k-NN 알고리즘
(k-최근접 알고리즘)
데이터로부터 거리가 가까운 'k'개의 다른 데이트의 레이블을 참조하여(평균을 내거나 다수결을 내서) 분류하는 알고리즘.
(이웃을 알면 자기자신을 알 수 있다)
-
KNN에서 중요한 파라미터는 'k=이웃의 수'로 너무 작은 경우에는 overfitting이 일어날 수 있고, 너무 큰 k를 설정할 경우에는 underfitting이 일어날 수 있다.
-
최적의 K는 데이터마다 모두 다르기 때문에 greedy approach를 활용하는 것이 일반적인 결정 방법 (같은 조건 하에 K 파라미터만 바꿔서 검정 오차율 및 정확도를 산출하여 결정하는 방법 활용)
데이터 포인트 간의 거리 측정 방법에 따라 결과가 달라짐
1) 유클리드 거리 (Euclidean Distance): 가장 일반적인 직선 거리
- 두 점 사이를 직선으로 잰 거리
- 피타고라스 정리 기반
2) 맨하탄 거리 (Manhattan Distance): 격자(블록) 형태로 이동하는 거리
-
유클리드 기하학의 거리 공간을 좌표에 표시된 두 점 사이의 거리(절댓값)의 차이로 산출
-
distritubtion 상의 거리를 반영하는 지표
- 좌표별 차이의 절댓값을 더한 거리
- 가로 + 세로 이동만 가능 (택시 이동 느낌)
3) 마할라노비스 거리 (Mahalanobis Distance): 데이터 분포(분산, 공분산)를 고려한 거리
- : 공분산 행렬
- 변수 간 스케일과 상관관계를 반영
k-NN 알고리즘의 특징
-
학습과정은 매우 단순하지만 복잡한 학습 과정을 거치는 모델보다 더 좋은 분류 예측 성능을 보이기도 함
-
다수의 data point를 기반으로 학습하므로 outlier에 민감하지 않다는 장점이 있음
-
파라미터 k가 데이터에 따라 그 최적의 값이 다르기 때문에 적절한 선택 과정이 쉽ㅈ지 않음
-
모든 train 데이터 사이의 거리를 측정해야 하기 때문에 계산에 대한 computing cost가 많이 듦
-
1-KNN(가장 가까운 데이터 1개를 기준으로 예측하는 모델) 의 검정 오차율은 베이즈 검정(최소 오류율) 오차율의 2배보다 항상 낮다 (어느정도 분류 예측 성능을 항상 보장 가능)
-
K-NN 학습 시 이웃에 대한 거리가 클수록 local density가 낮고 이는 곧 outlier일 가능성이 높다고 판단할 수 있음
결정트리 알고리즘
- Tree 구조를 가진 알고리즘
- 데이터를 분석하여 데이터 사이의 패턴을 예측 가능한 규칙들의 조합으로 나타남
- sample이 가장 섞이지 않은 상태로 완전히 분류 되는 것, 즉 엔트로피를 낮추도록 만드는 것이 기본 아아디어
결정트리 알고리즘의 종류
1) CART(Classification and Regression Trees)
- 분류 및 회귀 문제 모두에 사용가능, 이진 트리 구조 사용, 각 분기점에서 최적의 분할을 찾기 위해 지니 불순도 혹은 평균 제곱 오차를 최소화하는 기준을 사용
2) ID3(Iterative Dichotomiser 3): 정보 이득을 기분으로 하는 분류 문제, 주로 범주형 변수를 다루는 데 적합
3) C4.5 와 C5.0: ID3의 후속 알고리즘으로 연속 변수 처리, 가지치기, 누락된 값 처리 등에서 개선된 기능 제공
Linked List
연결리스트
데이터를 연속된 메모리 공간에 저장하지 않고, 각 데이터가 다음 데이터의 위치를 가리키는 형태로 구성된 선형 자료 구조
indexing으로 원소에 쉽게 접근할 수 있지만 원소를 추가하거나 삭제하려면 연속한 메모리 공간을 확보하고 원소를 이동시켜야 하므로 시간이 걸린다.
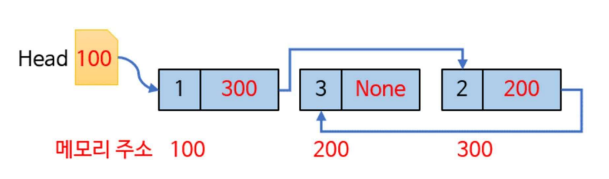
-
동적크기 - 배열과 달리 크기가 고정되어 있지 않아, 노드를 추가하거나 삭제하려 크기를 조절할 수 있음
-
삽입과 삭제가 쉬움 - 연결 리스트에서는 링크만 변경하면 되므로 효율적
-
메모리 효율성 - 배열은 미리 공간을 할당하지만 연결 리스트는 필요한 만큼만 메모리를 할당
Stack
후입선출(Last In First Out, LIFO)의 원칙에 따라 데이터를 관리하는 자료구조
가장 마지막에 쌓은 데이터를 가장 먼저 꺼내 사용하는 방식
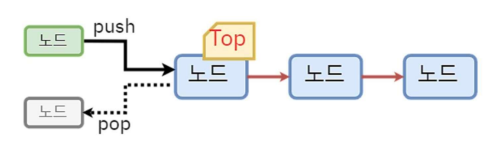
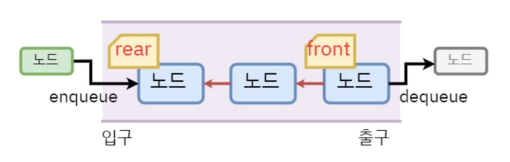
Queue
순서대로 처리하는 것.
스택은 한 쪽이 막힌 상자에 자료를 차곡차곡 쌓아놓고 위에서부터 꺼내는 것이라면, 큐는 입구와 출구가 따로 있는 통로로서 한 쪽에서 밀어 넣으면 반대편으로 나오는 것 (즉 순서대로 나온다)
실습 코드
