머신 러닝 - confusion matrix, IQR, skewed data, kurtosis, Label encoding, One hot encoding, Log Loss
구름을잡아라
Confusion matrix
3-class classification
행렬
표로 보면
| 실제 / 예측 | 예측 0 | 예측 1 | 예측 2 |
|---|---|---|---|
| 실제 0 | 164 | 156 | 330 |
| 실제 1 | 174 | 521 | 567 |
| 실제 2 | 379 | 582 | 2419 |
첫번째 줄로 자세히 의미를 알아보면...
실제로 class 0인 샘플 650개가 어떻게 예측되었는지를 보여줌
대각선의 164, 521, 2419가 모델이 맞춘 수치로 보통 confusion matrix에서는 대각선의 값이 클 수록 좋다.
- 그러므로 이 모델은 클래스 2는 잘 맞추지만 클래스 1과 2는 잘 맞추지 못하고, 클래스 1을 가장 잘 맞추지 못한다.
- 모델이 1을 2로 가장 많이 착각
- 모델이 1도 2로 많이 착각함
-> 데이터가 불균형이거나 feature 구분력이 부족할 가능성이 많음
먼저 첫밴째 수치인 164는:
실제로 클래스 0이고 예측도 0으로 - 예측이 잘 된 수가 164개임을 보여준다.
두번째 수치인 156은:
실제로는 클래스 0인데 예측은 클래스 1로 되어 잘못된 예측이 된다.
세번째 수치인 330은:
실제로는 클래스 0인데 예측은 클래스 2로 나온 수로 잘못된 예측이다.
IQR
Interquartile Range의 약자로 사분위 범위. 데이터가 중앙의 어느 구간에 얼마나 펴져 있는지를 보는 값
Q1 (1사분위수): 아래 25% 지점 - 아래쪽 절반의 중앙값
Q3 (3사분위수): 아래 75% 지점 - 위쪽 절반의 중앙값
IQR = Q3 - Q1
중간 50%만 보기 때문에 이상치에 강하다.
IQR계산 예시
데이터
1, 2, 3, 4, 5, 6, 7, 8, 9
중앙값(Q2)
Q2 = 5
중앙값이 5 이므로 5를 기준으로하면:
아래 절반 - 1,2,3,4
Q1 = (2+3)/2 = 2.5
-> 이 데이터에서 중앙값을 찾아야하는데 데이터가 짝수이기 때문에 가운데 두개를 고른뒤에 평균을 내는 방법을 씀
위 절반 - 6, 7, 8, 9
Q3 = (7+8)/2 = 7.5
그래서 IQR = 7.5-2.5 = 5
-> 가운데 50% 데이터는 길이 5 범위 안에 있다는 뜻
- IQR이 작다: 데이터가 중앙에 빽빽하게 몰려 있음
- IQR이 크다: 데이터가 중앙에서 널리 펴져 있음
IQR은 데이터의 산포도를 보는 지표이다.
이상치 찾기
Lower Bound = Q1 - 1.5 x IQR
Upper Bound = Q3 + 1.5 x IQR
이 범위를 벗어나면 보통 이상치로 봄
왜 1.5를 곱하나? John Tukey (박스플롯을 만든 사람) 가 제안한 실용적 기준 (경험적 기준)
IQR은 Boxplot의 박스를 차지 하는 범위. 이 박스 밖의 값은 이상치(outliers)
1.5가 항상 옳은 절대 법칙은 아니지만 꽤 합리적인 값
힛맵(heatmap) 그래프
숫자의 크기를 "색깔의 진하기"로 표현하는 표 형태의 시각화
숫자를 표로 보는 대신에 어디가 크고 어디가 작은지를 한눈에 볼 수 있음
힛맵을 사용하는 경우:
-
Correlation Matrix (상관계수 행렬)
어떤 변수끼리 상관이 높은지 보기위해 -
Confusion Matrix 시각화
-
시간/패턴 분석
- 요일 x 시간대 방문수
- 월 x 상품 판매량
- 사용자 x 행동 빈도
Skewed Data
1) Right-skewed (양의 왜곡)
오른쪽 꼬리가 긴 분포
예)
연봉, 집값, 소비금액, 병원비, 카드 사용액
대부분의 사람은 중간 수준인데 극단적으로 큰 값이 소수 존재해서 오른쪽 꼬리가 길어짐
2) Left-skewed (음의 왜도)
왼쪽 꼬리가 긴 분포
예)
시험 점수(시험이 쉬웠을 때), 만족도 점수(대부분 높고 일부만 낮을 때)
왜 skewed 데이터가 문제일까?
