
✏️ 머신러닝
- 규칙을 일일이 프로그래밍 하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 통계학과 관련
- 대표 머신러닝 라이브러리 : 사이킷런 (scikit -learn)
💡 사이킷 런(sklearn)이란?
- 2007년 구글 썸머 코드에서 처음 구현됐으며 현재 파이썬으로 구현된 가장 유명한 기계 학습 오픈 소스 라이브러리
- 다양한 분류기를 지원하며 머신러닝 결과를 검증하는 기능 보유
- 또한 분류, 회기, 클러스터링, 차원 축소처럼 머신러닝에 자주 사용되는 다양한 알고리즘을 지원
import sklearn💡 명령어 & 용어 정리
1. zip()
name = ['merona', 'gugucon']
price = [500, 1000]
z = zip(name, price)
print(list(z))
>>> [('merona', 500), ('gugucon', 1000)]name = ['merona', 'gugucon']
price = [500, 1000]
for n, p in zip(name, price):
print([n, p])
혹은
[n, p] for n, p in zip(name, price)
>>>
[[merona,500],[gugucon,1000]]2. numpy
- 배열 라이브러리 (고차원적인 배열 가능)
2-1. .column_stack : numpy로 zip같은 기능 사용하기
import numpy as np
f_data=np.column_stack(([1,2,3],[4,5,6]))
f_data
>>>
array([[1, 4],
[2, 5],
[3, 6]])import numpy as np
f_data=np.column_stack((f_length, f_weight)
f_data[:5]
>>>
array([[ 25.4, 242. ],
[ 26.3, 290. ],
[ 26.5, 340. ],
[ 29. , 363. ],
[ 29. , 430. ]])2-2. 배열 : 열(특성수), 행(샘플수)
import numpy as np
name = ['merona', 'gugucon','pigbar']
price = [500, 1000, 600]
list = [n, p] for n, p in zip(name, price)
list_array= np.array(list)
>>>
[[merona,500]
[gugucon,1000]
[pigbar, 600]
print(list_array.shape) #numpy array로 정렬된 형태 확인하기
>>>
(3,2) #3행2열 2-3. 1씩 증가하는 인덱스 만들기
# 0 ~ 48까지 1씩 증가하는 배열
index=np.arrage(49)
print(index)
>>>
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48])2-4. train_test_split 하거나 numpy로 무작위 셔플링하기
np.random.shuffle(index)
print(index)
>>>
[13 45 47 44 17 27 26 25 31 19 12 4 34 8 3 6 40 41 46 15 9 16 24 33
30 0 43 32 5 29 11 36 1 21 2 37 35 23 39 10 22 18 48 20 7 42 14 28
38]2-5. 배열에서 가장 큰 값의 인덱스 반환
배열의 첫 번째 원소가 가장 큰 값일 경우, 인덱스 0 반환
val_labels = np.argmax(model.predict(val_scaled),axis=-1)
#predict(val_scaled)의 마지막 차원(-1)의 최대 인덱스 값
print(np.mean(val_labels == val_target))
#val_labels & val_target 비교후 위치가 같으면 1, 다르면 0
#이를 평균하면 정확도3. 파라미터(매개변수) & 하이퍼파라미터
✏️ 머신러닝 시작
💡 특성 공학 (feature engineering)
- 기존의 특성을 사용해 새로운 특성을 뽑아내는 작업 (혼공머신 4쇄 :99p
#평균
mean = np.mean(X_train, axis=0)
#표준편차
std=np.std(X_train, axis=0)
#표준점수
std_score=(X_train-mean)/std
#polynomialFeatures
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures()
poly.fit([[n,m]])
poly.transform([[n,m]])
>>>
1,n,m,n^2,n*m,m^2
