 재는 값
확률분포
- 확률변수가 어떤 값을 얼마나 자주 가지는지
- 확률변수가 어떻게 퍼져 있는지
- 확률변수 X와 확률 P(X)의 매칭
- 이산형 확률분포
- 값이 뚝뚝 끊겨 있음, 막대 그래프
- 연속형 확률분포
- 값이 무한히 이어짐, 곡선(PDF, 확률밀도함수)+면적(곡선 아래 면적 = 확률)
- 분포를 통해 데이터의 특징, 안정성, 이상치 판단 가능
실무 사례
- 품질 관리 : 부품 길이 평균 10cm, 분산이 작음 → 공정 안정
- 서비스 운영 : 고객 체류시간 평균 5분, 꼬리가 길음 → 일부는 오래 머무름
" 기댓값 "
기댓값
- 확률분포에 따라 장기적으로 기대되는 평균값
- 확률변수의 평균적인 값
- 오랫동안 반복했을 때 수렴하는 값
- 단기 불확실성은 따로 고려 필요 : 분산, 표준편차로 보완
- 계산방법 : 확률변수가 가질 수 있는 값에 확률을 곱함
- 이산형 확률변수의 기댓값
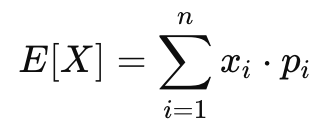
- 연속형 확률변수의 기댓값
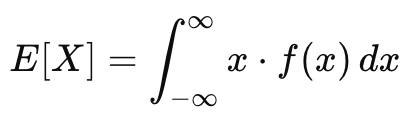
- 이산형 확률변수의 기댓값
- 기댓값 ≠ 실제로 항상 나오는 값
- 기댓값 ≠ 미래를 정확히 예언
- 기댓값 = 많은 시도(큰 수의 법칙)의 평균
" 조건부 확률 "
조건부 확률
- P(A|B) = 어떤 사건 B가 일어났다는 조건 하에서 사건 A가 일어날 확률
ex) 비가 올 때, 우산을 쓸 확률 등 - 계산식
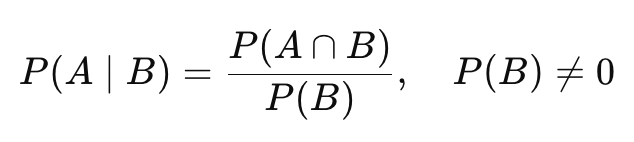
- 조건 하나로 확률이 달라짐
- 조건 없음 → 우산을 쓸 확률 = 30%
- 조건 : 비 오는 날 → 우산을 쓸 확률 = 90%
독립
- 독립 사건은 조건이 있어도 확률이 변하지 않음
- 독립 = 한 사건이 일어난 것이 다른 사건에 영향을 주지 않는 것
- 계산식
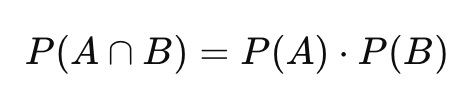

실무 사례
- 조건부 확률 : 30대 여성 고객이 쿠폰을 클릭할 확률 등
- 독립 : 이번주 로또 당첨 확률은 지난주 결과와 무관
"정말 독립인가?"
- 데이터 분석가는 "정말 독립인가?"를 항상 확인해야 함
- 독립 여부에 따라 분석/검정 방법이 달라짐
- 독립이 기본 전제이지만, 환경이 바뀌면 쉽게 깨질 수 있음
- 독립이라는 가정 하에 분석했으나 독립이 아니라면? 결과가 왜곡되기 때문
사례
- 가위바위보 : 완전 무작위라면, 내가 뭘 내든 무관하게 상대가 뭘 낼 확률은 1/3 → 독립
- 만약 항상 첫 판은 가위를 내는 습관이 있다면? 조건 생성, 독립 깨짐
- 현실 데이터는 대부분 독립이 아님
" 이론적 확률분포 "
이론적 확률분포
- 실험이나 관찰을 기반으로 하지 않고, 수학적 모델이나 규칙을 이용해 정의된 확률분포
- 즉, “이런 확률이 나올 것이다”라는 수학적 가정을 기반으로 만든 분포
종류
- 데이터 성격에 따라 분포 달라짐
- 이산형 분포
- 베르누이 분포: 성공/실패(0/1) 확률
- 이항분포: 여러 번의 베르누이 시행에서 성공 횟수
- 포아송 분포: 단위 시간/공간 내 사건 발생 횟수
