Text Classification 이란
- 텍스트 분류 (Text Classification) 이란 주어진 텍스트가 이미 정의된 카테고리 중 어디로 분류되어야 하는지를 예측하는 작업
- 자연어 처리 작업 중 가장 수요가 높으면서도 기본적인 작업
예)
언론사의 뉴스들을 자동으로 IT, 정치, 문화 등의 카테고리로 분류
스팸 메일 분류기
사용자가 남긴 리뷰로부터 긍정인지 부정인지 감성 분류
챗봇이 사용자가 입력한 질의로부터 '환불', '주문', '건의' 등인지 분류하고 대응
<기초적인 NLP 과정>
텍스트 -> 벡터화 (TF-IDF / Embedding) -> MLP -> 출력층 (binary or multi-class)
인공 신경망을 이용한 텍스트 분류 과정

분류의 종류
1) 이진 분류 (Binary Classification) - 출력값이 스칼라 값(sigmoid) 또는 2차원 벡터값(softmax)
2) 다중 클래스 분류 (multiclass classfication) - 출력값이 다중클래스 분류라면 클래스 개수 N차원 벡터 (softmax)
- sigmoid, softmax는 출력층의 활성화 함수
MLP (multilayer perceptron) 를 이용한 Text Classification
-
MLP외에도 다른 모델도 사용 가능하나, 여기에서는 MLP를 가지고 설명
-
각각의 문서를 고정 길이를 가지는 벡터로 변환한 다음에 Vocabulary size를 입력층의 뉴런 수로 가지는 다층 퍼셉트론에 문서 벡터를 입력으로 사용

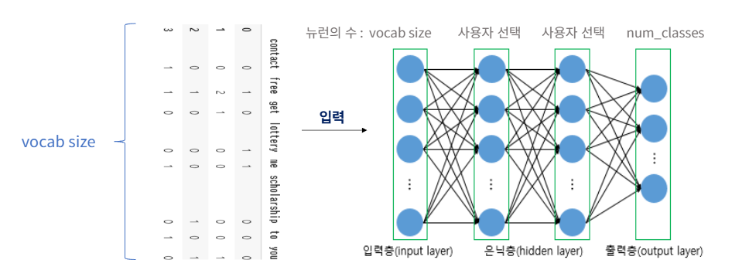
은닉층
- Multilayer Perceptron
- 입력 벡터를 조합해서 패턴을 학습하는 단계
- 중요한 단어 조합 찾기
- 비선형 관계 학습
Perceptron
가장 기본적인 이진 분류 모델
-
-
-
선형 분리 가능 데이터만 처리 가능함 (XOR 문제 실패 등)
-
그래서 mulilayer perceptron이 나옴
Multilayer Perceptron
- 퍼셉트론을 여러 층 쌓음
- 비선형 문제 해결 가능
실습

오랜시간 망설였던 코딩을 다시 해보려고 노력하고 있는 사람