#1을 없애고 싶으면 poly = PolynomialFeatures(include_bias=False)
#5제곱까지 하고 싶으면 poly = PolynomialFeatures(degree=5)
##하지만 너무 상세히 특성을 정리하면 과대적합(overfitting)됨💡 train_test_split
- sklearn.model_selection.train_test_split
- train set(학습 데이터 세트)과 test set(테스트 세트)을 분리
- X_train : 학습 데이터 셋의 feature 부분
X_test : 테스트 데이터 셋의 feature 부분
y_train : 학습 데이터 셋의 label 부분
y_test : 테스트 데이터 셋의 label 부분- stratify 파라미터로 무작위 섞은 후 트레인 세트와 테스트 세트 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)| 파라미터 (Parameters) | 설명 |
|---|---|
| test_size | - test set 구성의 비율 - train_size의 옵션과 반대 관계에 있는 옵션 값, 주로 test_size를 지정 - default 값은 0.25 (ex - 0.2일때 전체 data set의 20%를 test (validation) set으로 지정하겠다는 의미) |
| random_state | - 세트를 섞을 때 해당 int 값을 보고 섞으며, 하이퍼 파라미터를 튜닝시 이 값을 고정해두고 튜닝해야 매번 데이터셋이 변경되는 것을 방지할 수 있음 |
| shuffle | - default=True - split을 해주기 이전에 섞을건지 여부 확인. 보통은 default 값으로 유지 |
| stratify | - default=None - 데이터 편향 방지, 골고루 섞이게 해줌 - classification을 다룰 때 매우 중요한 옵션값 stratify 값을 target으로 지정해주면 각각의 class 비율(ratio)을 train / validation에 유지 (한 쪽에 쏠려서 분배되는 것을 방지) 자세한 내용 하기 출처 확인 |
💡 label_encoder
- sklearn.preprocessing.LabelEncoder
- 문자를 0부터 시작하는 정수형 숫자로 바꿔주는 기능
- 코드숫자를 이용하여 원본 값 구함 (반대 기능)
from sklearn.preprocessing import LabelEncoder| Methods - y값에 DataFrame도 사용 가능ex)le.fit(df['A']) | 설명 |
|---|---|
| le.fit(y) | - 사이킷 런 모델 훈련시 사용하는 메서드 - 처음 두 매개변수로 훈련에 사용할 특성과 정답 데이터 전달 - Fit label encoder - y를 학습시킴 |
| le.transform(y) | - Transform labels to normalized encoding. - fit을 기준으로 얻은 mean,variance에 맞춰 변형 - fit 시킨 변수를 숫자로 변환 - 일종의 fit으로 학습시킨 것을 적용하는 메서드 |
| le.fit_transform(y) | - Fit label encoder and return encoded labels - fit과 transform을 한번에 진행함 |
| le.inverse_transform(y) | - Transform labels back to original encoding. - 숫자를 문자로 변환 |
| le.get_metadata_routing() | Get metadata routing of this object. |
| le.get_params([deep]) | Get parameters for this estimator. |
| le.set_output(*[, transform]) | Set output container. |
| le.set_params(**params) | Set the parameters of this estimator. |
>>> from sklearn.preprocessing import LabelEncoder
>>> le = LabelEncoder()
# fit : [1,2,2,6]을 학습 시킴
>>> le.fit([1, 2, 2, 6])
LabelEncoder()
#.class_ : fit시킨 le라는 변수에 학습된 소스 확인
>>> le.classes_
array([1, 2, 6])
# fit을 한 다음에 transform 시키기
>>> le.transform([1, 1, 2, 6])
array([0, 0, 1, 2]...)