- 연속형 분포
- 정규분포: 평균 근처에 값이 몰림, 종 모양
- 균등분포: 모든 값이 균등하게 나올 확률
- 지수분포: 사건 간 간격 모델링
특징
- 모양을 결정하는 숫자(파라미터, parameter) 존재
- 정규분포 → 평균 μ, 표준편차 σ
- 수학적으로 정의되어 있음 → 공식으로 확률 계산 가능
- 데이터 분석·통계 검정·시뮬레이션에서 활용
" 정규분포 "
정규분포
- 통계에서 가장 중요한 분포
- 세상의 많은 데이터가 정규분포로 근사 가능하기 때문
- 평균과 표준편차로 모양이 정해짐
- 평균 : μ → 종 모양의 가운데 위치
- 표준편차 : δ → 종 모양의 너비(흩어짐)
역할
- 실제 데이터를 표현하는 데 쓰임
- 데이터가 어떻게 퍼져 있는지(흩어짐, 중심 위치)를 직관적으로 이해 가능
서로 다른 스케일의 데이터를 정규분포에서 비교 시
- ex) 남녀 키 분포에서 각 키를 비교
- x축이 실제 키 cm
- 장점
- 실제 값이 분포에서 어디에 위치하는지 직관적으로 확인 가능
- ex) 180cm 남성은 평균보다 약간 큰 키라는 걸 바로 알 수 있음
- 단점
- 남성과 여성의 평균, 표준편차가 달라서 “어느 쪽이 더 극단적인 값인지” 비교가 직관적이지 않음
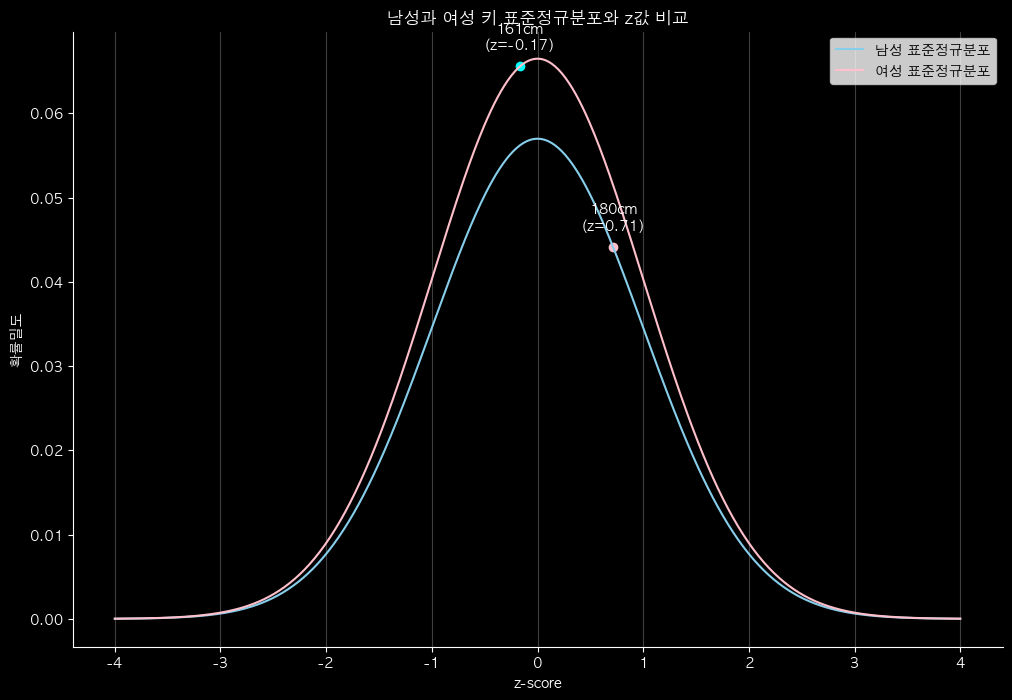
표준정규분포
- 평균이 0, 표준편차가 1인 정규분포
- 단위가 사라짐 → 상대적 위치만 남음
- 단위가 달라도, 분포가 달라도 비교 가능
역할
- 서로 다른 정규분포 간 비교 가능
- ex) 수학 점수와 국어 점수 비교
- 확률 계산이 쉬워짐
서로 다른 스케일의 데이터를 표준정규분포에서 비교 시
- ex) 남녀 키 분포에서 각 키를 비교
- x축이 z = (x - 평균) / 표준편차
- 평균이 0, 표준편차가 1로 표준화됨
- 각 값이 평균으로부터 몇 표준편차 떨어져 있는지 확인 가능
- 장점
- 서로 다른 분포를 비교할 수 있음
- ex) 남자 180cm → z ≈ (180-175)/7 ≈ 0.71, 여자 161cm → z ≈ (161-162)/6 ≈ -0.17
- 남성 180cm는 남성 평균보다 약간 높고, 여성 161cm는 여성 평균보다 거의 평균 수준임
- 극단값 판정, 백분위 비교, 확률 계산 등에 바로 활용 가능
- 서로 다른 분포를 비교할 수 있음
- 단점
- 실제 단위(cm) 정보가 사라져 직관성이 떨어질 수 있음
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 모집단 평균과 표준편차 가정 (예시)
mean_m, std_m = 175, 7 # 남성 평균, 표준편차
mean_f, std_f = 162, 6 # 여성 평균, 표준편차
# 키값 예시
heights_m = [180]
heights_f = [161]
# x축 범위
x_m = np.linspace(mean_m - 4*std_m, mean_m + 4*std_m, 500)
x_f = np.linspace(mean_f - 4*std_f, mean_f + 4*std_f, 500)
