Neural Networks의 배경
Linear regression 이나 logistic regression으로 복잡한 데이터를 다루는 데에는 한계가 있음, 다른 모양으로 분포하는 데이터에는 non-linear decision boundary가 필요
예)
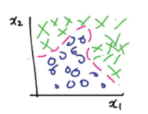
Logistic regression을 이용해서 non-linear boundary 를 만들 수 있긴 하지만 feature 수가 늘어나면 날수록 경우가 수가 많아지기 때문에 feature 기하급수적으로 매우 많아질 수 있다.
이렇게 되면 연산량도 많아질 뿐만 아니라 overfitting의 가능성이 높아진다.
Neural net은 우리의 두뇌가 동작하는 방식을 제한적으로 모방하는 방식.
Neuron Model: Logistic Unit
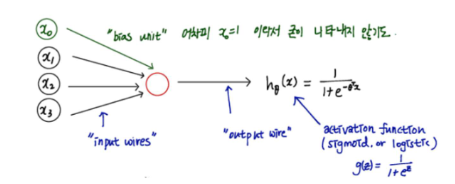
- single neuron에 관한 모델
- Dendrite은 input feature x1, ....,
- axon은 hypothesis function의 output
- 은 'bias unit'이라고 불리며 항상 1의 값을 가지므로 굳이 나타내지 않기도 함
- NN은 classification과 마찬가지로 logistic function을 사용하는데, sigmoid (logistic) activation function 이라고 부르기도 한다.
- 는 weights 이라고 하기도 한다.
Neural Network
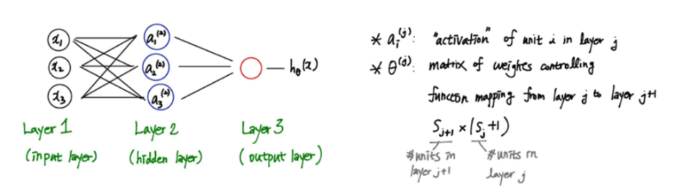
- : "activation" of unit i in layer j
- : matrix of weights controlling funciton mapping from layer j to layer j+1
- input 레이어와 output 레이어 중간의 레이어들: hidden layers
간단한 예제로 이해하기
입력 1개 -> 출력 1개 (로지스틱 회귀와 동일한 구조)
- 입력: x = 2
- 정답: y = 1
- 초기 가중치: w = 0.5
- bias: b = 0
1. Forward (예측)
1) 선형 계산
z = wx + b = 0.5 * 2 + 0 = 1
2) sigmoid 적용
= σ(1) ≈ 0.73
모델 예측 0.73 (확률)
처음 Hidden layer 에서 선형 계산을 쓰는 이유
-> 입력 특징들을 의미있는 방식으로 섞기 위해서
예시) 입력이 2개라고 할 때
-
키:
-
몸무게:
-
z = + b
두 특징을 적절한 비율로 섞어서 새로운 특징 만들기
이렇게 하는 이유는:
- 입력들 간의 관계를 반영한 새로운 값 생성 (feature mixing)
- 중요도 반영 가능 (weight)
- 수학적으로 다루기 쉬움 (미분 쉽고, 계산이 빠르며 안정적)
선형 이후에는 activation이 나옴
- 입력 -> 선형(wx+b) -> 비선형 activation
즉 선형 단계는 "재료를 섞는 것이고", activation 은 "비선형 변형" 이다.
그냥 선형만 있는 경우에는 결국 선형이 될 뿐, Neural network이 아님
2) Loss 계산 (얼마나 틀렸나)
정답: 1
예측: 0.73
오차 ≈ (1-0.73) = 0.27
-> 아직 부족함 (더 1에 가까워져야 함)
3) Backpropagation
-
w를 늘려야 할까 줄여야 할까
-
x = 2 (양수) 이고 예측이 0.73, 목표는 1
그래서 w를 키워서 z가 커지도록 해야함 -> sigmoid 결과도 커짐
Gradient Descent 적용
w_new = w + (조금 증가)
예) 기존 w = 0.5 -> 업데이트 후 w ≈ 0.6
4) 다시 Forward
z = 0.6 * 2 = 1.2
= σ(1.2) ≈ 0.77
-> 더 1에 가까워짐
5) 위의 과정을 계속 반복
예측 -> 틀림 -> 수정 -> 예측 -> 수정 -> ...
결국: -> 1
Neural Network 이해하기
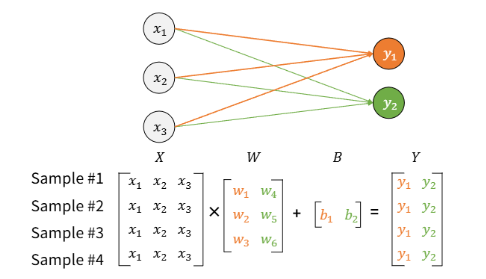
파라미터의 개수 알아내기
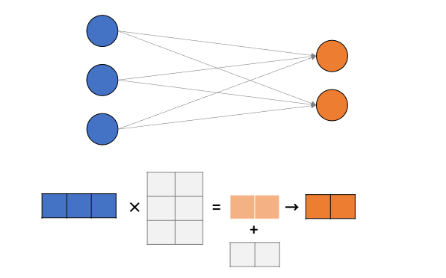
-
Input(X) = 3개
-
Output(y) = 2개
-
(3 x 2) + 2 = 8개
-
3개의 노드 x 받는 노드 수 + (bais 수) = 8개
-
bais수는 결국 받는 노드 수와 같음
Logistic Regression
-
Logistic Regression은 구조적으로는 가장 단순한 신경망으로 볼 수 있음.
-
Logistic Regression의 계산 구조가 신경망의 한 개 뉴런과 거의 똑같음.
-
머신러닝 관점 -> Logistic Regression은 전통적인 선형 분류 모델, 신경망이라고 부르지 않음
-
딥러닝 관점 -> 입력층 -> 출력층만 있는 히든 레이어 없는 신경망, 1-layer nueral network 또는 single neuron model로 볼 수 있음
Logistic Regression vs Neural Network
Logistic Regression
- hidden layer 없음
- output node 1개
- sigmoid 사용
Neural Network
- hidden layer 있음
- node 여러개
- 비선형 패턴 더 잘 학습
