K-평균 알고리즘(K-means Algorithm)
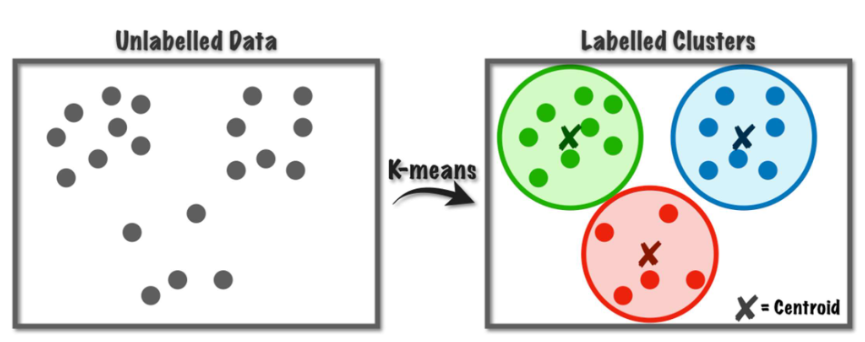
unlabelled Data -> Labelled Clusters
각 데이터의 cluster의 center를 표시하는 것 (Cluster Centroids)
- 처음에 중심점(k개)을 랜덤으로 찍는다.
- 각 데이터가 가장 가까운 중심에 속하게 한다.
- 각 그룹의 평균 위치로 중심을 다시 이동.
위의 과정을 여번 반복하면 그룹이 점점 안정적으로 나뉨.
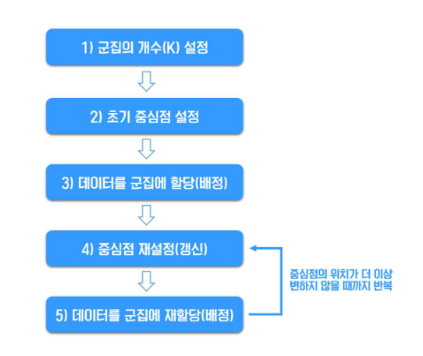
Pseudo-code로 작성해본 K-means Algorithm

Optimization Objective (최적화 목표)
K-means Objective Function
기호:
: i번째 데이터
: k번째 클러스터의 중심 (centroid)
: i번째 데이터가 속한 클러스터 번호
: i번째 데이터가 속한 클러스터의 중심
수식:
데이터와 중심 사이 거리 (오차)를 모든 데이터에 대해 더한 뒤 평균을 냄
K-means는 이 값(데이터와 중심 사이의 거리)을 최소화 하는 것
-> 데이터는 가까운 중심으로, 중심은 평균으로 보내는 것을 반복해서 거리 총합을 줄인다.
효과적인 초기화 방법
Random Initialization (무작위 초기화)
무작위 초기화를 하는 경우에는 나쁜 경우 local optima에 빠질 수 있다.
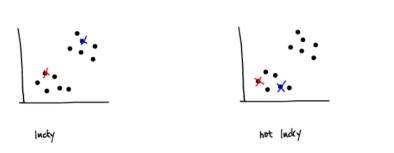
이런 경우에는 random initialization을 여러번 하는 것으로 해결한다.
-> 그러므로 k-means 는 한 번 실행하는 것이 아니고, 여러번 실행하여 가장 작은 J 값을 가진 clustering을 선택하는 것
from sklearn.cluster import KMeans
kmeans = KMeans(
n_clusters=3,
n_init=10 # 10번 실행
)
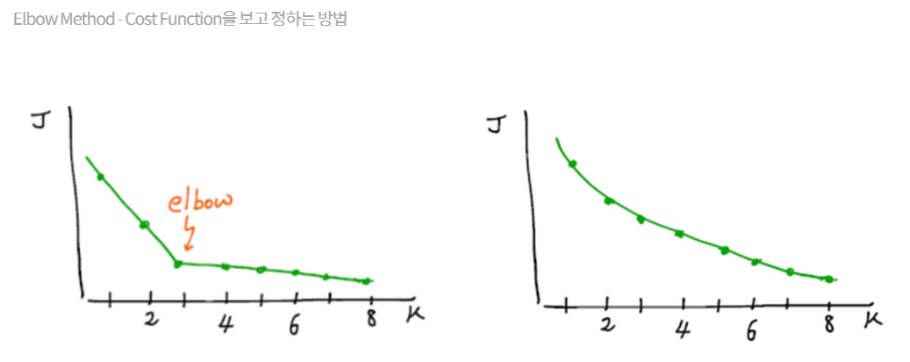
kmeans.fit(X)Cluster 수의 결정
Cluster 갯수는 주로 사람이 직접 데이터 분포를 보고 수동으로 결정, 사실 어떤 K가 적절한지에 대한 명확한 답이 없기도 하다.
K-means 알고리즘 실습

오랜시간 망설였던 코딩을 다시 해보려고 노력하고 있는 사람