# 정규분포 확률밀도
pdf_m = norm.pdf(x_m, mean_m, std_m)
pdf_f = norm.pdf(x_f, mean_f, std_f)
# 시각화
fig=plt.figure(figsize=(12,8), facecolor='k')
ax= fig.add_subplot()
ax.patch.set_facecolor('k')
plt.plot(x_m, pdf_m, label="남성 분포", color='skyblue')
plt.plot(x_f, pdf_f, label="여성 분포", color='pink')
# z-score 계산 및 표시
for h in heights_m:
z = (h - mean_m) / std_m
plt.scatter(h, norm.pdf(h, mean_m, std_m), color='purple')
plt.text(h, norm.pdf(h, mean_m, std_m)+0.002, f'{h}cm\n(z={z:.2f})', ha='center', color='w')
for h in heights_f:
z = (h - mean_f) / std_f
plt.scatter(h, norm.pdf(h, mean_f, std_f), color='cyan')
plt.text(h, norm.pdf(h, mean_f, std_f)+0.002, f'{h}cm\n(z={z:.2f})', ha='center', color='w')
ax.set_title('남성과 여성 키 분포와 z값 비교', color='w')
ax.set_xlabel('키 (cm)', color='w')
ax.set_ylabel('확률밀도', color='w')
plt.legend()
ax.tick_params(colors='w')
ax.spines['bottom'].set_color('w')
ax.spines['left'].set_color('w')
plt.gca().set_axisbelow(True)
plt.grid(axis='x', alpha=0.3, color='lightgray')
plt.show()
# --- 표준정규분포 ---
# z = (x - mean) / std
z_m = (x_m - mean_m) / std_m
z_f = (x_f - mean_f) / std_f
fig=plt.figure(figsize=(12,8), facecolor='k')
ax= fig.add_subplot()
ax.patch.set_facecolor('k')
plt.plot(z_m, pdf_m, label="남성 표준정규분포", color='skyblue')
plt.plot(z_f, pdf_f, label="여성 표준정규분포", color='pink')
# z-score 표시
for h in heights_m:
z = (h - mean_m) / std_m
plt.scatter(z, norm.pdf(h, mean_m, std_m), color='pink')
plt.text(z, norm.pdf(h, mean_m, std_m)+0.002, f'{h}cm\n(z={z:.2f})', ha='center', color='w')
for h in heights_f:
