
" 회귀 "
회귀(Regression)
독립 변수(X)가 종속 변수(Y)에 미치는 영향을 모델링하고, 이를 통해 예측하거나 관계를 이해하는 통계 기법
목표
- 데이터 분포를 가장 잘 설명하는 '최적의 선(Best-fit line)'을 찾는 것
- 독립 변수(원인)의 변화에 따라 종속 변수(결과)가 어떻게 변화하는지를 나타냄
변수
- 독립변수 : X, 원인 → 결과에 영향을 미치는 변수
- 종속변수 : Y, 결과 → 독립변수의 영향을 받는 변수, 예측하려는 값
종류
- 선형 회귀
- 단순 선형 회귀 : 하나의 독립변수, 하나의 종속변수
- 다중 선형 회귀 : 2개 이상의 독립변수, 하나의 종속변수
- 로지스틱 회귀
- 종속 변수가 범주형 데이터
- 비선형 회귀
- 다항 회귀 : 데이터의 관계가 직선이 아닌 곡선 형태
- 스플라인 회귀 : 구간별 다항식을 적용하여 지그재그 형태
" 선형 회귀 "
선형 회귀
독립 변수(X)가 종속 변수(Y)에 미치는 영향을 직선(선형)으로 모델링하는 방법
가정(공통 전제 조건)
- 선형성 : X와 Y 관계가 선형적
- 독립성 : 오차들이 서로 독립
- 등분산성 : 오차 분산이 일정
- 정규성 : 오차가 정규분포를 따름
- 다중공선성 없음(다중회귀 전용) : 독립 변수들끼리 강하게 상관되지 않아야 함
단순 선형 회귀
회귀식
- Y = β0 + β1X + ϵ
- β0 = 절편, β1 = 기울기, ϵ = 오차항
특징
- 한 가지 요인이 결과에 얼마나 영향을 주는지
- 데이터가 직선적 경향을 따를 때 사용
- 간단하고 해석이 용이함
사례
- 광고비와 매출 간의 관계 분석
- 현재의 광고비를 바탕으로 예상되는 매출을 예측 가능
# 예시 데이터 생성
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 단순선형회귀 모델 생성 및 훈련
model = LinearRegression()
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 회귀 계수 및 절편 출력
print(f"회귀 계수: {model.coef_[0,0]:.3f}")
print(f"절편: {model.intercept_[0]:.3f}")
# 모델 평가
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"평균 제곱 오차(MSE): {mse:.3f}")
print(f"결정 계수(R2): {r2:.3f}")
# 시각화
plt.scatter(X, y, color='blue')
plt.plot(X_test, y_pred, color='red', linewidth=2)
plt.title('linear regeression')
plt.xlabel('X : cost')
plt.ylabel('Y : sales')
plt.show()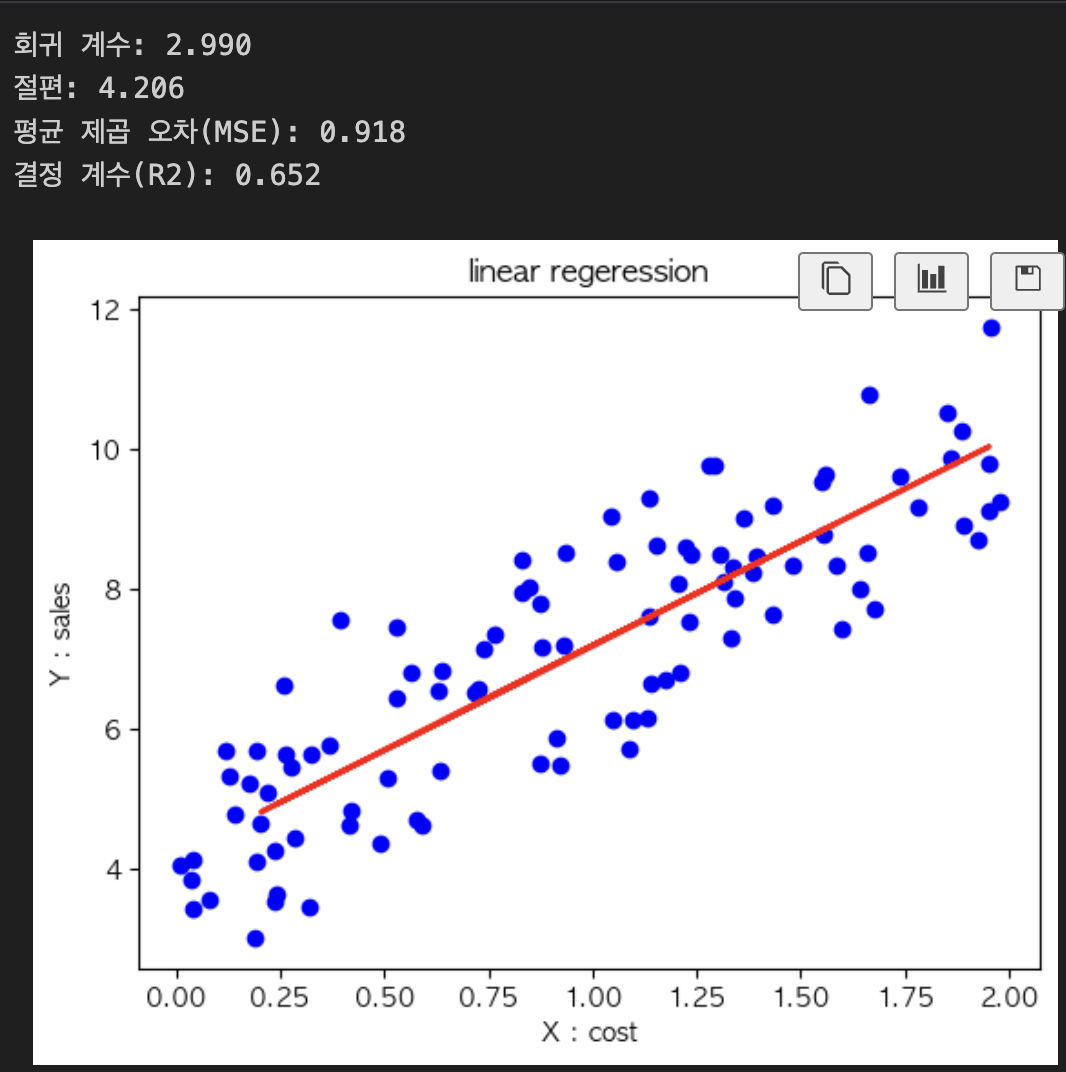
다중 선형 회귀
회귀식
- Y = β0 + β1X1 + β2X2 + ⋯ + βpXp + ϵ