예를 들어 소득 데이터가 있다고 할 때
income = [2100, 2300, 2500, 2700, 3000, 3200, 3500, 4000, 12000]평균을 구하게 되면 높게 나오지만 실제로는 2000~4000 사이에 몰려있음
- 평균이 왜곡될 수 있음
- 중앙값(median)이 더 현실적인 대표값일 수 있음
skewed 데이터인지 확인하는 방법
- 히스토그램을 그려서 확인
fig = px.histogram(df, x='income', nbins=10)
fig.show()- boxplot 보기 - 이상치와 치우침 확인하기 좋음
fig = px.box(df, y='income')
fig.show()- skeweness 수치 확인
Pandas로 왜도 수치화 가능
df['income'].skew()대략
- 0 근처: 대칭
- /> 0: 오른쪽 치우침
- < 0: 왼쪽 치우침
skewed 데이터를 다루는 방법
1) 로그 변환 (log transform)
- 값이 오른쪽으로 길게 치우친 경우
- 큰 값들이 너무 튀는 경우
- 소득, 금액, 횟수, 거래량 같은 데이터
큰 값을 압축해서 분포를 덜 치우치게 만듦
예) 100 -> log 후 조금 증가
10000 -> log 후 훨씬 압축됨
하지만 log(0)은 불가능 하기 때문에 log 대신 log1p.
log1p 는 log(1 + x)와 같아서 0도 안전하게 처리 가능
df['income_log'] = np.log1p(df['income'])2) 제곱근 변환 (sqrt transform)
- 오른쪽 skew가 있긴 한데 로그까지는 과할 때
- count 데이터 (횟수형 데이터)
예) 방문 횟수, 클릭 수, 구매 횟수
3) Box-Cox / Yeo-Johnson 변환
- Box-Cox: 양수 데이터만 가능, 데이터에 맞는 적절한 강도를 찾음
from scipy.stats import boxcox
df['income_boxcox'], lam = boxcox(df['income'])- Yeo-Johnson: 0, 음수도 처리 가능
from sklearn.preprocessing import PowerTransformer
pt = PowerTransformer(method='yeo-johnson')
df['income_yj'] = pt.fit_transform(df[['income']])이 두 가지 방법은 로그/제곱근보다 더 체계적으로 변환하고 싶을때, 모델 성능을 높이기 위해 분포를 정리하고 싶을 때 사용
4) 이상치(outlier) 처리
skew가 심한 이유가 진짜 분포의 특성인지, 아니면 이상치 몇 개 때문인지 구분
income = [2100, 2300, 2500, 2700, 3000, 3200, 3500, 4000, 1200000]여기서 1200000는 실제 데이터일 수도 있지만 입력 오류일 수도 있음
이상치 처리 방법 - 1
제거
df = df[df['income'] < 100000]이상치 처리 방법 - 2
Cap (winsorizing)
너무 큰 값을 상한선으로 잘라줌
upper = df['income'].quantile(0.99)
df['income_capped'] = df['income'].clip(upper=upper)
income income_log income_capped
0 2100 7.650169 2100
1 2300 7.741099 2300
2 2500 7.824446 2500
3 2700 7.901377 2700
4 3000 8.006701 3000
5 3200 8.071219 3200
6 3500 8.160804 3500
7 4000 8.294300 4000