z = (h - mean_f) / std_f
plt.scatter(z, norm.pdf(h, mean_f, std_f), color='cyan')
plt.text(z, norm.pdf(h, mean_f, std_f)+0.002, f'{h}cm\n(z={z:.2f})', ha='center', color='w')
ax.set_title('남성과 여성 키 표준정규분포와 z값 비교', color='w')
ax.set_xlabel('z-score', color='w')
ax.set_ylabel('확률밀도', color='w')
plt.legend()
ax.tick_params(colors='w')
ax.spines['bottom'].set_color('w')
ax.spines['left'].set_color('w')
plt.gca().set_axisbelow(True)
plt.grid(axis='x', alpha=0.3, color='lightgray')
plt.show()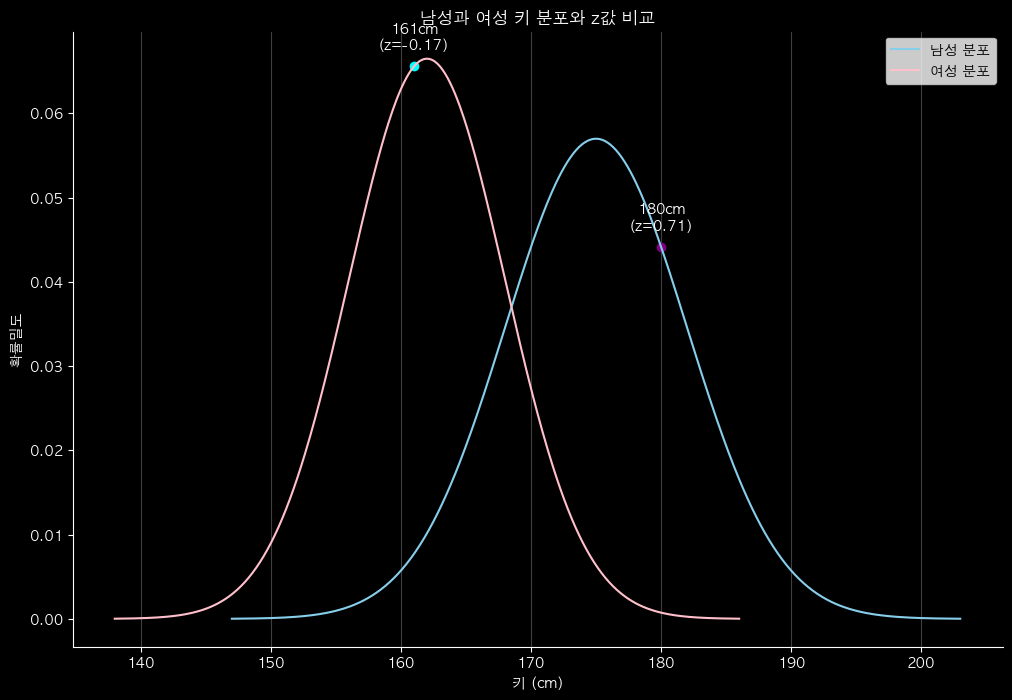 |
 |
정규화 (Normalization)
- 데이터의 최솟값과 최댓값을 이용해 0~1 범위로 스케일 조정
- 핵심 : "범위를 맞춘다"
- 목적 : 단위가 다른 데이터를 같은 스케일에서 비교하기 위함
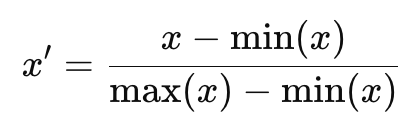
특징
- 변환 후 값의 범위 : 0 ~ 1
- 데이터의 분포 모양은 변하지 않음
- 이상치에 민감 → 한 개의 극단값 때문에 전체 스케일이 왜곡될 수 있음
- 단위가 달라도 비교 가능 (cm vs 원 vs km)
표준화 (Standardization)
- 데이터의 평균을 0, 표준편차를 1로 변환
- 핵심 : "분포를 바꾼다"
- 목적: 단위 차이를 없애고, 상대적 위치(몇 σ만큼 떨어져 있는지)를 해석하기 위함
- Z-점수(Z-score)
- 분포를 표준정규분포로 환산할 수 있음
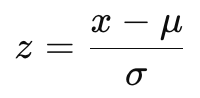
- 분포를 표준정규분포로 환산할 수 있음
- ex) 시험 점수가 90점일 때, 평균 70점, 표준편차 10점이면
- z = (90 - 70) / 10 = 2
- “평균보다 2표준편차 높은 점수”라는 의미
- 상대적 지표, 절대적 우열은 아님
특징
- 변환 후 데이터의 평균 = 0, 표준편차 = 1
- 데이터의 단위를 없애고, 상대적 위치를 표현
- 이상치에 덜 민감
- 표준정규분포 기반 해석(68-95-99.7 법칙 적용 가능)
" 68-95-99.7 법칙 "
68-95-99.7 법칙
- 정규분포에서 평균(μ)과 표준편차(σ)를 기준으로, 데이터가 평균을 기준으로 얼마나 퍼져 있는지를 나타내는 경험적 규칙
- 특정 값이 흔한지 드문지 빠르게 판단하는 기준
- 정규분포 : x'의 절대값이 클수록 더 드문 값
- 평균 ± 1σ ≈ 68%
: 68%의 데이터가 평균 ± 1σ 범위에 존재 - 평균 ± 2σ ≈ 95%
- 평균 ± 3σ ≈ 99.7%
- ex) 평균=100, 표준편차=15인 정규분포에서 70~130점의 비율은?
