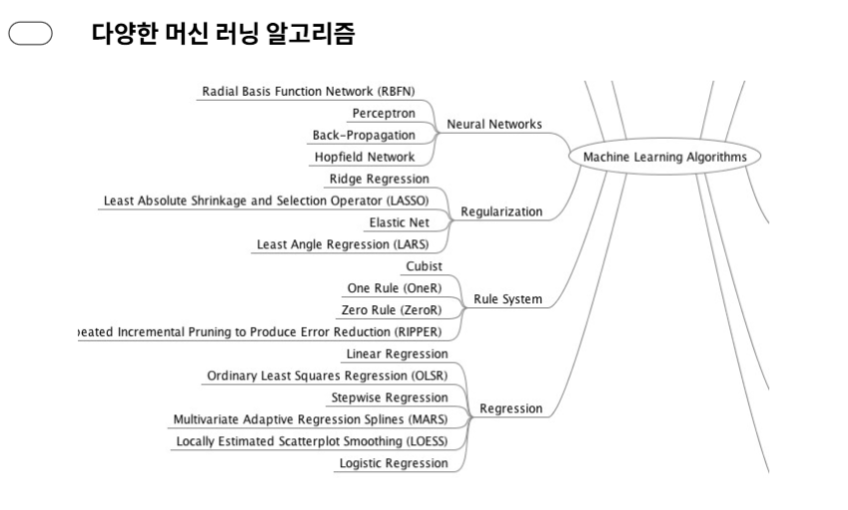
Machine Learning
기존 - 사람이 찾아서 기계에세 알려준다
머신 러닝 - 데이터를 많이 주고 기계가 찾게 한다
머신 러닝 모델의 기본적인 세 가지 과정
1) 학습을 위한 가설(Hypothesis)를 세움
2) 가설의 성능을 측정할 수 있는 손실 함수(Loss Function)을 정의한다.
3) 손실 함수 L을 최소할 수 있는 학습 알고리즘 설계
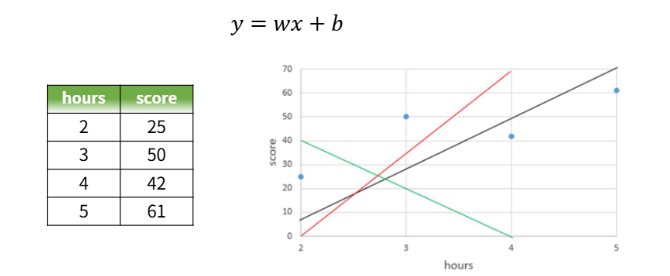
Linear Regression
-
데이터를 반영하는 가장 적절한 선을 긋는 작업
-
오차를 최소로 만드는 w와 b를 찾아내야 한다
-
기본적인 방법으로 모든 오차를 더해 오차를 알아낼 수 있는데, 음수와 양수가 섞여 있어서 제대로 된 오차의 양을 구할 수 없다.
MSE
- 그래서 MSE (Mean Square Error) - 모든 오차를 제곱해서 더하는 방법을 사용
- 이 모든 오차를 제곱해서 더한 값을 데이터의 개수 n으로 나누면 모든 데이터의 오차 평균을 얻을 수 있다. (평균 제곱 오차)

Cost Function
실제값과 예측값의 오차에 대한 식
목적함수(Objective function) = 비용 함수(Cost function) = 손실 함수(Loss function)
Gradient Descent
- 선형 회귀든 인공 신경망이든 비용 함수를 최소화 하는 매개 변수를 찾는 것이 목적
- 이 때 사용되는 알고리즘을 Optimizer라고 한다.
- 경사 하강법은 대표적인 옵티마이저 알고리즘
- 경사 하강법은 접선의 기울기 개념을 사용
- 경사 하강법은 최적의 값을 향해서 매개 변수를 반복 업데이트
- 비용 함수 W에 대해 미분하면 접선의 기울기를 얻음
- Learning rate를 너무 높게 준다고해서 최적의 값을 빨리 찾지는 않음
- 지나친 Learning rate는 오히려 이를 방해
- 만약 loss가 NaN이 나온다면, learning rate를 낮추는 걸 시도해볼 수 있음
Learning Rate는 사람이 정해주는 값인가?
- 정답은 없지만 팁으로 일반적으로 조금 큰 값에 시작해서 1/2씩 줄이는 방법이 있다.
- 하지만 가장 좋은 방법은 하고자 하는 Task에 대해서 높은 성능을 얻었던 모델에 대한 논문이 공개되었을 것이고, 해당 논문의 저자가 선택한 Learning Rate값을 사용하는 것이 좋음
Keras 이해하기
- Keras는 텐서플로우의 하이레벨 API. 텐서플로우 안에 Keras 존재
Keras를 이용한 모델링
1) 전처리: 학습에 필요한 데이터 전처리를 수행
2) 모델링(model): 모델을 정의
3) 컴파일(compile): 모델 생성
4) 학습(fit): 모델을 학습
Logistric Regression
-
두 개의 선택지 중에서 정답을 고르는 문제에 사용하는 모델
-
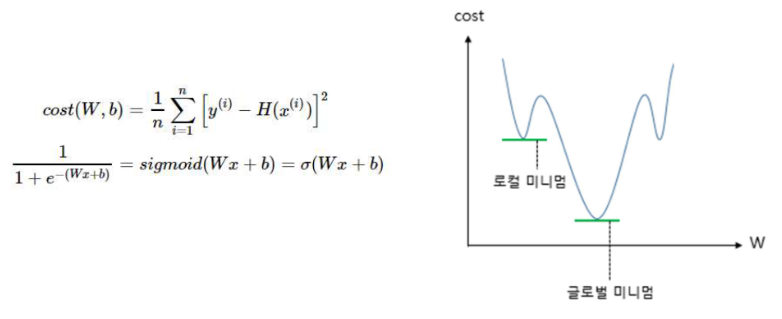
로지스틱 회귀는 비용 함수로 평균 제곱 오차를 사용하지 않음
-
비용 함수로 평균 제곱 오차를 사용할 경우, 아래와 유사한 그래프를 얻음
-
로지스틱 회귀는 비용 함수로 크로스 엔트로피 함수를 사용

-
선형 회귀의 회귀 문제에 푸는 알고리즘으로 예측값이 연속적인 값
-
로지스틱 회귀는 이진 분류 문제에 후는 알고리즘으로 예측값은 1 또는 0
실습
Keras - 선형 회귀
# 필요한 패키지 import
import numpy as np
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
# 데이터 전처리
xs = np.array([-1.0, 0.0, 1,0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([5.0, 6.0, 7,0, 8.0, 9.0, 10.0], dtype=float)
# 모델의 정의 (modeling)
model = Sequential()