>>> le.inverse_transform([0, 0, 1, 2])
array([1, 1, 2, 6])
💡 .score : 평가하기
- 정확도 = (정확히 맞힌 개수) / (전체 데이터 개수)
- 과대적합 : 훈련 세트 점수는 좋으나 테스트 세트 점수가 안 좋을 경우
- 과소적합 : 훈련 세트보다 테스트 세트 점수가 높을 경우, 두 점수 모두 낮을 경우 (모델이 단순할 경우 발생함) => 훈련 세트의 점수를 높여줌 ex)KNN일 경우, n_neighbors를 5에서 3으로 낮추기
kn=KNeighborsClassifier()
kn.fit(a_data, a_target)
kn.score(b_data, a_target) #b_data의 답을 b_target이라고 kn머신 학습된 것에 돌렸을 때의 점수(..이게 맞는건강..?)💡 .predict : 학습된 데이터로 예측하기
#위 데이터 이어서
kn.predict([[30,600]])
>> array([1]) #"1(도미)에 해당한다"💡 .predict_proba : 예측 확률
#lr 타겟이 2개 일 경우 (타겟 알파벳순)
lr.predict_proba(train_X[:5])
>>>
array([[0.99759855, 0.00240145],
[0.02735183, 0.97264817],
[0.99486072, 0.00513928],
[0.98584202, 0.01415798],
[0.99767269, 0.00232731]])💡 .evaluate()
- 성능 평가
- compile() 메서드 (딥러닝)가 먼저 실행되어야 함
💡 accuracy
from sklearn.metrics import accuracy_score.score() / .evaluate() / .accuracy() 차이 비교해보기
✏️ 학습 & 훈련
💡 학습
| 학습 종류 | 설명 |
|---|---|
| 지도 학습 (supervised Learning) | - 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는데 활용 - 훈련 데이터 필요 ex) K-최근접 이웃 |
| 비지도 학습 (Unsupervised Learning) | - 입력 데이터만 있을 때 사용(타깃 데이터가 없음) - 입력 데이터에서 특징 & 경향을 찾기 위해 사용, 예측 용도 X<br ex) 군집(clustering), 차원 축소 |
- 훈련 데이터 (Training Data)(.fit)
- 입력 (input) : 데이터
- 타깃 (target) : 정답 (1인지 0인지)
#numpy를 활용해 타깃 데이터 만들기 (1 : 35개, 0 : 14개)
f_target=np.concatenate((np.ones(35),np.zeros(14)))
f_target
>>>
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])- 특성 : 데이터를 표현하는 하나의 성질
ex) 생선 데이터 각각의 길이와 무게
💡 지도 학습 - 훈련
- 샘플링 편향 : 샘플링이 한쪽으로 치우쳐져 있는 상황
- 샘플링 편향을 피하기 위해 훈련 세트와 테스트 세트를 나누기 전 데이터를 충분히 골고루 섞여있어야 함
- 참고 페이지 : [머신러닝] ✨머신러닝 베이직 & 모델 클래스 (feat. sklearn, 사이킷 런)✨ >> 💡 샘플 섞기
| 훈련 종류 | 설명 |
|---|---|
| 훈련 세트 | - 모델을 훈련할 때 사용 - 훈련세트가 클수록 좋음 - 테스트 세트를 제외한 모든 데이터 사용 - 2차원 배열이여야 함 (1차 배열이라도 2차원 배열로 만들기) ex) .reshape(n행,y열) 사용 |
| 테스트 세트 | - 통상 전체 데이터에서 20~30% 사용 |
- numpy.reshape(a, newshape, order='C')
- a: 변경하려는 배열
- newshape: 변경하려는 배열의 새로운 shape
- order: 배열의 요소 순서. 'C'(기본값)는 C 언어 스타일의 요소 순서, 'F'는 포트란 스타일의 요소 순서 ({‘C’, ‘F’, ‘A’},optional)
- a.reshape(-1,n) : n열에 맞춰서 행 자동 셋팅
- a.reshape(n,-1) : n행에 맞춰서 열 자동 셋팅
a = np.arange(9)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8])
a.reshape(3, 3)
>>>
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])a = np.arange(9)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8])
np.reshape(a, (3, 3))
>>>
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])💡 지도 학습 - 과대적합 & 과소적합
1. 과대적합 -> 규제
- 훈련 세트가 과도한 학습을 못하도록 훼방
- 예시
선형 회귀 모델 : 특성에 곱해지는 계수 (혹은 기울기)의 크기 축소
2. 과소적합 -> 특성 세분화
- 모델을 더 복잡하게 만들기
- 예시
이웃 : 이웃 범위를 줄이기
💡 Data Scaling
[Python] 어떤 스케일러를 쓸 것인가?
