퍼셉트론(Perceptron)
등장배경
Frank Rosenblatt가 1957년에 제안한 초기 형태의 인공 신경망, 다수의 입력으로 부터 하나의 결과를 내보내는 알고리즘.
단층 퍼셉트론(Single-Layer Perceptron)
- 각 입력값이 가중치와 곱해져 인공 뉴런에 보내지고, 각 입력값과 그에 해당하는 가중치의 곱의 전체 합이 입계치(threshold)를 넘으면 종착지에 있는 인공 뉴런은 출력 신호로서 1을 출력, 그렇지 않을 경우에는 0 출력 (계단 함수)
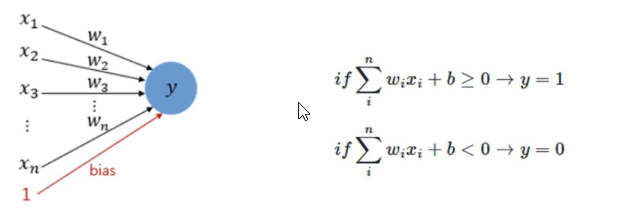
- 단층 퍼셉트론으로는 XOR(입력이 다르면 1, 같으면 0) 게이트조차 구현할 수 없음
- AND, NAND, OR 게이트는 구현 가능
def AND_gate(x1, x2):
w1 = 0.5
w2 = 0.5
b = -0.7
result = x1*w1 + x2*w2 + b
if result <= 0:
return 0
else:
return 1XOR 게이트
- 입력값 두 개가 서로 다른 값을 갖고 있을 때에만 출력값이 1이 되고, 입력값 두 개가 서로 같은 값을 가지면 출력값이 0이 되는 게이트
- 단층 퍼셉트론이 XOR의 구현이 불가능한 이유는 직선 하나로 두 영역을 나눌 수 있는 문제에 대해서만 구현이 가능하기 때문
용어 정리
피드 포워드 신경망(Feed Forward Neural Network)란
- 입력층에서 출력층으로 향하는 신경망
- 피드 포워드 신경망 중 가장 대표적이고 간단한 신경망은 다층 퍼셉트론
NNLM(Neural Network Language Model)
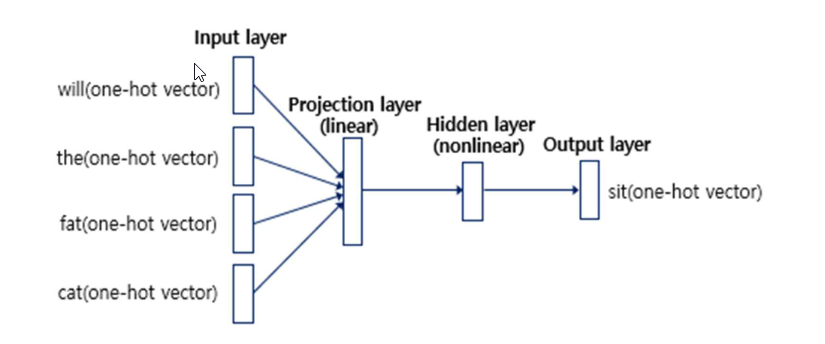
- n개의 이전 단어들로부터 n+1 단어를 예측하는 모델
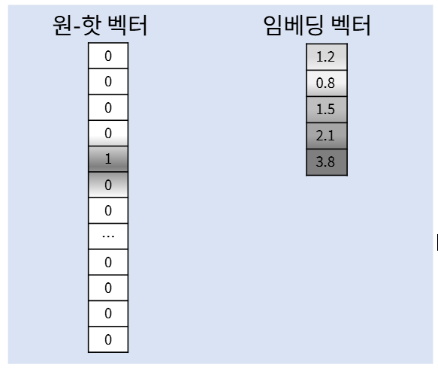
- 신경망의 입력은 원-핫 인코딩을 사용하여 얻은 원-핫 벡터로 한다.
Projection layer
- V 차원의 원-핫 벡터는 VxM 크기의 행렬과 곱해져 M 차원의 벡터를 얻는다.(Lookup table)
- Weight Matrix는 존재하지만 Bias는 사용하지 않고, 활성화 함수도 사용하지 않는다.
- 각 원-핫 벡터가 lookup table을 거치면 모두 concatenate된다. (concatenate -> 벡터를 단순히 나열)
- 투사층의 가중치 행렬 W의 각행은 각 단어와 맵핑 되는 밀집 벡터(Dense Vector)이다.
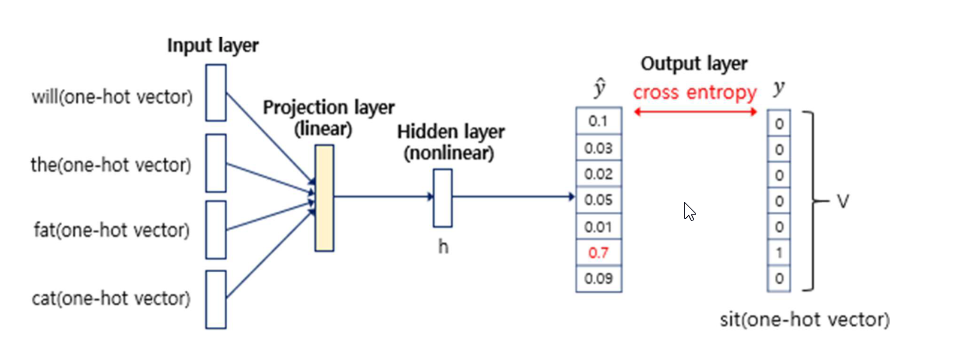
Hidden layer, Output layer
- Hidden layer를 거쳐 값을 구하고 cross entropy를 이용하여 평가하여 loss를 구하고 역전파하여 embedding table을 업데이트 한다.
Word Embedding
-
원-핫 인코딩으로 표현된 단어들은 단어의 의미를 반영한 유사도를 구할 수 없음
-
워드 임베딩을 사용하면 어떤 벡터가 어떤 다른 벡터과 가까운지 알 수 있다.
1) 랜덤 초기화 임베딩: NNLM과 마찬가지로 오차를 수하는 과정에서 embedding tale 학습
2) 사전 훈련된 임베딩(Pre-trained Word Embedding): embedding table을 freeze 하는 법과 fine-tuning 하는 방법이 있음
-
embedding layer = projection layer의 한 종류
-
실제 신경망을 구현할 때는 입력을 원-핫 벡터가 아니라 정수도 사용한다는 점

오랜시간 망설였던 코딩을 다시 해보려고 노력하고 있는 사람