# Dense의 첫번째 인자는 항상 출력의 차원을 의미한다.
model.add(Dense(1, input_dim=1, activation='linear'))
# 모델의 생성 (complie)
model.compile(optimizer='sgd', loss='mse')
# 학습 (fit)
model.fit(xs, ys, epochs=1200, verbose=0) # epochs는 전체 샘플에 대한 Weight와 Bias 업데이트 횟수
# 검증
# 16.000046
model.predict(np.array([[10.0]]))
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 54ms/step
array([[18.602985]], dtype=float32)
Keras - 로지스틱 회귀
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
# X의 입력이 10부터 y의 출력이 1이 되도록 설계된 데이터
X = np.array([-50, -40, -30, -20, -10, -5, 0, 5, 10, 20, 30, 40, 50])
y = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
model = Sequential()
# Dense의 첫번째 인자는 항상 출력의 차원을 의미
# Activation function은 항상 출력값이 적용할 함수를 의미
model.add(Dense(1, input_dim=1, activation='sigmoid'))
# sdg는 경사하강법을 의미, lr 은 learning rate의 값
sgd = optimizers.SGD(learning_rate=0.01)
# 이진 분류를 위해 activation function으로 sigmoid 함수를 사용한다면
# loss는 binary_crossentropy를 사용
model.compile(optimizer=sgd, loss="binary_crossentropy", metrics=['binary_accuracy'])
model.fit(X, y, batch_size=1, epochs=200, shuffle=False)
.
.
.
model.predict(np.array([[-10]]))
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 52ms/step
array([[0.0077197]], dtype=float32)
model.predict(np.array([[10]]))
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 37ms/step
array([[0.82803017]], dtype=float32)
keras - 3차원 벡터 입력값
ex) 중간, 기말, 가산점수로 부터 최종 성적 예측하기
# 입력이 스칼라가 아니라 3차원 벡터인 경우, ex) 중간, 기말, 가산점수로 부터 최종성적 예측하기
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
# 입력 벡터의 차원은 3, 즉 input_dim = 3
X = np.array([[70, 85, 11], [71, 89, 18], [50, 80, 20], [99, 20, 10], [50, 10, 10]])
# 출력 벡터의 차원은 1, output_dim = 1
y = np.array([[73], [82], [72], [57], [34]]) # 최종 성적
model = Sequential()
model.add(Dense(1, input_dim=3, activation="linear"))
sgd = optimizers.SGD(learning_rate=0.00001)
model.compile(optimizer=sgd, loss="mse", metrics=['mse'])
model.fit(X, y, batch_size=1, epochs=500, shuffle=False)
.
.
.
model.predict(np.array([[10, 50, 20]]))
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
array([[40.59846]], dtype=float32)Keras - 입력값이 2차원 벡터
# 입력이 2차원 벡터
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 1])
model = Sequential()
model.add(Dense(1, input_dim=2, activation='sigmoid'))
sgd = optimizers.SGD(learning_rate=0.01)
model.compile(optimizer=sgd, loss="binary_crossentropy", metrics=['binary_accuracy'])
model.fit(X, y, batch_size=1, epochs=800, shuffle=False)
.
.
.
model.predict(np.array([[10, 50]]))
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 53ms/step
array([[1.]], dtype=float32)https://colab.research.google.com/drive/1dx_Ej7xFsOAFF1ujY1fhLEdjI6xCIdUf?usp=sharing
이진 분류와 다중 클래스 분류
- 두 개의 선택지 중에서 정답을 고르는 문제 -> 이진 분류 문제 (Binary Classfication)
- 세 개 이상의 선택지 중에서 정답을 고르는 문제 -> 다중 클래스 분류 문제 (Multiclass Classification)
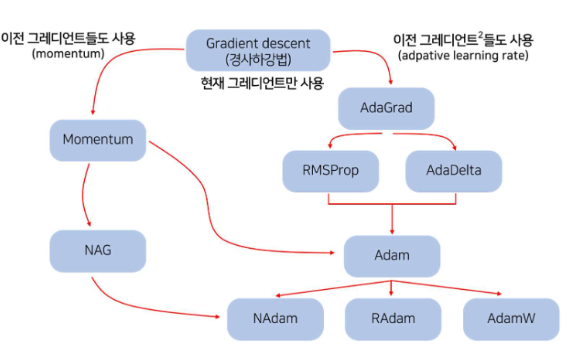
경사하강법(Gradient Descent) 기반 optimizer의 발전