8 12000 9.392745 113605) Robust scaling
skewed 데이터에서 일반 표준화(StandardScaler)는 이상치 영향이 클 수 있음
StandardScaler
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['income_scaled'] = scaler.fit_transform(df[['income']])평균/표준편차 기반
RobustScaler
from sklearn.preprocessing import RobustScaler
rscaler = RobustScaler()
df['income_robust'] = rscaler.fit_transform(df[['income']])Median + IQR 기반 (skew/outlier에 더 강함)
6) 모델이 skew에 민감한지 확인하기
- 보통 더 신경 써야 하는 모델
Linear Regression
Logistic Regression
KNN
KMeans
SVM (거리 영향 큼)
PCA
Naive Bayes 일부 상황
이런 모델은:
거리
분산
선형 관계
분포 모양
에 영향을 받기 쉬워서 변환이 도움이 될 수 있음
- 상대적으로 덜 예민한 모델
Decision Tree
Random Forest
XGBoost
LightGBM
CatBoost
트리 기반 모델은 값의 "순서"와 "분할 기준"을 더 중요하게 보기 때문에 왜도에 덜 민감한 편
추천 skewed 데이터 처리 방법
상황1 - 오른쪽 꼬리가 긴 경우: np.log1p(), 필요하면 RobustScaler
상황2 - count 데이터: sqrt, log1p
상황3 - 이상치가 너무 심한 경우: clip, winsorize, 입력 오류 여부 확인, 로그 변환 병행
상황4 - 트리 모델을 쓰는 경우: 무조건 변환하지 말고, 변환 전/후 성능 비교
kurtosis (첨도)
예)
A = [48, 49, 50, 50, 51, 52, 50, 49, 51]
B = [10, 49, 50, 50, 51, 52, 50, 49, 100]둘 다 비슷하지만, B는 10와 100같은 극단값이 들어 있음
즉 B는:
꼬리가 더 두껍고, 이상치가 더 잘 나오고, kurtosis가 더 큼
kurtosis가 낮다
- 꼬리가 얇다
- 극단값이 잘 안 나옴
- 값들이 비교적 안정적으로 퍼져 있음
kurtosis가 높다
- 꼬리가 두껍다
- 극단값이 자주/강하게 나옴
- outlier 가능성이 큼
즉:
첨도가 높다 = 이상치에 더 민감한 분포
skewness와 어떻게 다른가
Skewness (왜도)
→ 어느 방향으로 치우쳤는가
오른쪽 꼬리 길다 → 양의 왜도
왼쪽 꼬리 길다 → 음의 왜도
즉, 비대칭성을 봄
Kurtosis (첨도)
→ 꼬리가 얼마나 두꺼운가
즉, 극단값의 강도/빈도를 봄
첨도의 기준 (해석)
Pandas나 SciPy에서 첨도를 구하면
보통 “정규분포를 기준으로 얼마나 더 tail이 두꺼운가”를 보여주는 경우가 많음
이것이 excess kurtosis
해석 기준 (대략적으로 - 절대기준 아님)
kurtosis ≈ 0
정규분포와 비슷
kurtosis > 0
꼬리가 더 두꺼움
outlier 가능성 큼
kurtosis < 0
꼬리가 얇음
극단값이 적음
print("Skewness:", train['income_total'].skew())
print("Kurtosis:", train['income_total'].kurt())둘 다 같이 보면 좋음
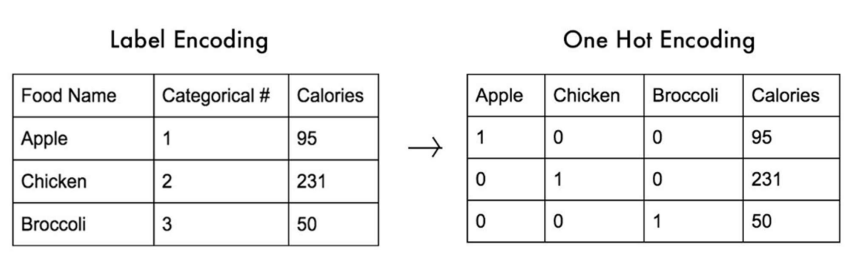
Label Encoding vs One Hot Encoding
범주형 데이터(categotical data)를 숫자로 바꾸는 방법