- β0 = 절편, β1 = 기울기
특징
- 여러 요인이 동시에 결과에 어떻게 영향을 주는지
- 독립변수가 여러개일 때 사용
- 여러 변수의 영향을 동시에 분석할 수 있음
- 변수들 간 다중공선성 문제가 발생할 수 있음
다중공선성
- 독립변수들 간에 높은 상관관계가 있는 경우
- 모델의 성능과 해석에 문제를 일으킬 수 있음
- 각 변수의 개별적인 효과를 분리하기 어려워 해석이 어려워짐
- 실제로 중요한 변수가 통계적으로 유의하지 않게 나타날 수 있음
- 진단 방법
- 변수 간 상관계수 계산
- 분산팽창지수(VIF) ≥ 10 : 심각한 다중공선성 문제
- 해결 방법
- 높은 상관계수를 가진 변수 중 하나를 제거
- 주성분분석(PCA) 등의 차원 축소 방법 적용 등
사례
- 다양한 광고비(TV, Radio, Newspaper)와 매출 간의 관계 분석
- 현재의 광고비(TV, Radio, Newspaper)를 바탕으로 예상되는 매출을 예측 가능
# 예시 데이터 생성
data = {'TV': np.random.rand(100) * 100,
'Radio': np.random.rand(100) * 50,
'Newspaper': np.random.rand(100) * 30,
'Sales': np.random.rand(100) * 100}
df = pd.DataFrame(data)
# 독립 변수(X)와 종속 변수(Y) 설정
X = df[['TV', 'Radio', 'Newspaper']]
y = df['Sales']
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 다중선형회귀 모델 생성 및 훈련
model = LinearRegression()
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 회귀 계수 및 절편 출력
print(f"회귀 계수: {model.coef_[0]:.3f}")
print(f"절편: {model.intercept_:.3f}")
# 모델 평가
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"평균 제곱 오차(MSE): {mse:.3f}")
print(f"결정 계수(R2): {r2:.3f}")
" 범주형 회귀 "
범주형 데이터는 인코딩하여 사용
순서가 있는 경우 : XL → 3, L → 2, M → 1, S → 0
순서가 없는 경우 : 부산 = [1,0,0], 대전 = [0,1,0], 서울 = [0,0,1]
# 예시 데이터 생성
data = {'Gender': ['Male', 'Female', 'Female', 'Male', 'Male'],
'Experience': [5, 7, 10, 3, 8],
'Salary': [50, 60, 65, 40, 55]}
df = pd.DataFrame(data)
# 범주형 변수 더미 변수로 변환
df = pd.get_dummies(df, drop_first=True) # drop_first=True : 범주형 변수 중 1개를 빼는 것 -> male컬럼의 false = female 이므로 female 컬럼이 따로 필요 x, 오히려 있으면 다중공선성 문제 발생할 수 있음