[ML] 데이터 스케일링 (Data Scaling) 이란?
[데이터 전처리] 데이터 스케일링(StandardScaler, MinMaxScaler, RobustScaler)
- 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업을 의미
- 수치형 변수에만 적용
- 예시 ) K 이웃 모델, 계수에 곱이 들어갈 경우(릿지 혹은 라쏘)
1. 표준 점수
#표준점수
std_score=(X_train-mean)/std2. 표준화 (Standard Scaler)
- sklearn.preprocessing.StandardScaler
- 모든 피처들을 평균이 0, 분산이 1인 정규분포를 갖도록 만듬 (표준화해주는 방법) => 전체 피처를 ttl로 보고 그 중간을 평균 0
- 데이터 내에 이상치가 있다면 데이터의 평균과 분산에 크게 영향을 주기 때문에 스케일링 방법으로 적절하지 않음
from sklearn.preprocessing import StandardScaler
ss=StandardScaler()
ss.fit(X_train)
train_scaled=ss.transform(X_train)
test_scaled=ss.transform(X_test)3. 최소 최대 정규화 (MinmaxScaler)
- sklearn.preprocessing.MinMaxScaler
- 제일 작은 값을 0, 제일 큰 값을 1로 두어 계산
from sklearn.preprocessing import MinMaxScaler4. RobustScaler
- sklearn.preprocessing.RobustScaler
- StandardScaler와 비슷하지만 평균과 분산 대신 중간값(median)과 사분위값(quartile)을 사용
- 아주 동 떨어진 데이터(이상치)를 제거
- 이상치: 측정된 데이터 사이의 경향성을 지나치게 해치는 데이터 ex)측정 에러
from sklearn.preprocessing import RobustScalerfrom sklearn.preprocessing import RobustScaler
rs = robustscaler()
# df = robustscaler().fit_transform(df)
df=rs.fit_transform(df)모델 평가 (Model Evaluation)
머신러닝을 통해 예측하고자 하는 값에 따라 회귀와 분류로 모델 평가를 나눌 수 있다.
✏️ 클래스
💡 의사결정트리(Decision Tree)
- sklearn.tree.DecisionTreeClassifier
- 노드(node)
- 루트노드(Root Node) : 시작점
- 리프노드(Leaf Node) : 결정된 클래스 값
- 규칙노드/내부노드(Decision Node / Internal Node) : 데이터세트의 피처가 결합해 만들어진 분류를 위한 규칙조건
from sklearn.tree import DecisionTreeClassifier
변수명= DecisionTreeClassifier(random_state=0 ...)| 파라미터 (Parameters) | 설명 |
|---|---|
| max_depth | - 트리의 최대 깊이 - int - default=None 완벽하게 클래스 값이 결정될 때 까지 분할 or 데이터 개수가 min_samples_split보다 작아질 때까지 분할 (깊이가 깊어지면 과적합될 수 있으므로 적절히 제어 필요) |
| random_state | - int - default=None - Random_state를 None으로 두는 경우 Decisiontreeclassifier 함수를 이용해 Decision tree를 생성하면 그때그때 다른 데이터를 이용하기 때문에 결과가 바뀜 자세한 내용 하기 출처 확인 |
✏️ Pipeline
💡 파이프라인이란?