- 70=100-2x15, 130=100+2x15 → 약 95%(±2σ)
- 평균 ± 1σ ≈ 68%
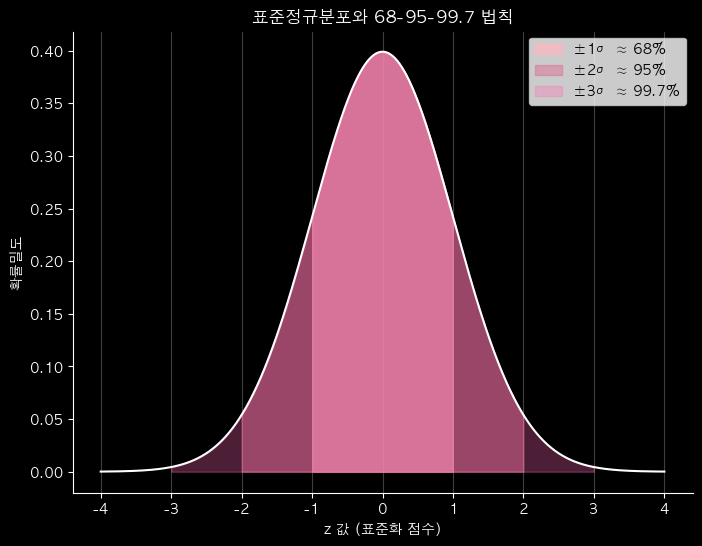
- 표준정규분포 : z의 절대값이 클수록 더 드문 값
- ± 1 ≈ 68%
: 68%의 데이터가 ± 1 범위에 존재 - ± 2 ≈ 95%
- ± 3 ≈ 99.7%
- ± 1 ≈ 68%
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 일반 정규분포 평균과 표준편차
mu, sigma = 175, 7
# x 범위
x = np.linspace(mu - 4*sigma, mu + 4*sigma, 1000)
# 정규분포 pdf
pdf = norm.pdf(x, mu, sigma)
fig=plt.figure(figsize=(8,6), facecolor='k')
ax= fig.add_subplot()
ax.patch.set_facecolor('k')
plt.plot(x, pdf, color='w', label='남성 키 분포')
# 영역 색칠: ±1σ, ±2σ, ±3σ
colors = ['#7FFFD4', '#87CEFA', '#00BFFF']
# 68-95-99.7 범위 색칠
plt.fill_between(x, pdf, 0, where=(x > mu - sigma) & (x < mu + sigma), color=colors[0], alpha=0.7, label='68% 영역')
plt.fill_between(x, pdf, 0, where=(x > mu - 2*sigma) & (x < mu + 2*sigma), color=colors[1], alpha=0.5, label='95% 영역')
plt.fill_between(x, pdf, 0, where=(x > mu - 3*sigma) & (x < mu + 3*sigma), color=colors[2], alpha=0.3, label='99.7% 영역')
ax.set_title('남성 키 분포와 68-95-99.7 법칙', color='w')
ax.set_xlabel('키 (cm)', color='w')
ax.set_ylabel('확률밀도', color='w')
plt.legend()
ax.tick_params(colors='w')
ax.spines['bottom'].set_color('w')
ax.spines['left'].set_color('w')
plt.gca().set_axisbelow(True)
plt.grid(axis='x', alpha=0.3, color='lightgray')
plt.show()
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import scipy.stats as stats
# 한글 폰트 설정 (Mac용)
plt.rcParams['font.family'] = 'AppleGothic'
# 마이너스 기호 깨짐 방지
mpl.rcParams['axes.unicode_minus'] = False
# 표준정규분포 정의 (평균=0, 표준편차=1)
x = np.linspace(-4, 4, 1000)
y = stats.norm.pdf(x, 0, 1)
# 그래프 그리기
fig=plt.figure(figsize=(8,6), facecolor='k')
ax= fig.add_subplot()
ax.patch.set_facecolor('k')
plt.plot(x, y, color='w')
# 영역 색칠: ±1σ, ±2σ, ±3σ
colors = ['#7FFFD4', '#87CEFA', '#00BFFF']