# 독립 변수(X)와 종속 변수(Y) 설정
X = df[['Experience', 'Gender_Male']]
y = df['Salary']
# 단순선형회귀 모델 생성 및 훈련
model = LinearRegression()
model.fit(X, y)
# 예측
y_pred = model.predict(X)
# 회귀 계수 및 절편 출력
print(f"회귀 계수: {model.coef_[0]:.3f}")
print(f"절편: {model.intercept_:.3f}")
# 모델 평가
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"평균 제곱 오차(MSE): {mse:.3f}")
print(f"결정 계수(R2): {r2:.3f}")
로지스틱 회귀
종속 변수 Y가 범주형(특히 이항, 0 / 1)일 때 사용, 분류 모델
선형회귀처럼 단순히 직선으로 예측하지 않고, 시그모이드 함수(로짓 함수)를 통해 0~1 사이의 확률로 변환
회귀식
- P(Y=1 ∣ X) = 1 / (1 + e −(β0 + β1X))
- 회귀계수(β) : X가 한 단위 증가할 때 log-odds가 얼마나 변하는지
- 오즈비(Odds Ratio, OR)
- OR > 1 : X 증가 시, Y=1일 확률이 커짐
- OR < 1 → X 증가 시, Y=1일 확률이 줄어듦
- p-값 : X가 종속 변수에 유의미한 영향을 미치는지 판단
- 적합도 지표 : 정확도, ROC-AUC, 로그우도 등
종류
- 이항 로지스틱 회귀
- Y가 0 / 1
- 합격(1) / 불합격(0), 스팸(1) / 정상(0)
- 다항 로지스틱 회귀
- Y가 3개 이상 범주
- 브랜드 선호(A, B, C)
- 순서형 로지스틱 회귀
- Y가 순서형 범주
- 고객 만족도 (불만족 < 보통 < 만족)
사례
- 의학 : 환자가 질병(1) vs 정상(0)
- 마케팅 : 고객이 상품을 구매(1) vs 미구매(0)
- 금융 : 대출 상환(1) vs 연체(0)
- 머신러닝 : 분류 문제(스팸메일 탐지, 고객 이탈 예측 등)
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 생성 (공부 시간에 따른 합격 여부)
np.random.seed(0)
X = np.random.randint(1, 10, size=(50, 1)) # 공부 시간
y = (X.flatten() + np.random.randn(50) > 5).astype(int) # 1=합격, 0=불합격
# 모델 학습
model = LogisticRegression()
model.fit(X, y)
# 예측
y_pred = model.predict(X)
print("정확도:", accuracy_score(y, y_pred))
print(f"회귀계수: {model.coef_[0,0]:.3f}")
print(f"절편: {model.intercept_[0]:.3f}")