- sklearn.pipeline.Pipeline
- 전처리 ~ 학습까지의 과정을 하나로 연결
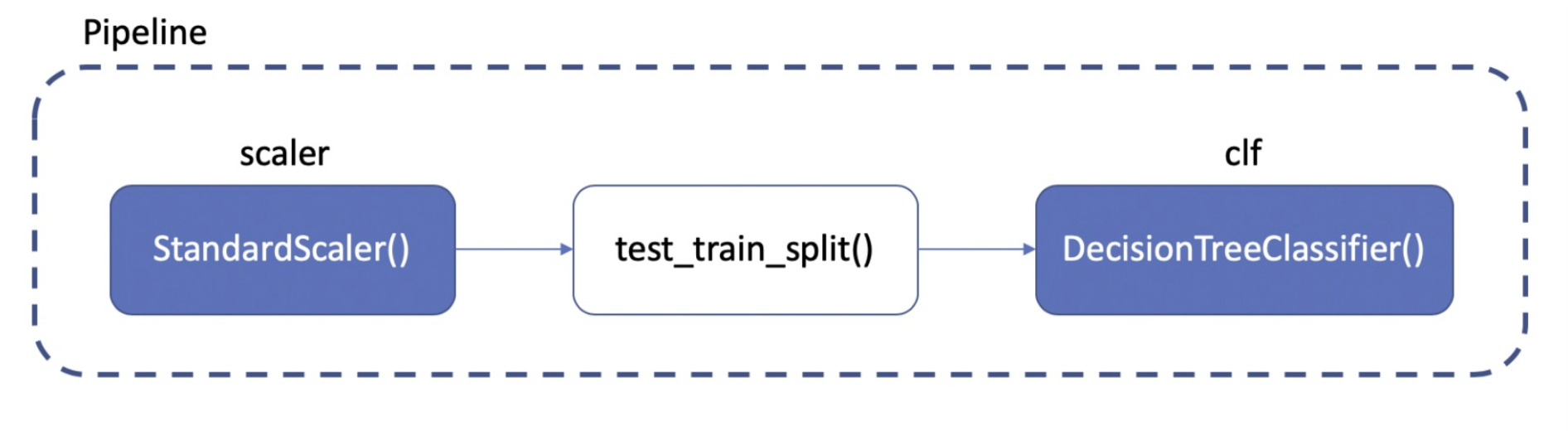

from sklearn.pipeline import Pipeline💡 코드
| Methods | 설명 |
|---|---|
| steps | - 단계 호출 |
| set_params(**kwargs) | - 각 스텝별 속성 설정 - **kwargs : 스텝이름__속성=값 - 언더바 2개 ‘__’ 필수 |
# 파이프 라인 만들기
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())])
#or
#estimaters = [('scaler', StandardScaler()), ('svc', SVC())]
#pipe = Pipeline(estimaters)
pipe.steps
>>> [('scaler', StandardScaler()), ('svc', SVC())]
pipe.steps[0]
>>>('scaler', StandardScaler())
pipe.steps[1]
>>>('svc', SVC())
pipe[0]
>>> StandardScaler
pipe['scaler']
>>> StandardScaler
pipe.set_params(svc__C=10).fit(X_train, y_train).score(X_test, y_test)
#or
#(svc__max_depth=2)
#(svc__random_state=13)# 학습 & 테스트
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=13)
## 원래대로라면 스케일링을 하고 분류기를 학습시키는 과정 필요
## but 이미 pipe에 진행 완료. 해서 아래 진행
pipe.fit(X_train,y_train)# 정확성 확인
from sklearn.metrics import accuracy_score
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print('Train Acc' : accracy_score(y_train, y_pred_tr)
print('Test Acc' : accracy_score(y_test, y_pred_test)✏️ 출처
'제로베이스 데이터 취업스쿨' 수강중
교재 '혼자 공부하는 머신러닝 + 딥러닝'
사이킷런으로 머신러닝 시작하기
토닥토닥 sklearn - 머신러닝
sklearn으로 데이터 스케일링(Data Scaling)하는 5가지 방법🔥
train_test_split 모듈을 활용하여 학습과 테스트 세트 분리
[Chapter 4. 분류] Decision Tree Classifier
Decisiontreeclassifier 함수의 파라미터 random_state란?
머신러닝 파이프라인
머신 러닝 - PipeLine
2.5.10. 싸이킷런(Scikit-learn)(Sklearn)

데린이인데요 ໒꒰ྀ ˶ • ༝ •˶ ꒱ྀིა (잘못 된 부분은 너그러이 알려주세요.)