# ±1σ 영역
plt.fill_between(x, y, where=(x >= -1) & (x <= 1),
color=colors[0], alpha=0.7, label='±1σ ≈ 68%')
# ±2σ 영역
plt.fill_between(x, y, where=(x >= -2) & (x <= 2),
color=colors[1], alpha=0.5, label='±2σ ≈ 95%')
# ±3σ 영역
plt.fill_between(x, y, where=(x >= -3) & (x <= 3),
color=colors[2], alpha=0.3, label='±3σ ≈ 99.7%')
# 그래프 꾸미기
ax.set_title('표준정규분포와 68-95-99.7 법칙', color='w')
ax.set_xlabel('z 값 (표준화 점수)', color='w')
ax.set_ylabel('확률밀도', color='w')
plt.legend()
ax.tick_params(colors='w')
ax.spines['bottom'].set_color('w')
ax.spines['left'].set_color('w')
plt.gca().set_axisbelow(True)
plt.grid(axis='x', alpha=0.3, color='lightgray')
plt.show()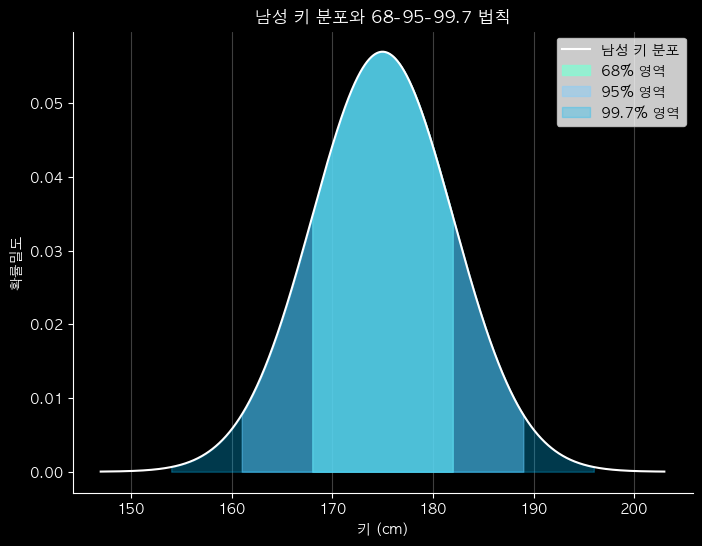 |
 |
" 정규 근사, 정규 경계 "
정규 근사
- 키, 몸무게 : 유전, 환경, 영양 등 작은 요인들이 합쳐져 평균 근처에 몰림
- 시험 점수(대규모) : 여러 요인이 겹쳐 평균 중심으로 몰림, 양극단은 드묾
- 측정 오차 : 수많은 작은 오차가 더해져 평균값 근처에 모임 → 이런 데이터는 정규 가정을 해도 큰 문제 없음
정규 경계
- 소득, 매출 : 대부분 적고 소수만 매우 큼 → 오른쪽 꼬리 긴 분포 (로그정규, 파레토)
- 주식 수익률, 트래픽 : 가끔 발생하는 극단적 큰 변동 → heavy-tail 분포
- 이탈률, 성공/실패 : 결과가 0 / 1 → 이항분포
" 예언구간, 신뢰구간 "
예언구간(예측구간)(Prediction Interval, PI)
- 새로운 단일 관측값 또는 미래 데이터가 들어올 범위
- 범위를 넓히면 적중률 ↑, 의미 ↓
- 개별 값의 불확실성
특징
- 데이터의 변동성을 포함
- 평균 추정 불확실성 + 데이터 개별 관측값의 변동성 포함
- 폭이 항상 신뢰구간보다 넓음
- 개별 관측값은 평균 주변에서 더 넓게 퍼질 수 있으므로
- 신뢰수준 적용 가능
- ex) 95% PI = “새로 뽑은 데이터가 95% 확률로 이 구간 안에 들어간다”
계산
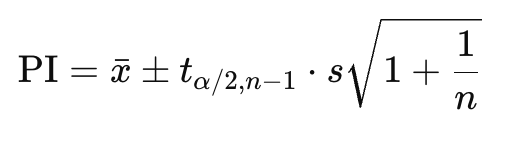
- √(1+1/n) 때문에 CI보다 항상 폭이 넓음
- 모집단 δ를 아는 경우에는 s대신 δ를 사용
- 다만, 현실에서는 δ를 모를 때가 많아 표본 기반으로 구함
신뢰구간(Confidence Interval, CI)
- 모집단의 평균(μ) 또는 모수(parameter) 즉, 우리가 알고 싶은 것을 추정하기 위한 구간
- 표본을 하나만 뽑으면 모평균을 정확히 알 수 없으므로, 추정값 주변에 범위를 만든 것
- 정확성을 높이기 위해 구간으로 추정
- 평균 추정의 불확실성
특징
- 모평균을 포함하는 범위
- 신뢰구간은 개별 데이터가 아니라 모평균(μ)에 대한 불확실성을 표현
- 표본 크기(n)가 커질수록 좁아짐
- 좁아짐 = 추정이 정밀해짐
- 신뢰수준(Confidence Level, 1-α)