Label Encoding
- 각 카테고리에 숫자 하나씩 부여하는 방식
- 장점은 간단하고 빠른 점, 그리고 컬럼 수가 늘어나지 않음, 메모리 효율적
- 단점은 모델이 숫자를 보고 순서가 있다고 착각할 수 있음, 그러므로 순서없는 범주형 변수에 쓰면 위험할 수 있음
from sklearn.preprocessing import LabelEncoder
import pandas as pd
df = pd.DataFrame({
'Color': ['Red', 'Blue', 'Green', 'Blue']
})
le = LabelEncoder()
df['Color_encoded'] = le.fit_transform(df['Color'])
print(df)
Color Color_encoded
0 Red 2
1 Blue 0
2 Green 1
3 Blue 0One-Hot Encoding
- 카테고리마다 새 컬럼을 하나씩 만드는 방법
- 순서가 없다는 사실을 잘 보존
- 대부분의 머신러닝 모델에서 안전하게 사용 가능
- 해석이 쉬움
- 단점은 카테고리가 많으면 컬럼 수가 급 증가
- 메모리와 학습 시간이 늘 수 있음
import pandas as pd
df = pd.DataFrame({
'Color': ['Red', 'Blue', 'Green', 'Blue']
})
df_ohe = pd.get_dummies(df, columns=['Color'])
print(df_ohe)
Color_Blue Color_Green Color_Red
0 0 0 1
1 1 0 0
2 0 1 0
3 1 0 0
#sklearn
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
df = pd.DataFrame({
'Color': ['Red', 'Blue', 'Green', 'Blue']
})
ohe = OneHotEncoder(sparse_output=False)
encoded = ohe.fit_transform(df[['Color']])
encoded_df = pd.DataFrame(encoded, columns=ohe.get_feature_names_out(['Color']))
print(encoded_df)
적용 팁
1) 선형 모델 / 거리 기반 모델 - One-Hot Encoding
- Logistic Regression
- Linear Regression
- SVM
- KNN
2) 트리 기반 모델 - Label Encoding
- Decision Tree
- Random Forest
- XGBoost
- LightGBM
- CatBoost
정리)
순서 있음 → Label / Ordinal Encoding
순서 없음 + 카테고리 수 적음 → One-Hot Encoding
순서 없음 + 카테고리 수 많음 → 다른 방법 고려
Log loss란
모델이 예측한 확률이 얼마나 정답과 잘 맞는지를 보는 지표
- 정답인데 얼마나 자신 있게 맞췄는지
- 오답인데 얼마나 자신 있게 틀렸는지
까지 평가
- 틀린 것을 자신있게 예측하면 크게 벌점
왜 낮을수록 좋은가?
Log loss는 오차(error) 개념이라서 오차가 작을 수록 좋은 모델
Accuracy와의 차이
Accuracy는 최종적으로 맞췄는지만 보기 때문에 0.5 든 0.99든 둘 다 "맞음"으로 간주되나. Log Loss는 0.5와 0.99를 다르게 평가하여 0.99로 맞춘 모델을 더 좋게 봄
Log Loss가 중요한 경우
- 확률 자체가 중요한 문제일 경우 (예) 고객 이탈 확률, 클릭 확률 등)
- 분류 모델 비교
- 불균형 데이터에서 accuracy 만 믿기 힘들 때