" 비선형 회귀 "
비선형 회귀
종속변수 Y와 독립변수 X의 관계가 직선이 아닌 곡선일 때 사용
장점 : 현실 데이터를 더 잘 설명해서 선형 모델보다 예측 정확도를 높일 수 있음
단점 : 해석이 어렵고 계산이 복잡하며 과적합의 위험이 있음
다항 회귀
데이터가 곡선적 경향을 보일 때 사용
회귀식
- Y=β0 + β1X + β2X2 + β3X3 + ⋯ + βpXp + ϵ
특징
- 곡선 관계를 표현할 수 있음
- 구현이 간단 (선형회귀와 동일한 방식, 변수만 X2, X3 등 추가)
- 차수가 커지면 모델이 지나치게 출렁임 (과적합 위험)
- 데이터 범위 밖에서는 예측이 불안정
# 예시 데이터 생성
np.random.seed(0)
X = 2 - 3 * np.random.normal(0, 1, 100)
y = X - 2 * (X ** 2) + np.random.normal(-3, 3, 100)
X = X[:, np.newaxis]
# 다항 회귀 (2차)
polynomial_features = PolynomialFeatures(degree=2)
X_poly = polynomial_features.fit_transform(X)
model = LinearRegression()
model.fit(X_poly, y)
y_poly_pred = model.predict(X_poly)
# 모델 평가
mse = mean_squared_error(y, y_poly_pred)
r2 = r2_score(y, y_poly_pred)
print(f"평균 제곱 오차(MSE): {mse:.3f}")
print(f"결정 계수(R2): {r2:.3f}")
# 시각화
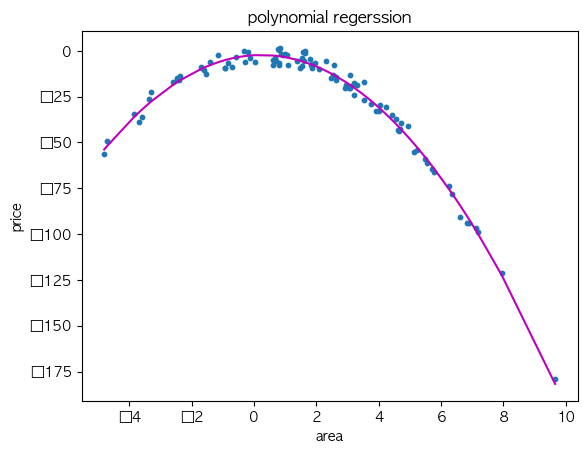
plt.scatter(X, y, s=10)
# 정렬된 X 값에 따른 y 값 예측
sorted_zip = sorted(zip(X, y_poly_pred))
X, y_poly_pred = zip(*sorted_zip)
plt.plot(X, y_poly_pred, color='m')
plt.title('polynomial regerssion')
plt.xlabel('area')
plt.ylabel('price')
plt.show()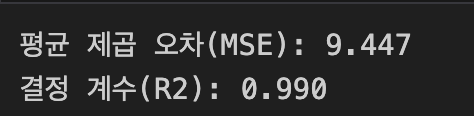
스플라인 회귀
데이터가 국부적으로 다른 패턴을 보일 때 사용
회귀식
- Y = β0 + β1X + β2(X−k)+ + ϵ
- ((X − k)+ : X > k일 때만 값이 있는 함수
- 즉, X가 특정 구간을 넘어가면 새로운 다항식을 추가
특징
- 국소적인(curve 부분별) 곡선 적용이 가능
- 데이터의 곡선 구조를 유연하게 반영 가능
- 과적합 위험을 줄이면서도 복잡한 패턴 설명 가능
- 매듭(knot) 위치를 어떻게 설정하느냐가 성능에 큰 영향을 줌

화이팅구리

정신 체리자 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 아 웃기네