- 95% CI = “같은 방식으로 표본을 여러 번 뽑으면 95%의 신뢰구간이 실제 모평균을 포함한다"
계산

- 표본 평균 ± 표준오차(SE) × 신뢰계수(z 또는 t)
예시
- 하한 단측
- 상황 : 배터리 제조사가 "최소 500시간 이상 작동"을 보장하려 함
- 10개 배터리 테스트 결과 : 502, 495, 510, 508, 497, 505, 498, 512, 503, 499시간
- 평균 수명 : 502.9시간, 표준편차 : 5.8시간
- 95% 하한 신뢰구간: [498.6시간, +∞]
- "95% 신뢰수준으로 평균 배터리 수명이 최소 498.6시간 이상이지만, 500시간을 보장하기는 어려움"
- 상한 단측
- 상황 : 품질관리팀이 "불량률이 최대 5% 이하"임을 확인하려 함
- 10회 검사에서 100개당 불량 개수 : 3, 2, 4, 3, 5, 2, 3, 4, 2, 3개
- 평균 불량률 : 3.1%, 표준편차 : 0.99%
- 95% 상한 신뢰구간: [-∞, 3.7%]
- "95%의 신뢰수준으로 평균 불량률이 최대 3.7% 이하이므로, 5% 품질 기준을 충족함"
- 양측 검정
- 상황 : 신약이 혈압을 평균적으로 얼마나 낮추는지 확인
- 30명 환자의 혈압 감소량 측정
- 평균 감소 : 12.5 mmHg, 표준오차 : 2.3 mmHg
- 95% 양측 신뢰구간: [7.8, 17.2] mmHg
- "95% 신뢰수준으로 이 약은 평균적으로 7.8~17.2 mmHg 혈압을 낮춤"
def coverage_experiment(series, n=25, reps=400, alpha=0.05, seed=7):
# n = 표본 크기(개수)
# reps = 실험을 몇번 반복할지?
# alpha = 유의수준 (0.5면 95% 신뢰구간)
rng = np.random.default_rng(seed) # PCG64 라는 알고리즘을 쓰는 난수 생성기, 최근 더 안정적이고 빠르다고 인정받는 최신 알고리즘
mu_true = series.mean()
intervals = []
hits = 0
for i in range(reps):
idx = rng.integers(0, len(series), size=n)
smp = series.to_numpy()[idx]
lo, hi, *_ = ci_for_mean_t(smp, alpha=alpha)
intervals.append((lo, hi))
hits += int(lo <= mu_true <= hi)
return mu_true, intervals, hits / reps
mu_true, intervals, cov = coverage_experiment(df["target"], n=25, reps=400, alpha=0.05, seed=11)
fig = plt.figure(figsize=(12,8), facecolor='k')
ax = fig.add_subplot()
ax.patch.set_facecolor('k')
k = 40
for i, (lo_i, hi_i) in enumerate(intervals[:k]):
if lo_i <= mu_true <= hi_i:
color = 'skyblue' # 포함되는 경우 파란색
else:
color = '#CD5C5C' # 포함되지 않는 경우 빨간색
plt.plot([lo_i, hi_i], [i, i], marker="|", color=color, markersize=10)
plt.axvline(mu_true, linestyle="--", color='lightgreen', alpha=0.7)
ax.set_title(f"Coverage experiment (first {k} CIs), estimated coverage≈{cov:.3f}", color='w')
ax.set_xlabel('target', color='w')
ax.set_ylabel('sample index', color='w')
ax.tick_params(colors='w')
ax.spines['bottom'].set_color('w')
ax.spines['left'].set_color('w')
plt.show()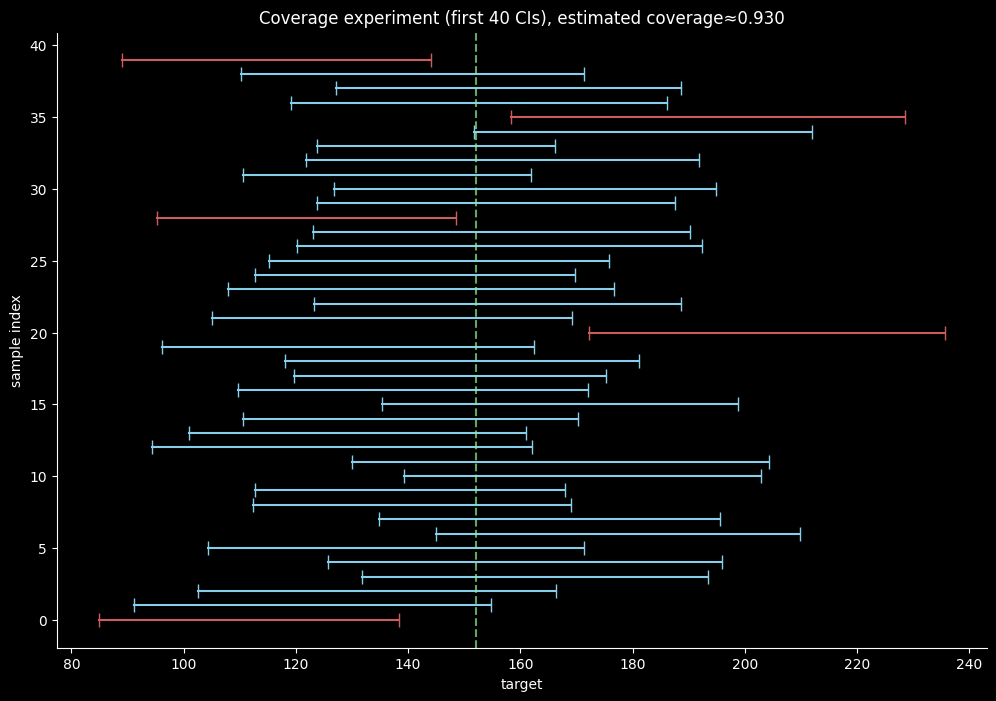
표본의 무작위성, 대표성, 독립성이 보장되지 않으면 추정은 왜곡된다
" 표본오차, 표준오차 "
표본오차(Sampling Error)
- 표본 통계량과 모집단 모수 사이의 차이
- 자연스러운 현상
- 모집단 전체를 조사할 수 없어서 무작위로 표본을 추출하여 조사함
- 뽑힌 사람/데이터가 매번 다르기 때문에 통계량도 매번 달라짐
큰 수의 법칙
- 표본의 크기가 커질수록 표본평균은 모집단 평균에 수렴
- 표본의 크기가 커질수록 표본오차는 줄어들음
표준오차(Standard Error, SE)
- 표본 평균들의 모평균에 대한 변동성(표준편차)
- 통계량의 불확실성을 나타냄
계산
- SE = s√n
- 표본의 크기가 커질수록 표준오차는 줄어들음
표본이 크면 표본오차는 줄고, 표준오차는 작아지고, 신뢰구간이 좁아짐
def avg_ci_width_vs_n(series, ns=(10, 20, 30, 50, 100, 200), reps=300, seed=2024):
rng = np.random.default_rng(seed)
widths = []
for n in ns:
ws = []
for _ in range(reps):
idx = rng.integers(0, len(series), size=n) # 0부터 len(series)-1까지 정수 중에서 n개를 복원 추출 -> 즉 series에서 n개의 임의 표본을 뽑음
smp = series.to_numpy()[idx]
lo, hi, *_ = ci_for_mean_t(smp)
ws.append(hi - lo)
widths.append(np.mean(ws))
return np.array(ns), np.array(widths)
ns, widths = avg_ci_width_vs_n(df["target"], ns=(10, 20, 30, 50, 100, 200), reps=200)
fig = plt.figure(figsize=(8,6), facecolor='k')
ax = fig.add_subplot()
ax.patch.set_facecolor('k')
plt.plot(ns, widths, marker="o", color='#7FFFD4', markerfacecolor='#87CEFA')
ax.set_title("CI width vs n (real data resampling)", color='w')
ax.set_xlabel('sample size n', color='w')
ax.set_ylabel('Average 95% CI width', color='w')
ax.tick_params(colors='w')
ax.spines['bottom'].set_color('w')
ax.spines['left'].set_color('w')
plt.gca().set_axisbelow(True)
plt.grid(axis='y', color = 'lightgray', linewidth = 0.3)
plt.show()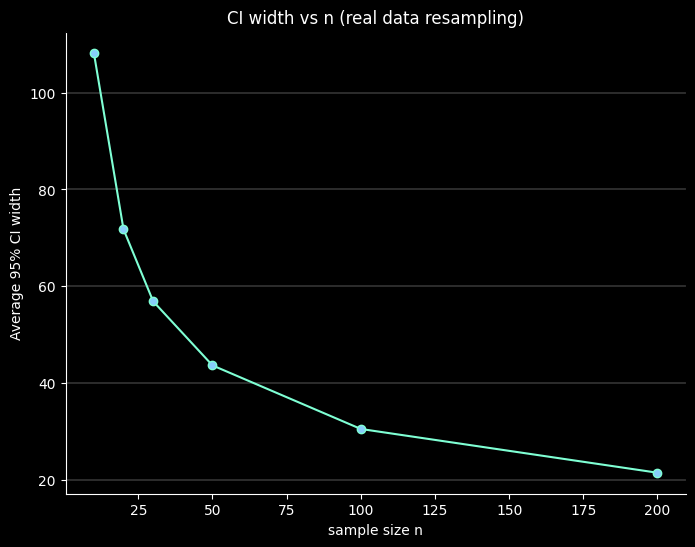

화이팅구리

1빠 마초녀의 벨로그는 계속된다